

在索引(Indexing)阶段,当某个域被设置为需要记录词向量(term vector)信息后,那么随后在flush阶段,该域对应的词向量将被写入到索引文件.tvd&&tvx&&tvm三个文件中。
图1:
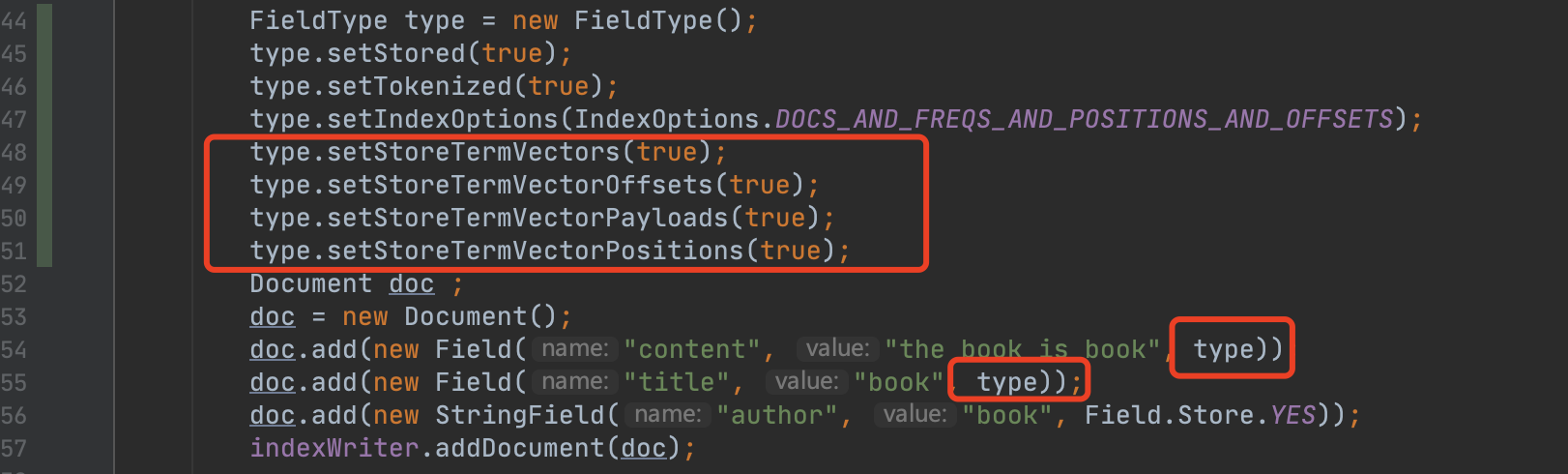
图1中,域名"content"跟"title"都被设置为需要记录词向量信息,而域名"author"则没有。
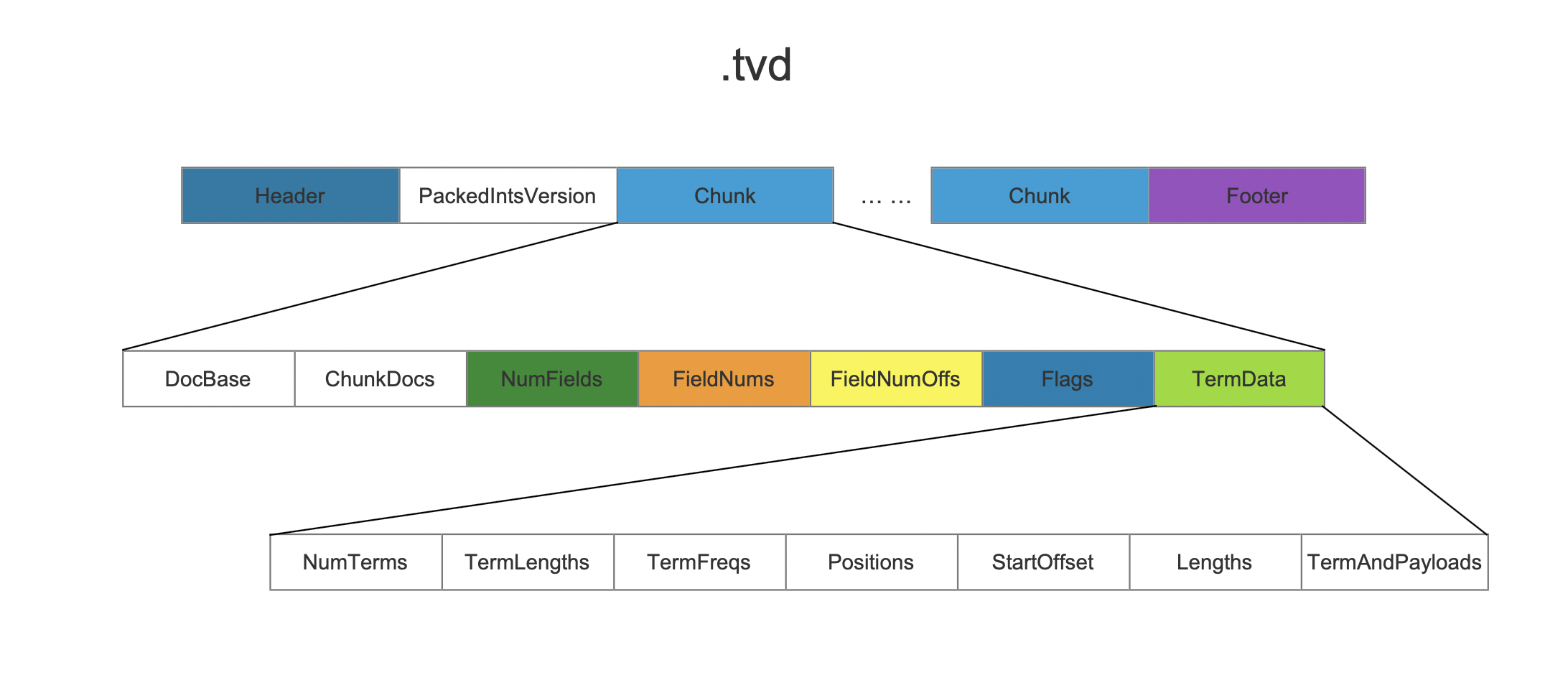
数据结构
索引文件.tvd
图2:
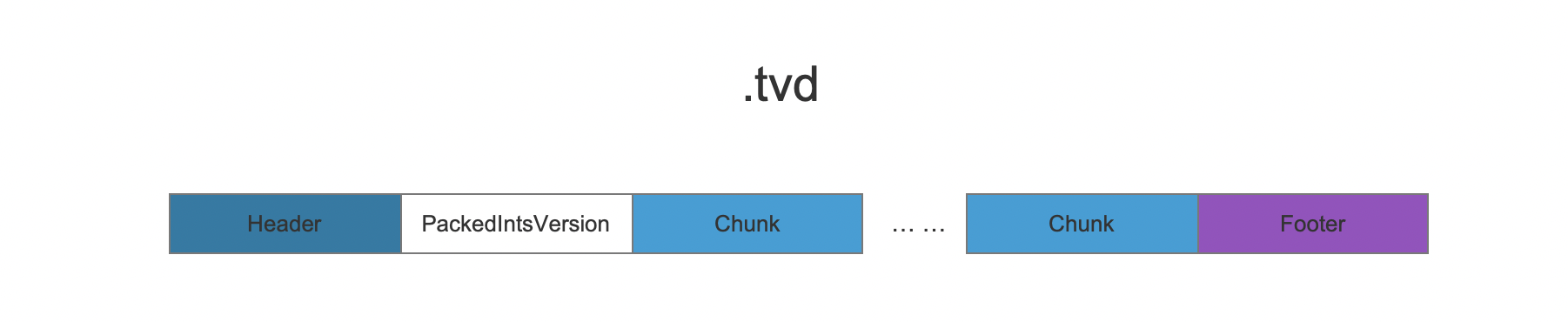
PackedIntsVersion
PackedIntsVersion描述了压缩使用的方式,当前版本中是VERSION_MONOTONIC_WITHOUT_ZIGZAG。
Chunk
图3:
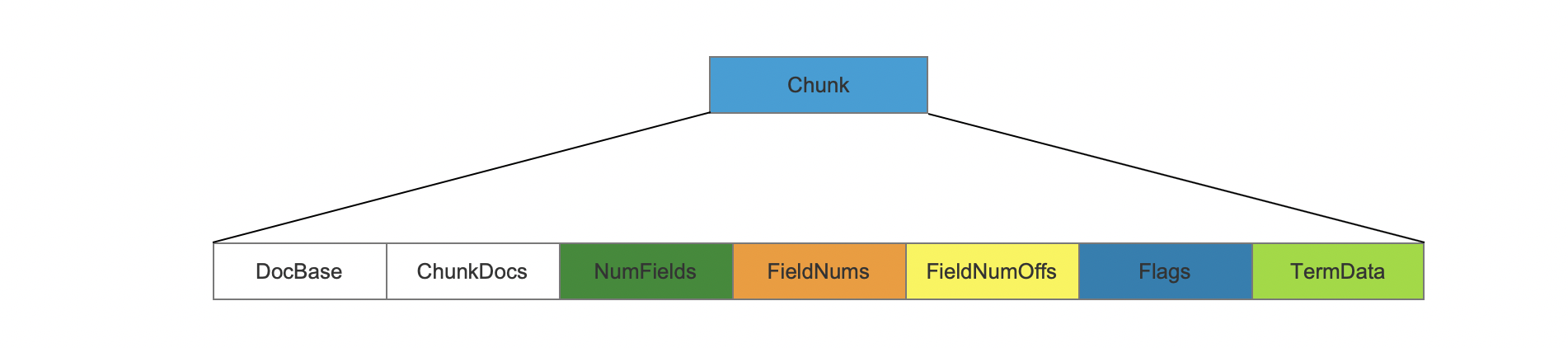
