

在文章BinaryDocValues中我们介绍了Lucene 7.5.0版本的数据结构,并且在文章索引文件的生成(二十一)之dvm&&dvd中介绍了Lucene 8.4.0中其数据结构的生成。阅读本文前建议先看下上述的两篇文章,因为很多重复的内容不会在本文中展开。
数据结构
在Lucene 8.5.0之前,BinaryDocValues的数据结构如下所示,以Lucene 7.5.0为例:
图1:
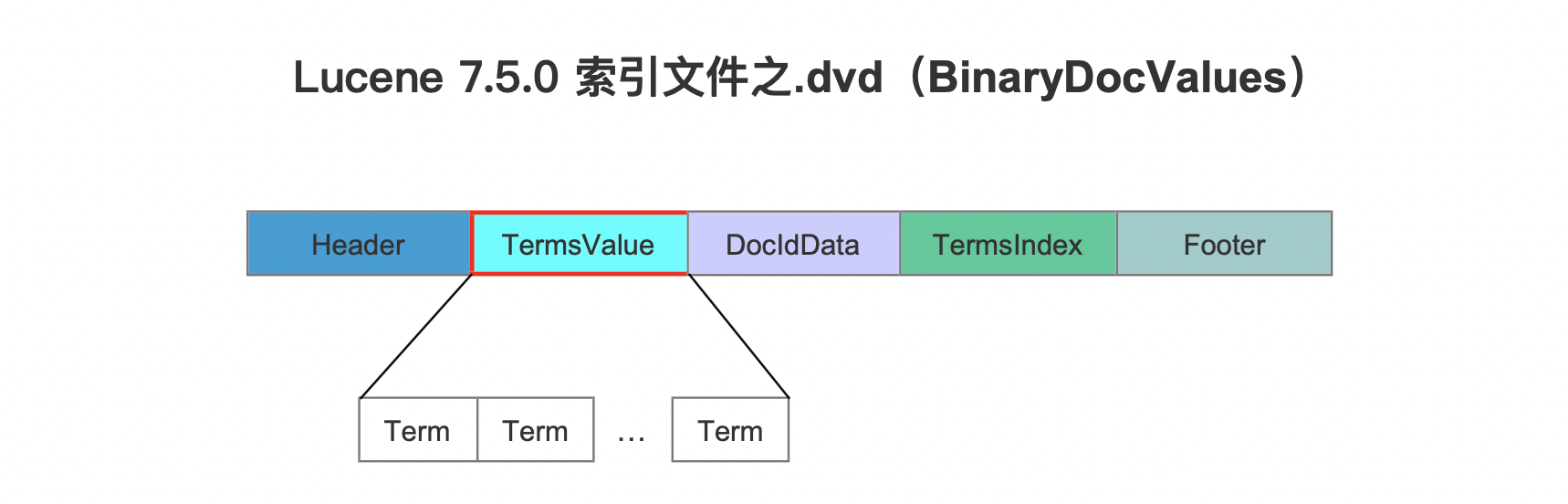
图1中,TermsValue字段中的每个term存储时既不使用前缀存储,也不进行去重处理,更没有使用压缩存储,这种设计的初衷在与读取阶段能避免解码以及解压的操作,使得有更高的读取性能。然而这必然在某些场景下导致索引文件.dvd较大。
