

DirectMonotonicWriter&&Reader
DirectMonotonicWriter类用来存储单调递增的整数序列(monotonically-increasing sequences of integers),使用了先编码后压缩的存储方式,DirectMonotonicReader类则是用来解码跟解压。
每当处理1024个数据,将会执行编码跟压缩的操作,并生成两个block,分别用来存储编码元数据以及压缩的数据,我们以索引文件之fdx&&fdt&&fdm为例:
图1:
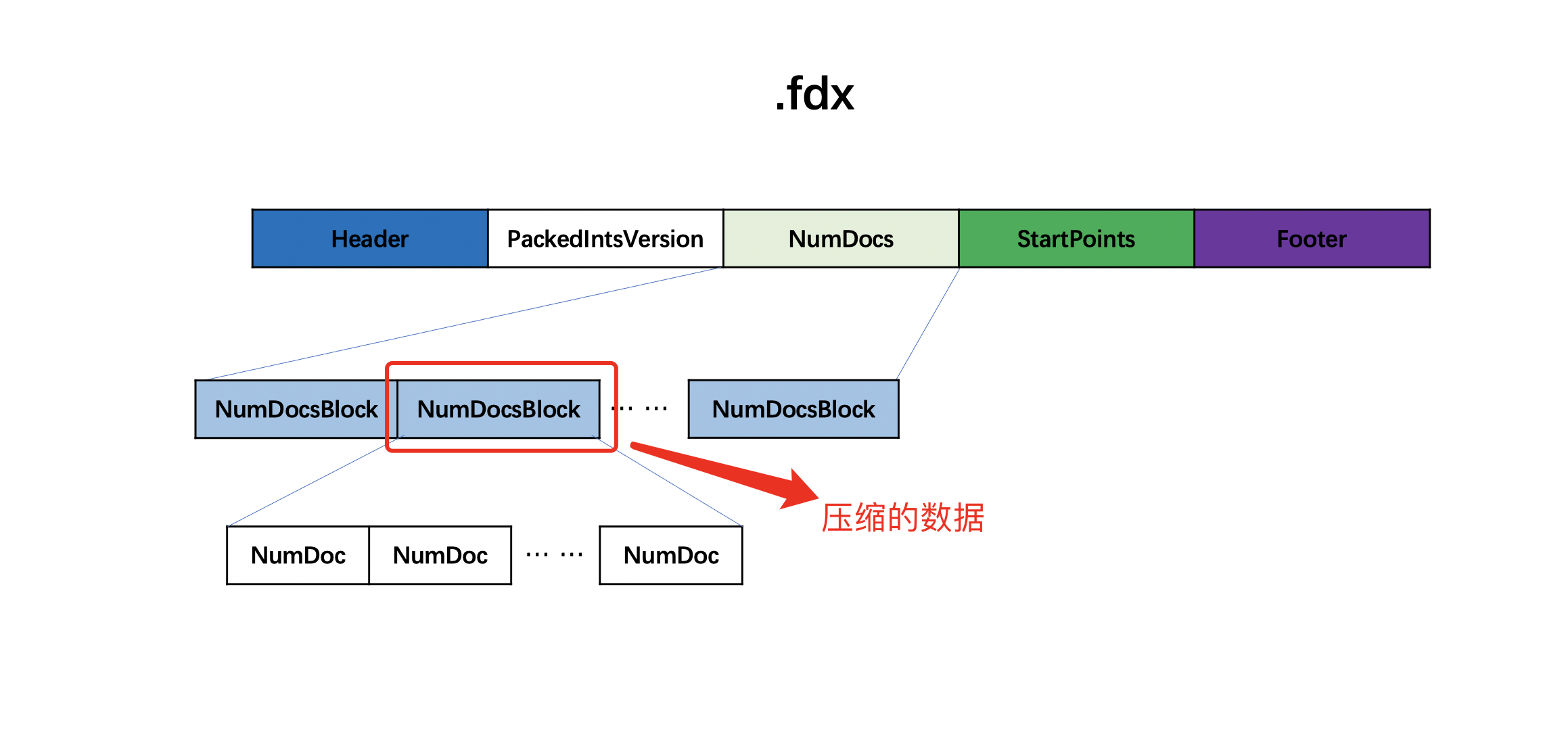
图2:
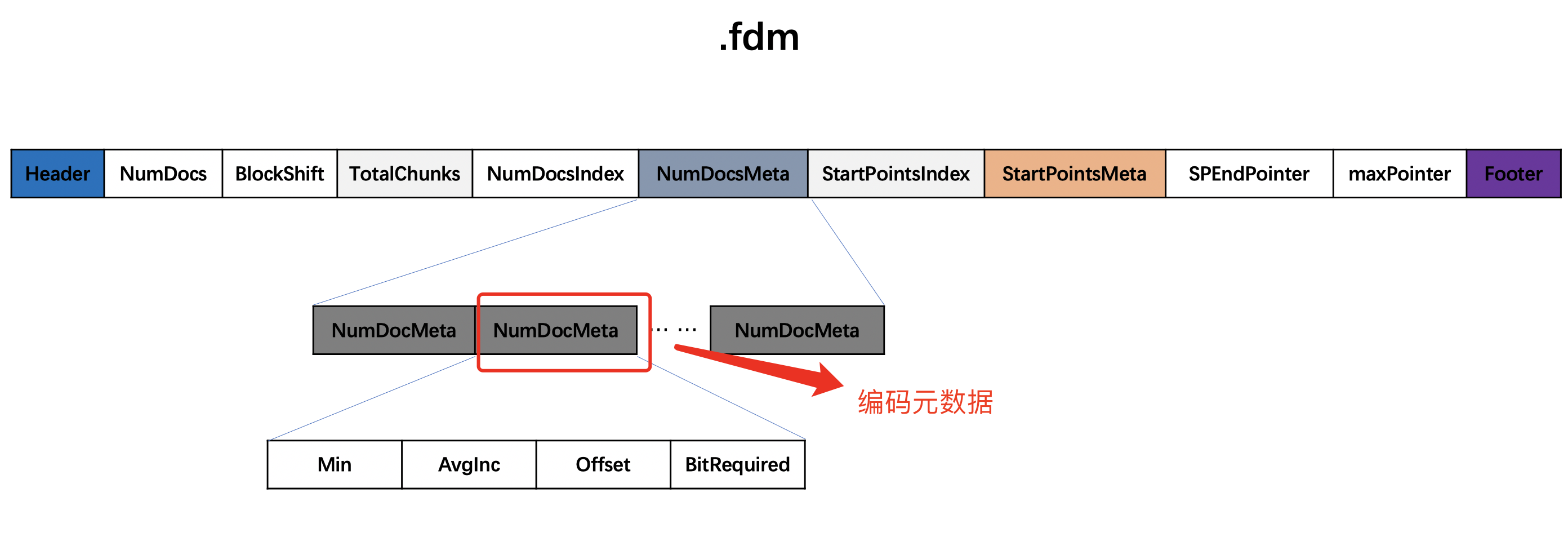