在索引阶段,每当处理128篇文档或者已经处理的域值的总长度达到4096,就生成一个chunk。
DocBase
该字段描述的是chunk中第一篇文档的文档号。
ChunkDocs
该字段描述的是Chunk中的文档数量。
NumFields
该字段描述的是Chunk中每篇文档中记录词向量的域的数量。例如图1中只有一篇文档,这篇文档中的就包含了2个记录词向量的域。
根据Chunk中包含的文档数量,NumFields字段的数据结构各不相同
Chunk中只包含一篇文档
图4:

如果图1所示,那么NumFields的值为2,并且不会使用压缩存储。
Chunk中包含多篇文档
图5:
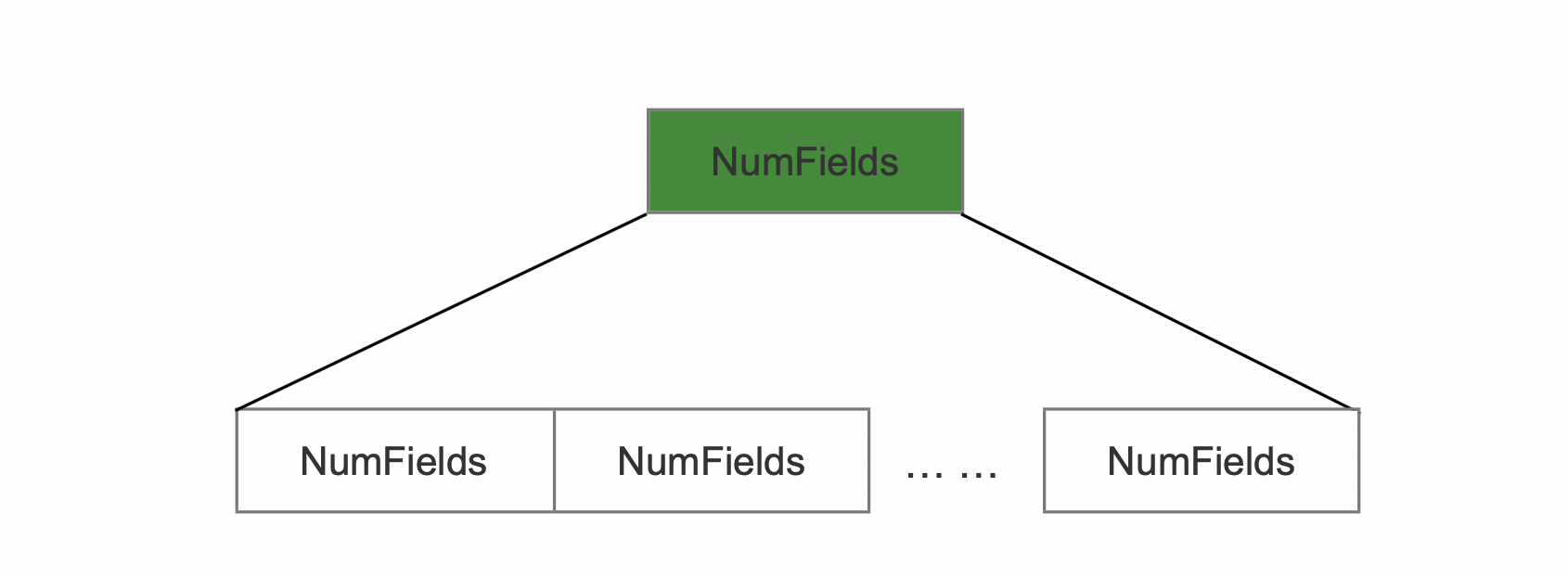
当包含多篇文档,那么需要记录每一篇文档中记录词向量的域的数量,然后使用PackedInts存储。
FieldNums
该字段描述的是Chunk中记录词向量的域的种类,根据域的编号来获得域的种类。
(域的种类 - 1) ≤ 7
图6:
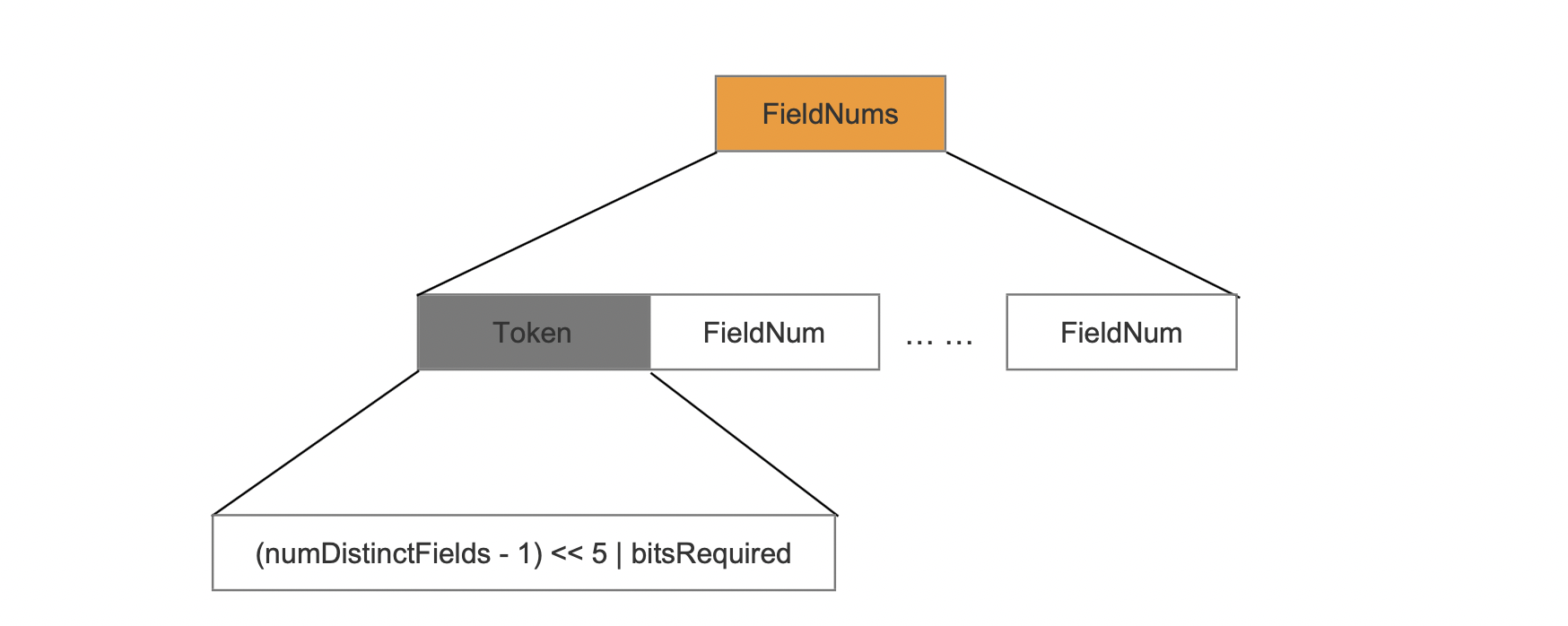