在Lucene8.5.0中,Mark Harwood在对TermsValue使用LZ4进行压缩存储后,发现其索引文件.dvd的磁盘占用能大幅度降低,并且居然索引(Indexing)以及搜索的性能并没有降低,反而有更大的提升。它在一次RP中给出了测试数据。
图2:
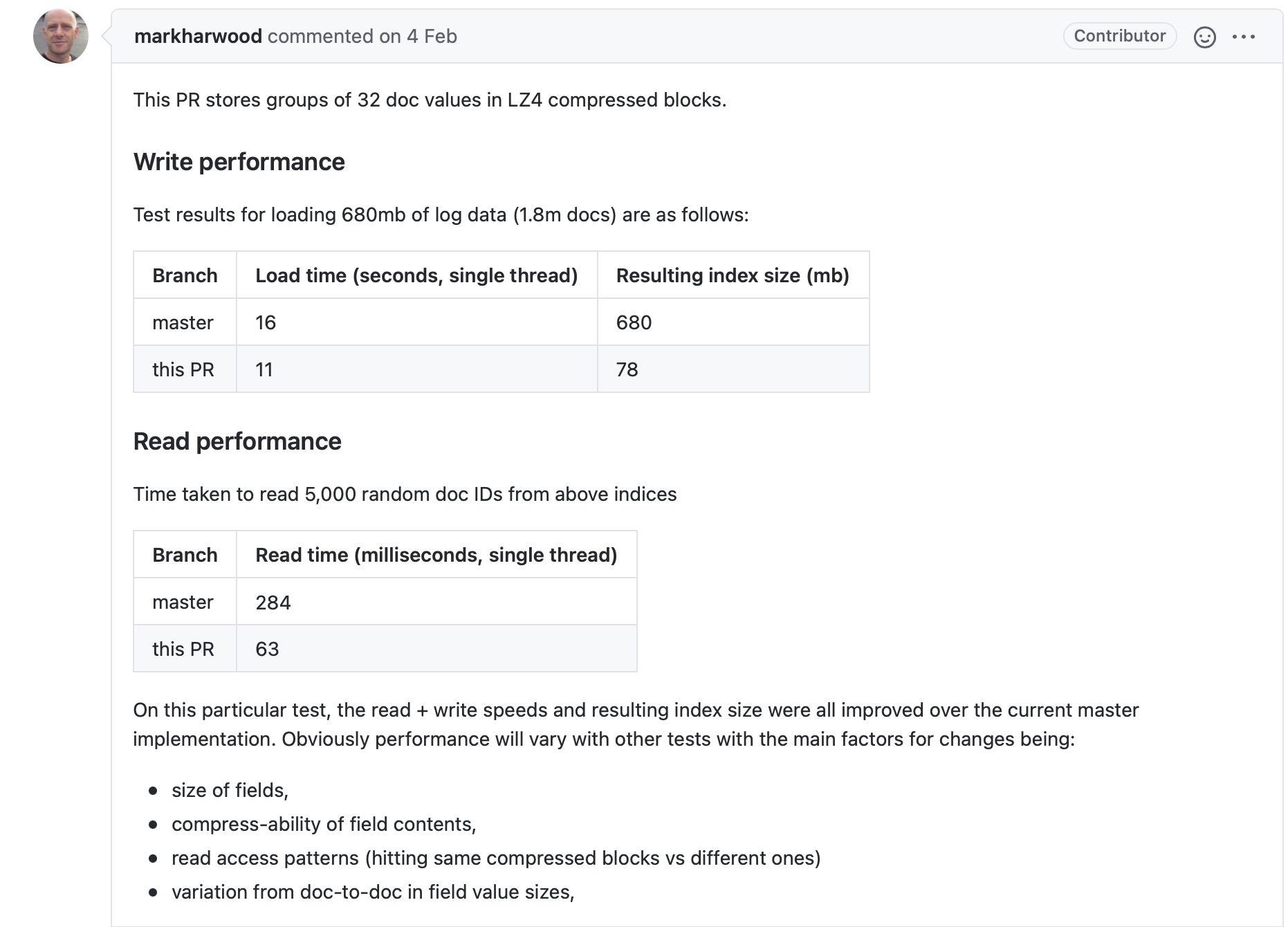
图2中,通过比较主分支以及PR可以明显看出使用压缩存储后,读写性能居然提高不少,大佬Mike McCandless看到后的反应感觉也是受到了点惊吓呀:
图3:
不过随后在Lucene专用的benchmark中,发现其读写性能并没有显著提高。图2中的测试数据被认为是一种特殊的场景。