图1、图2中,每处理1024个NumDoc,先进行编码,生成的编码元数据由四部分组成:Min、AvgInc、Offset、BitRequired组成图2中的NumDocMeta字段,编码后的数据将被压缩处理,并写入到图1中的NumDocsBlock字段中。
先编码后压缩
先编码后压缩的流程图如下所示:
图3:
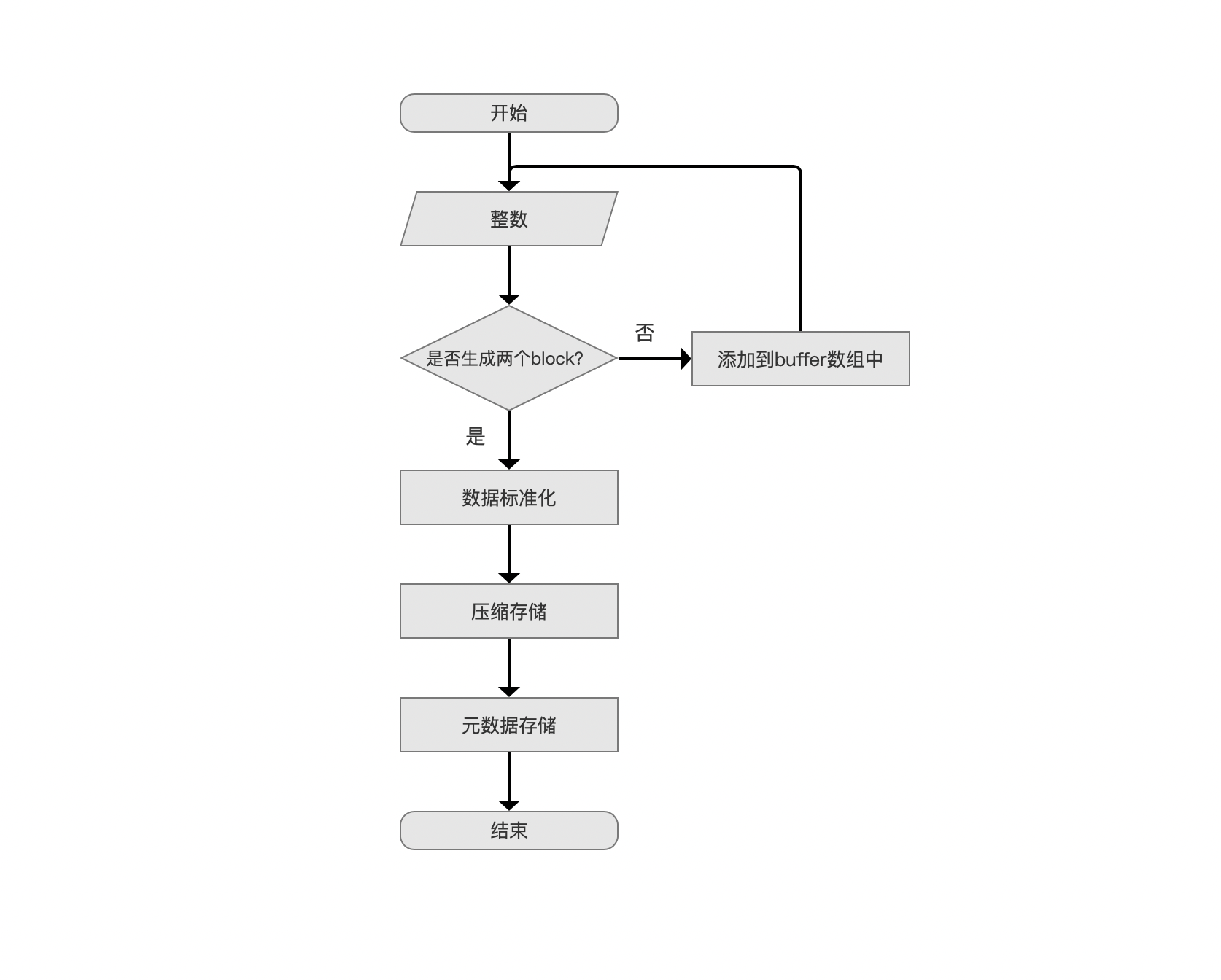
准备阶段
图4:
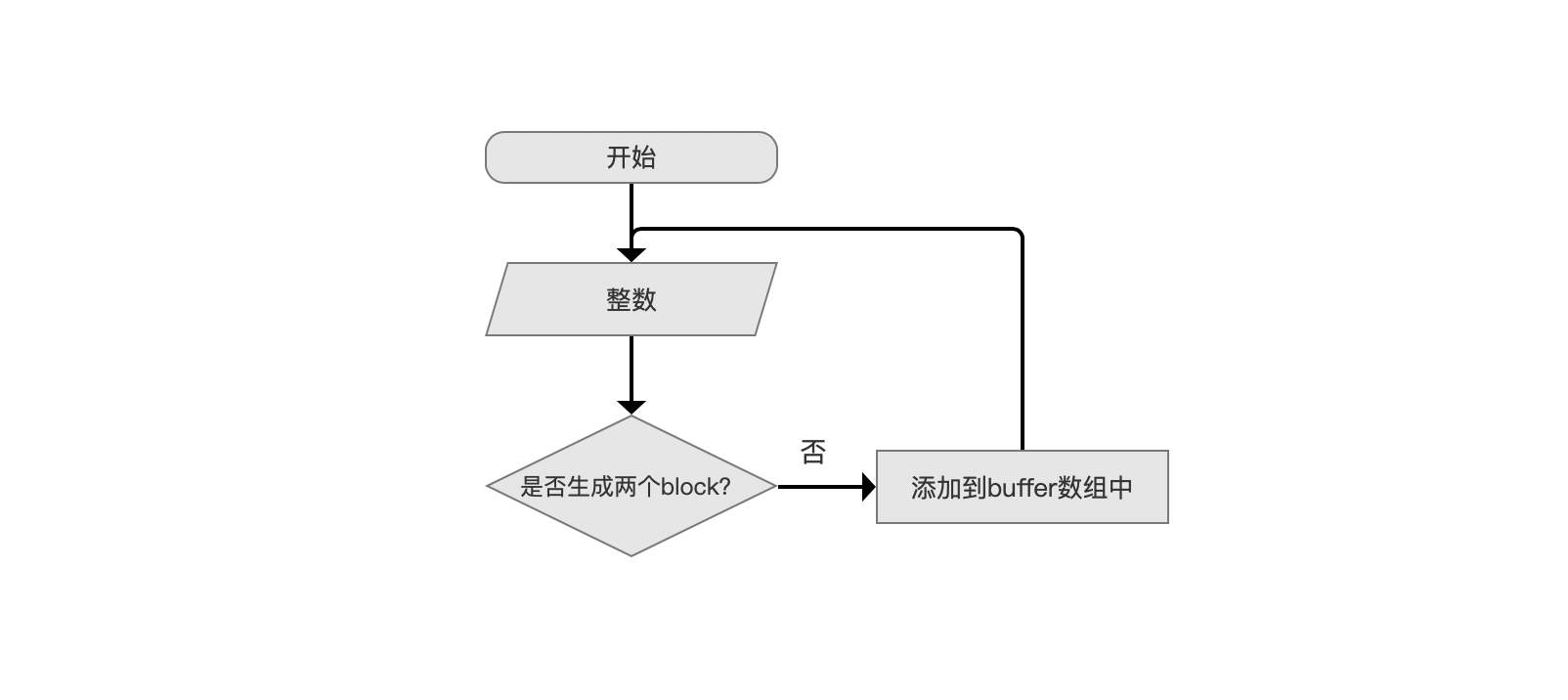
图4中,准备数据为一个整数,强调的是当前处理的整数总是比上一个整数值大,因为DirectMonotonicWriter只能处理单调递增的整数序列,是否生成两个block的条件即上文中提到的是否已经添加了1024个整数,否则就添加到buffer数组中,等待满足条件。。