token
token是一个组合值,并且大小是一个字节:
- numDistinctFields:Chunk中记录词向量的域的种类
- bitsRequired:存储每个域的编号(因为使用了固定位数按位存储)需要的bit数量
- 左移5位描述了bitsRequired的值最多可以是31
- 由于一个字节的低五位被用来描述bitsRequired,所以还剩余3个bit可以用来表示numDistinctFields,所以numDistinctFields的值小于等于7时可以跟bitsRequired使用一个字节存储。
FieldNum
FieldNum即域的编号, 用PackedInts存储。
(域的种类 - 1) > 7
图7:
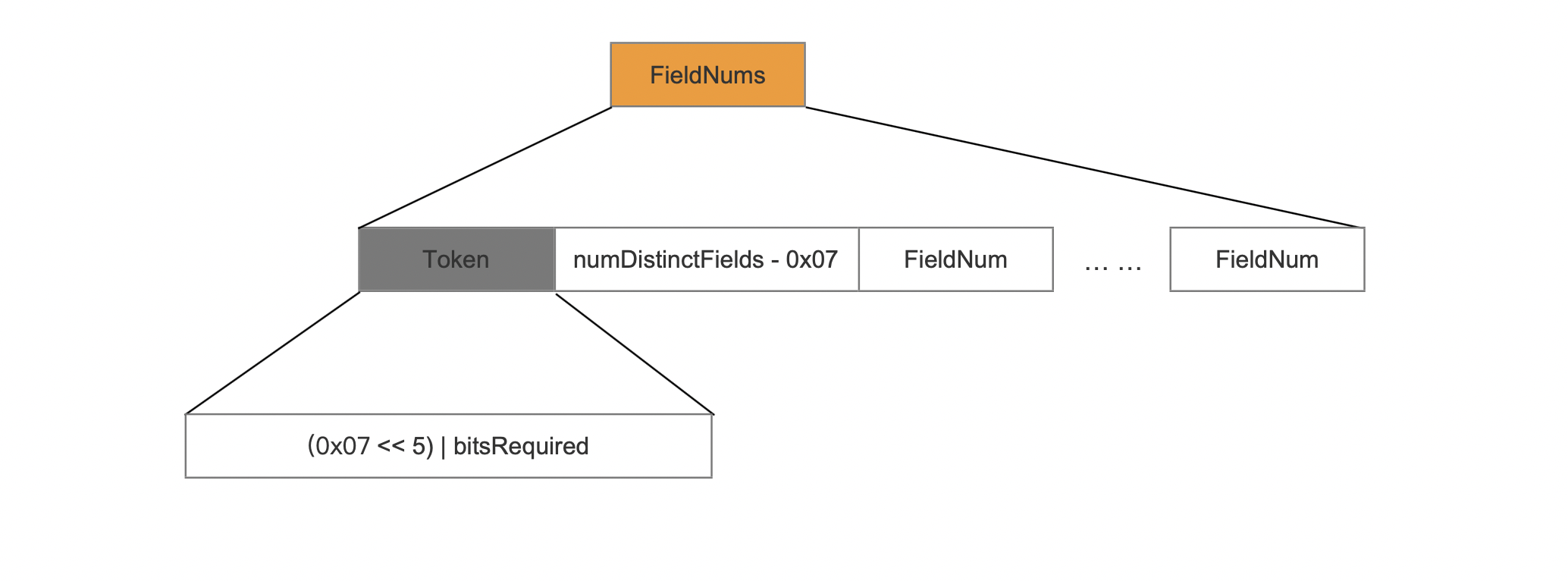
token
token是一个组合值,并且大小是一个字节:
- bitsRequired:存储每一个域的编号需要最少bit位个数