既然没有影响读写性能,并且的确能减少索引文件.dvd的磁盘占用,由于TermsValue中的term集合中不是去重的,那么当使用LZ4时能有较高的压缩率,因为LZ4的核心原理就是找出相同的数据流进行压缩。
使用Lucene专用的benchmark的讨论以及测试数据可以见阅读这个issue: https://issues.apache.org/jira/browse/LUCENE-9211。
TermsValue的压缩存储
在索引阶段,每处理32(32这个值的选择是对各种候选值测试后的较优解)个BinaryDocValue的域值,就生成一个block。所有的域值以字节流的方式写入到这个block中,并且通过DocLengths字段来描述每一个域值的长度,即占用的字节数量,使得读取阶段能从字节流中准确的读取出每一个域值,如下所示:
图4:
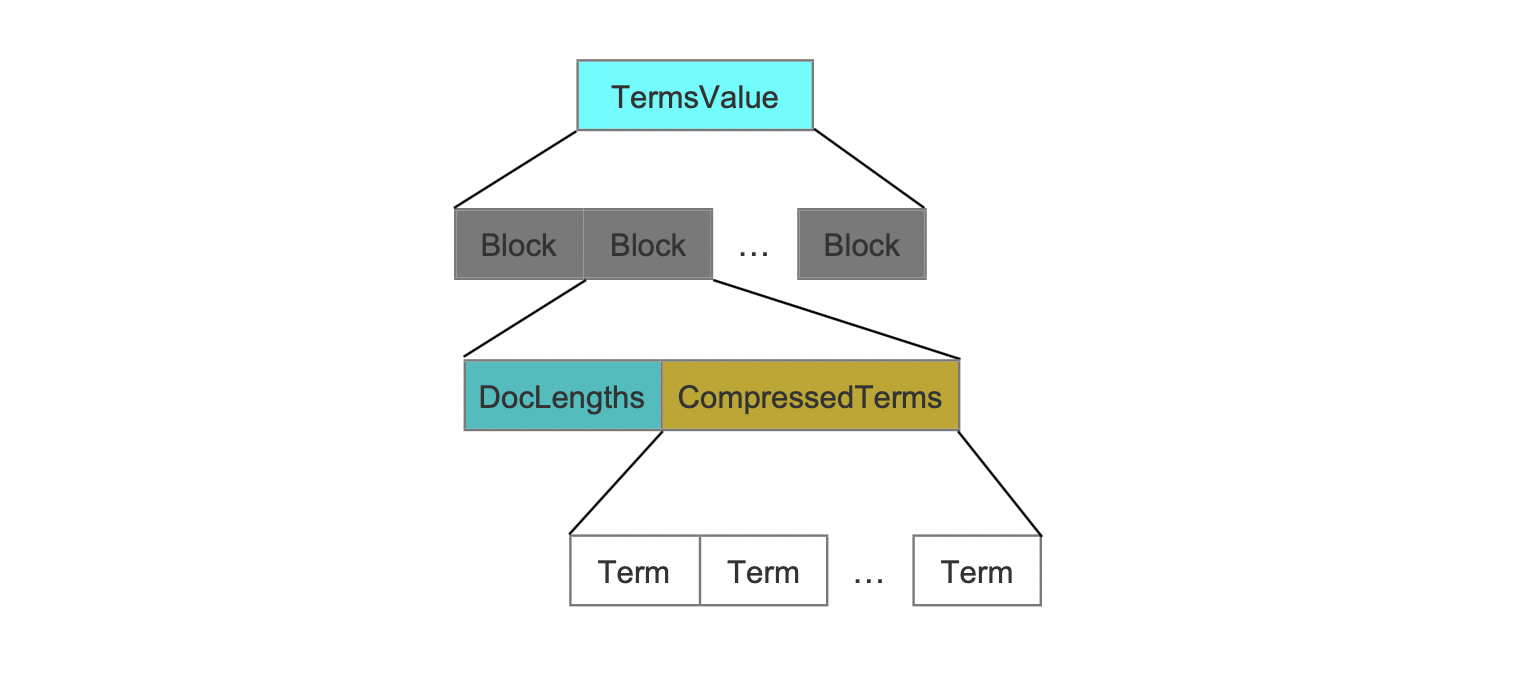
图4中,每处理32个域值就就生成一个Block。
DocLengths
该字段根据这个32个域值的长度是否都相等有不同的两种数据结构:
所有Term的长度都相等
长度相等描述的是term占用的字节数量相同,此时DocLengths的数据结构如下所示:
图5:
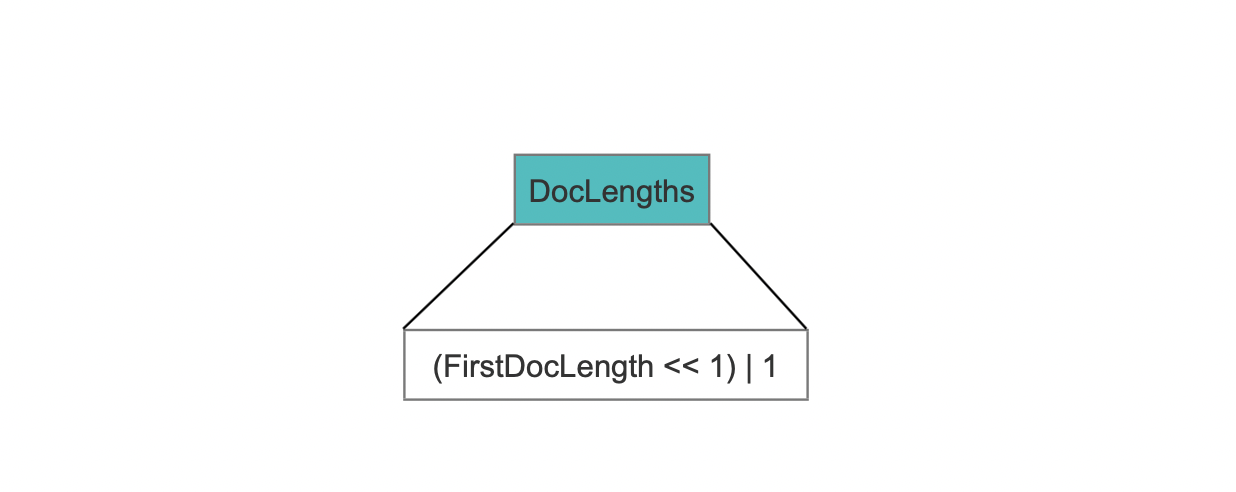
既然所有term的长度都相等,那么只要记录第一个term的长度即可,将这个term的长度和固定值1实现组合存储写入到DocLengths字段,固定值1用来在读取阶段区分DocLengths的数据结构。
至少有一个Term跟其他Term的长度不相等
这种情况下,需要记录所有term的长度:
图6:
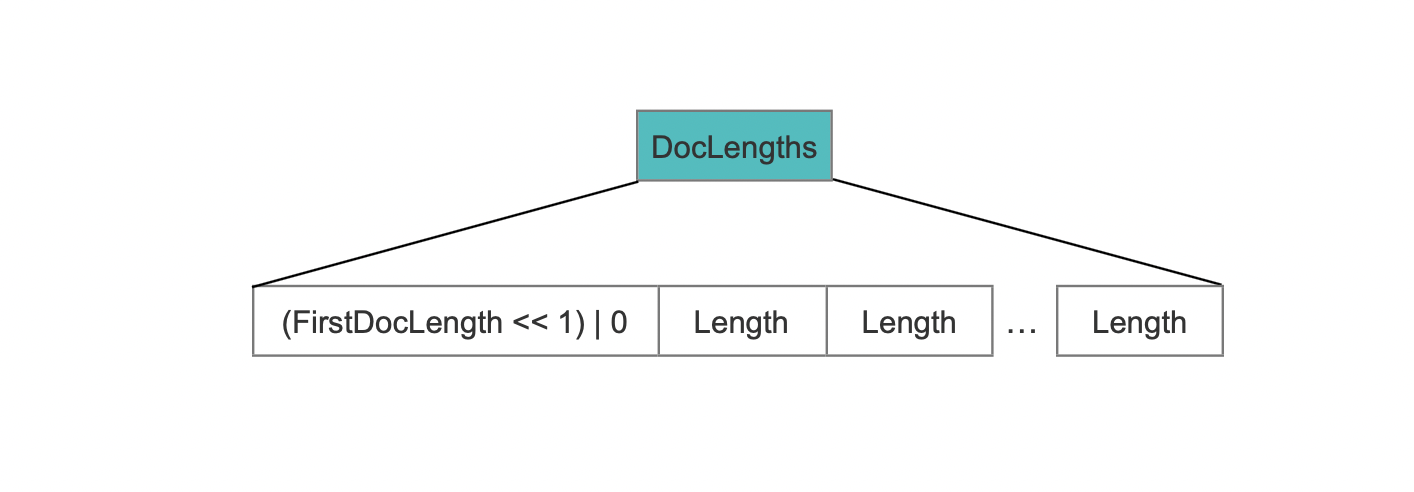
除了第一个term长度,它需要跟固定值0实现组合存储外,其他term的长度依次写到DocLengths中。固定值0用来在读取阶段区分DocLengths的数据结构。
CompressedTerms
图7:
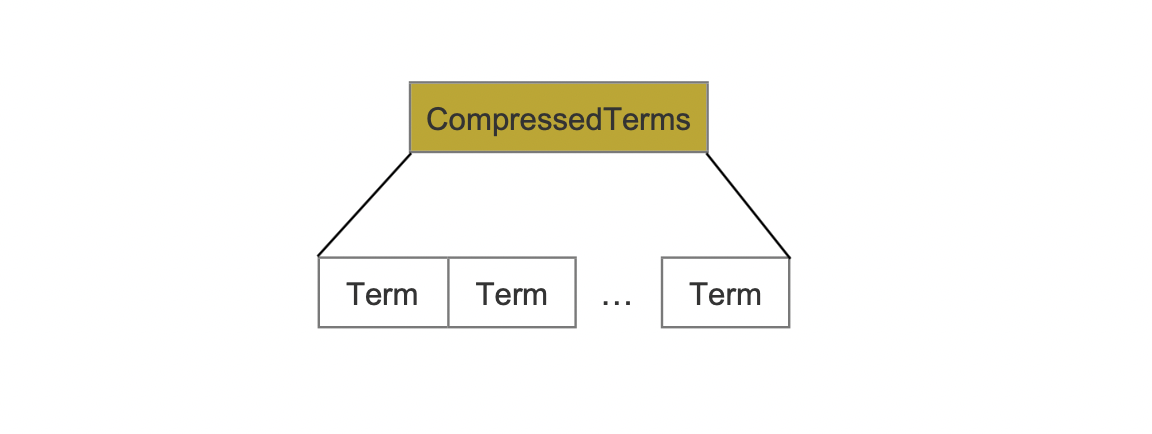
该字段中,所有term使用LZ4压缩存储。
TermsIndex
上文中说到,每处理32个BinaryDocValue的域值,就生成一个block。在处理的过程中,会使用临时文件记录每个block在索引文件.dvd中的起始读取位置,随后这些信息将被写入到TermsIndex中。
图8:
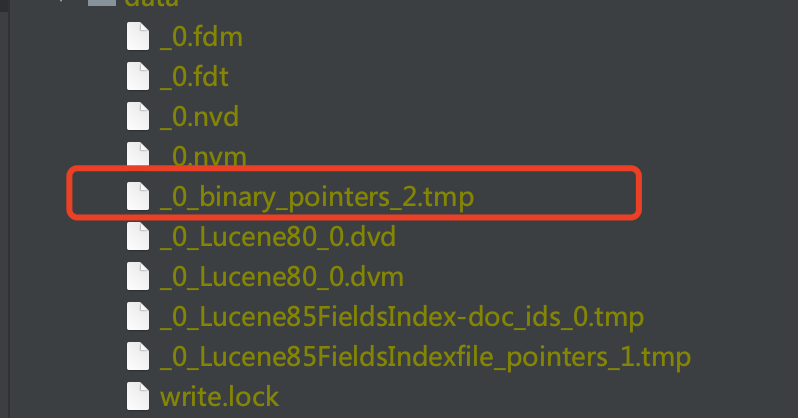