- 由于numDistinctFields的值大于7,那么在token的高三位用来描述numDistinctFields一部分值,即固定值7,低5位用来描述bitsRequired
- numDistinctFields - 0x07:存储剩余的差值,例如假设numDistinctFields的值为13,那么7存储在token中、6存储在当前字段
FieldNumOffs
图8:
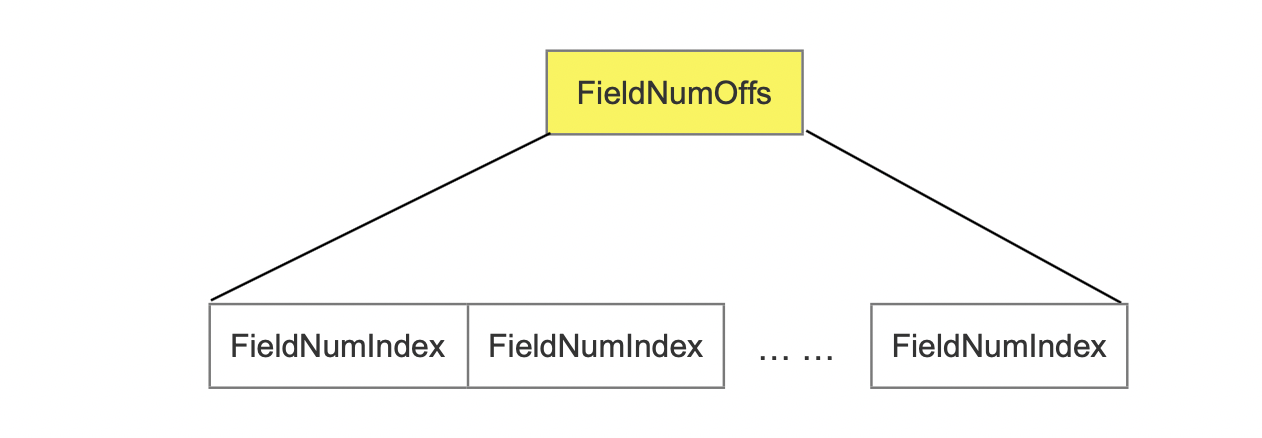
FieldNumOffs中存放了chunk中每一篇文档包含的所有域的编号的索引值FieldNumIndex,并且使用PackedInts存储。该索引其实就是fieldNums[ ]数组的下标值,fieldNums[ ]数组的数组元素是Chunk中的域的编号,数组长度是域的种类数。通过这种方式使得不直接存储域的编号,因为域的编号可能跨度很大,由于使用固定位数按位存储,每个域的编号占用的bit数量取决编号最大的,那会导致较大的存储空间,而存储下标值就缓解这个问题。
图9:

图9中有4个域的编号,如果直接存储域的编号,其中域的编号最大值为255,占用8个bit,故需要 8 *4 = 32个bit。若只存储索引值,那么需要 1 (0) + 1 (1) + 2 (2) + 2 (3) = 6个bit位。
Flags
Flags用来描述记录词向量的域具体记录哪些信息,这些信息包括:位置position、偏移offset、负载payload信息。flag的值可以是下面3个值的组合:
- 0x01:包含位置position信息
- 0x02:包含偏移offset信息
- 0x04:包含负载payload信息
比如说 flag = 3,二进制即0b00000011,即该域会记录位置跟偏移信息。
根据同一个域名在不同的文档中是否有相同的Flag分为不同的情况:
图10:
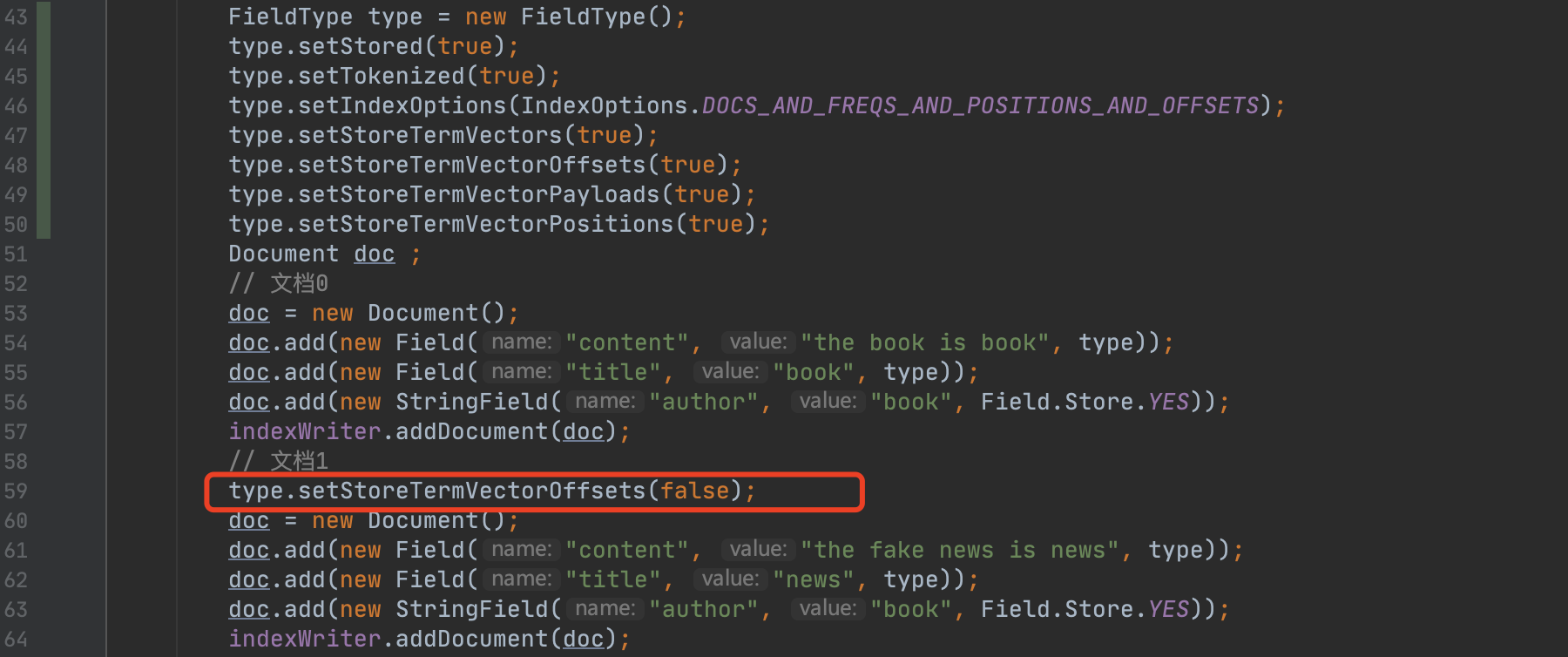