图8中,红框标注的即临时文件。
图9:
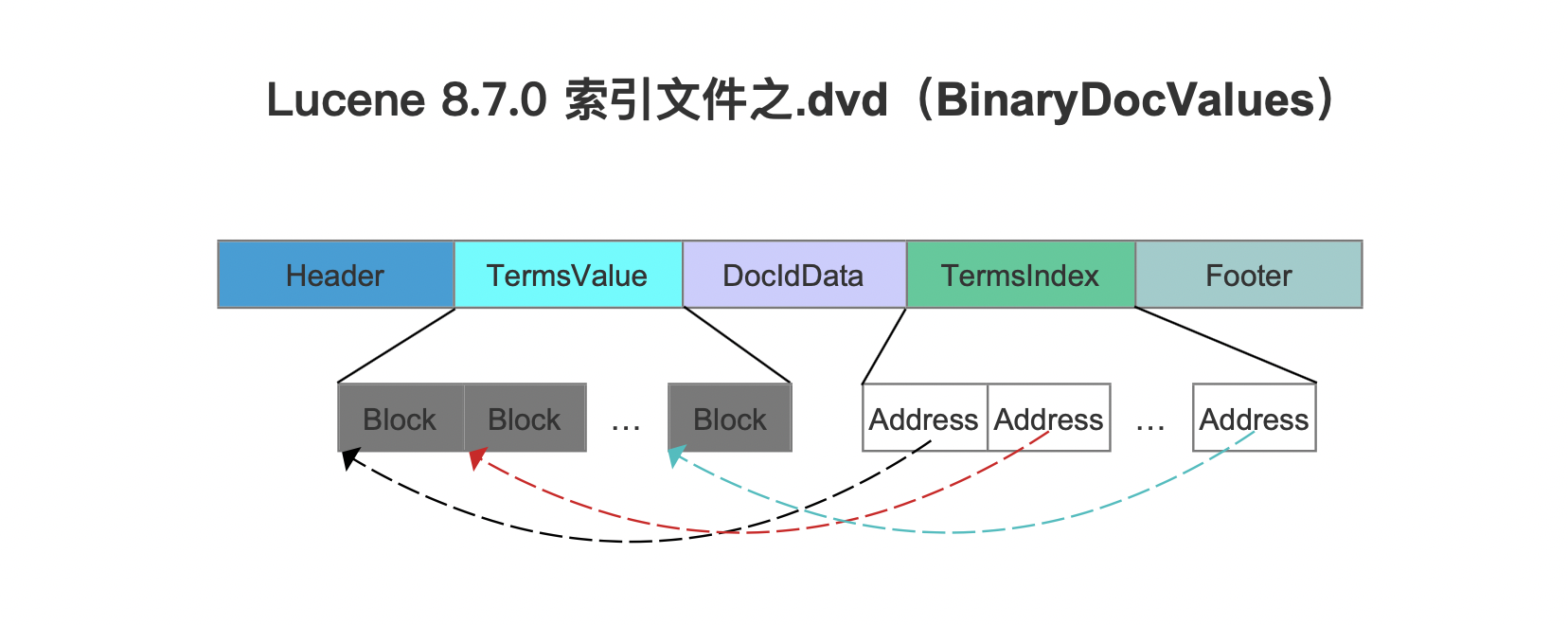
图9中的Address就是临时文件记录的信息,不过这些Address是通过DirectMonotonicWriter&&Reader编码处理,故编码元数据保存到索引文件.dvm。在读取阶段,结合索引文件.dvd中的的Address信息以及索引文件.dvm中的编码元数据,就能获取到Block在索引文件.dvd中的起始读取位置。
索引文件.dvm
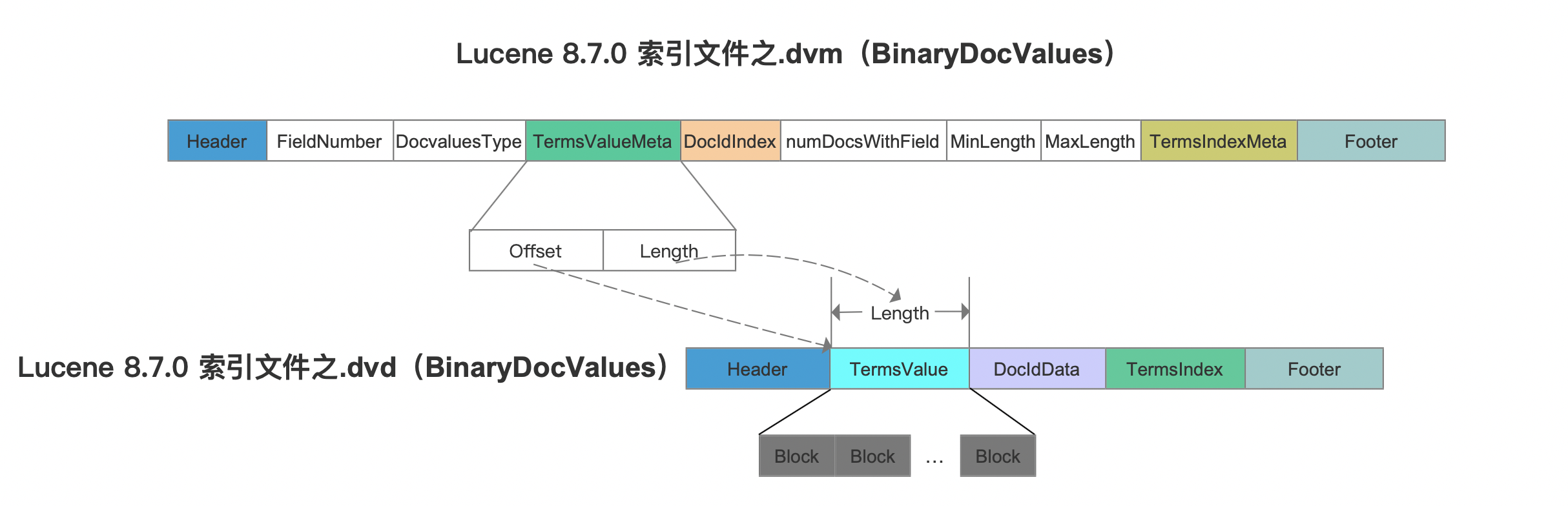
我们先看下索引文件.dvm中的TermsValueMeta字段跟索引文件.dvd的关系:
图10:
接着我们先看下索引文件.dvm中的TermsIndexMeta字段跟索引文件.dvd的关系:
图11:
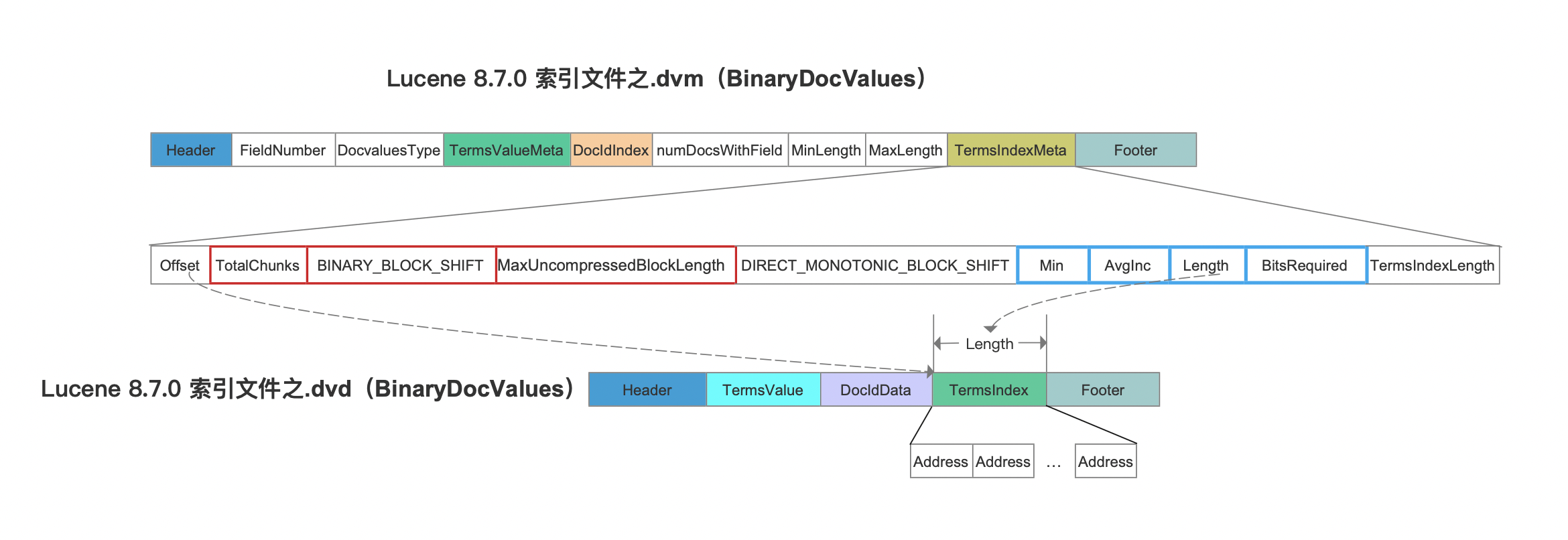
图11中,TotalChunks跟BINARY_BLOCK_SHIFT是相比较Lucene8.5.0之前新增的字段。另外Offset跟TermsIndexLength两个字段用来描述索引文件.dvd中TermsIndex的数据区间。
TotalChunks
该字段描述的是图10中,索引文件.dvd中TermsValue中的Block的数量。
BINARY_BLOCK_SHIFT
该字段描述了在索引阶段处理多少个BinaryDocValue的的域值就生成一个Block。
MaxUncompressedBlockLength
该字段描述了图4中所有Block中CompressedTerms压缩前的最大长度,该值在读取阶段用于定义一个字节数组的长度,该字节数组用于存储解压后的CompressedTerms。
上文中我们说到索引文件.dvd中的Address使用DirectMonotonicWriter&&Reader编码处理,实际上每处理 (2 << DIRECT_MONOTONIC_BLOCK_SHIFT) 个Address就生成一个Block,并生成该Block对应的编码元数据,即图11中蓝框标注的Min、AvgInc、Length、BitsRequired。为了便于介绍,图11中只画出了一个Block的编码元数据。
结语
上文中未介绍的字段可以阅读文章文章BinaryDocValues以及索引文件的生成(二十一)之dvm&&dvd。