图10中,域名"content"、"title"在文档0中会记录位置position、偏移offset、负载payload信息,然而在文档1中只记录位置position、负载payload信息。那么这种情况就称为相同的域名有不相同的flag,反之如果所有记录词向量的域在所有文档中对应的flag都是相同的,那么这种情况称为相同的域名有相同的flag。
相同的域名有相同的flag
图11:
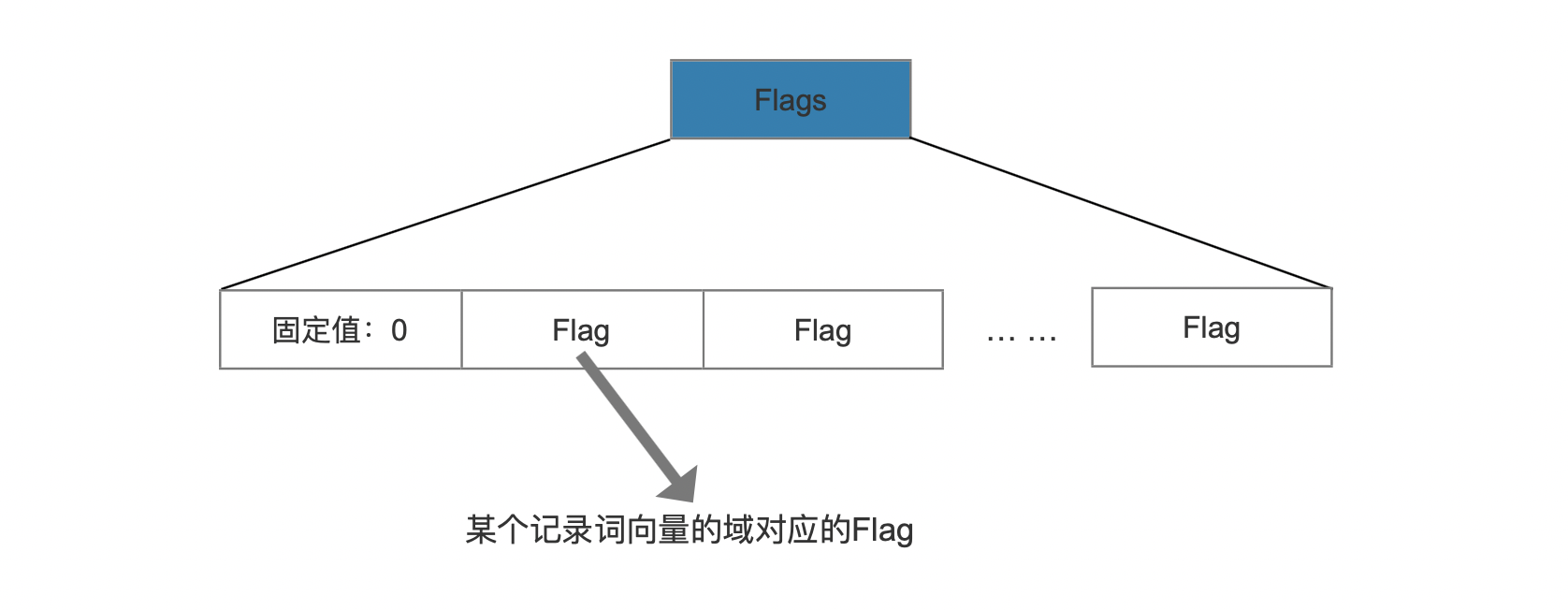
对于某个记录词向量的域名来说,无论它在哪个文档中都记录相同的flag信息,所以只要只要记录一次即可,并且用PackedInts存储,固定值0为标志位,在读取阶段用来区分Flags的不同数据结构。图11中每个flag字段对应一种域,即flag的数量等于记录词向量的域的种类数量。
相同的域名有不相同的flag
图12:
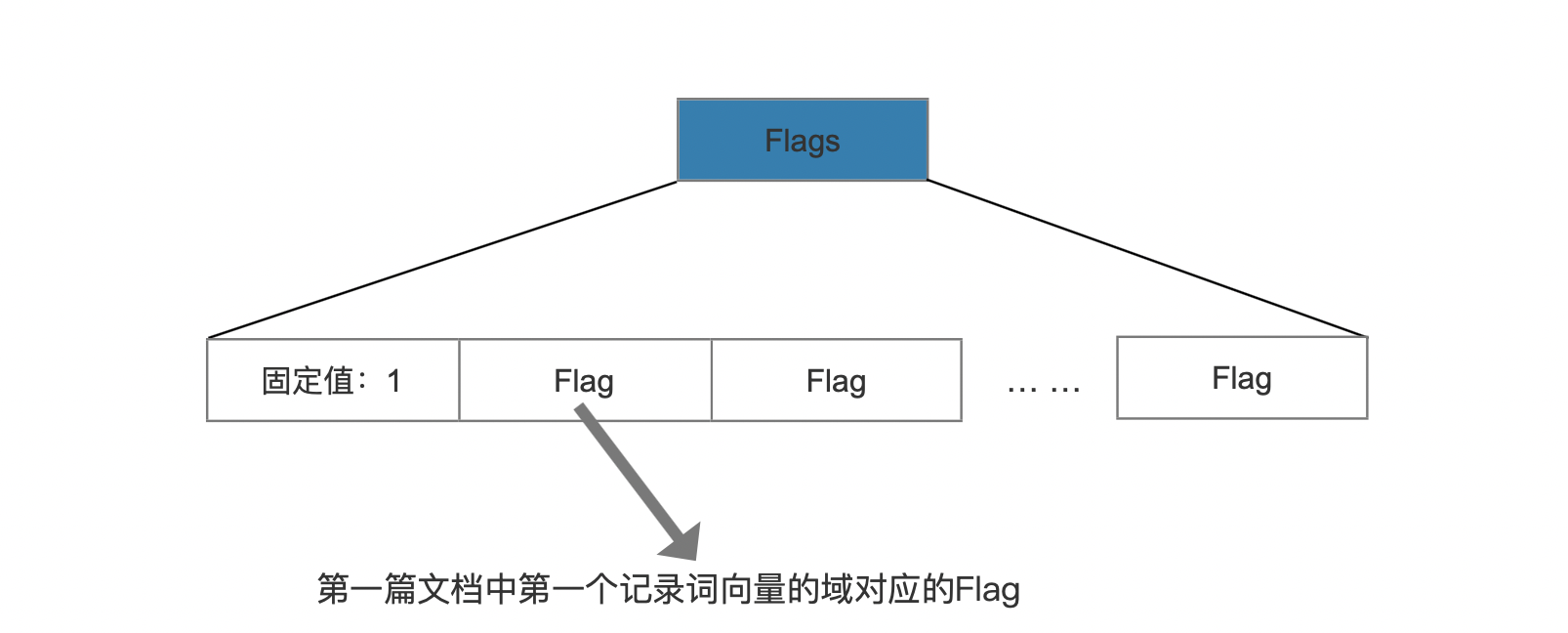
对于一个域名来说,它在不同文档中的flag可能不一样(例如当前文档中,某个记录词向量的域名只记录位置信息,而在下一篇文档中,该域名记录了位置信息跟偏移信息),那么只能所有文档中的所有域的flag,并且用PackedInts存储,固定值1为标志位,在读取阶段用来区分Flags的不同数据结构。图12中,每个Flag对应为某篇文档中的某个记录词向量的域。
TermData
TermData记录了域值以及Payload信息。
图13:
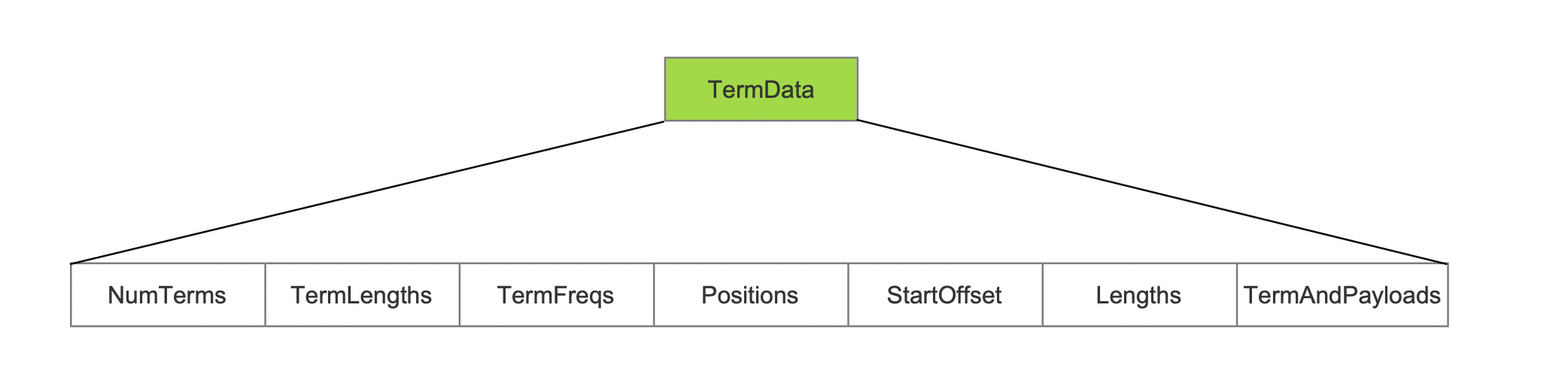
NumTerms
NumTerms描述了每一篇文档的每一个域包含的term个数,使用PackedInts存储。
TermLengths
TermLengths描述了每一篇文档的每一个域中的每一个term的长度,使用PackedInts存储。
TermFreqs
TermFreqs描述了每一篇文档的每一个域中的每一个term在当前文档中的词频,使用PackedInts存储。
Positions
Positions描述了每一篇文档的每一个域中的每一个term在当前文档中的所有位置position信息,使用PackedInts存储。
StartOffset
StartOffset描述了每一篇文档的每一个域中的每一个term的startOffset,使用PackedInts存储。
Lengths
Lengths描述了每一篇文档的每一个域中的每一个term的偏移长度,使用PackedInts存储。
TermAndPayloads
使用LZ4算法存储每一篇文档的每一个域中的每一个term值跟payload(如果有的话)。
索引文件.tvd整体数据结构
图14:
索引文件.tvx
图15:
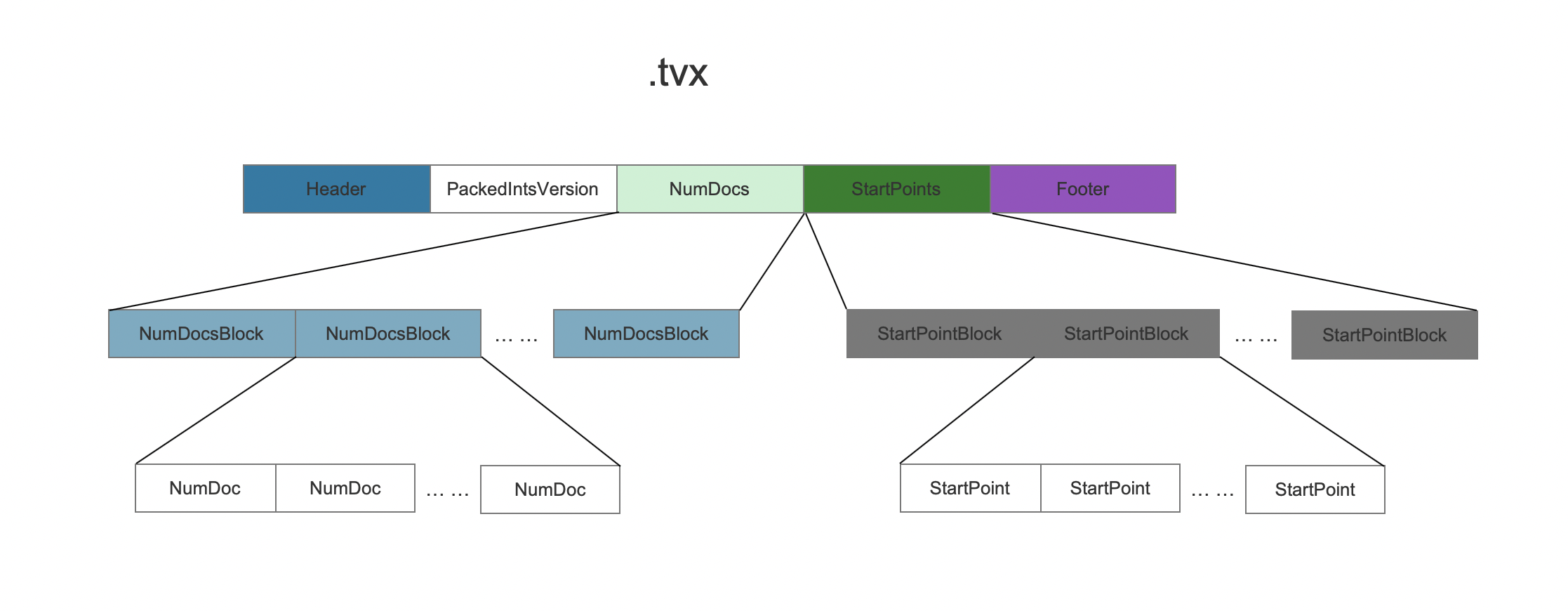
索引文件.tvx中的字段含义同索引文件.fdx, 不赘述。
索引文件.tvm
图16:
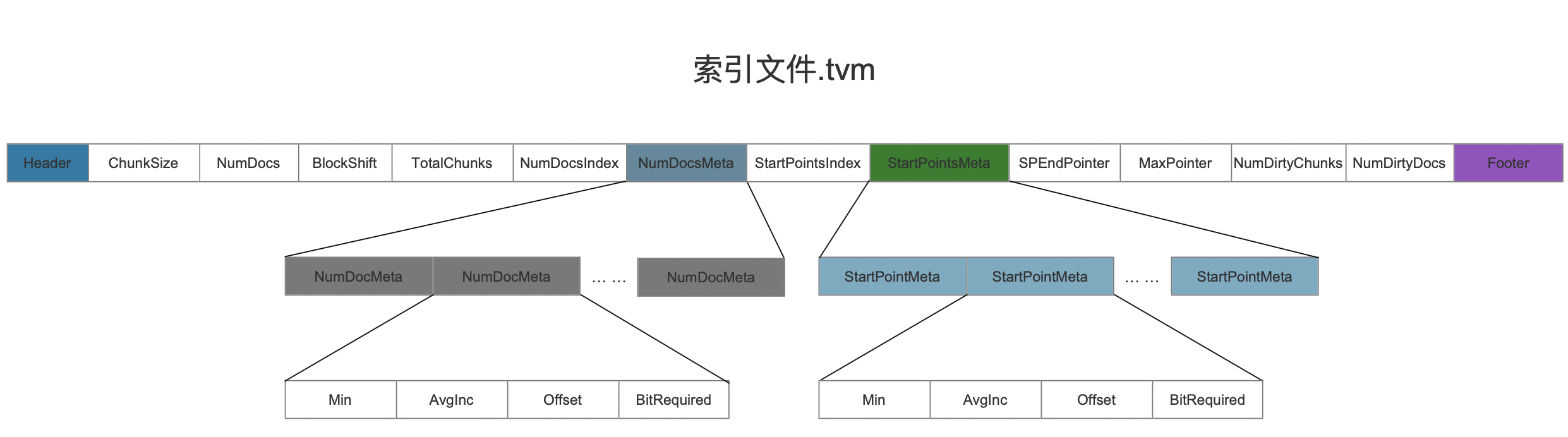
索引文件.tvm中的字段含义同索引文件.fdm, 不赘述。
结语
看完这篇文章后,如果感到一脸懵逼, 木有关系,在随后的文章将会详细介绍索引文件tvd&&tvx&&tvm的生成过程。
点击下载Markdown文件