数据标准化
图5:

数据标准化的处理方式为将数据,即buffer[ ]数组中的元素,按某种方式缩放,使之落入一个更小的数值区间。
数据标准化的目的在于降低存储空间,即减少索引文件的大小,需要执行以下几个步骤:
- 步骤一:计算平均值avgInc
- 步骤二:缩放数据
- 步骤三:计算最小值min
- 步骤四:无符号处理
计算平均值avgInc
由于buffer[ ]数组中的元素是递增的,所以将数组中的最后一个以及第一个元素的差值除以数组中的元素数量就可以获得平均值avgInc。代码如下:
1 | final float avgInc = (float) ((double) (buffer[bufferSize-1] - buffer[0]) / Math.max(1, bufferSize - 1)); |
缩放数据
通过下面的方式进行第一次缩放:
1 | for (int i = 0; i < bufferSize; ++i) { |
上述代码中,通过与avgInc做减法来实现缩放,并且数值越大,缩减的效果越明显。代码第2行中的 i 可以理解为权重值,来描述缩减的程度。
为什么要缩放数据?
在后续的处理中,buffer数组中的每个元素都会使用**固定位数**的方式进行存储(否则就无法读取了),由于buffer数组中的元素是递增的,如果不进行缩放,每个元素占用的bit数量会按照数组中最大的元素所需的bit数量,会造成极大的存储浪费。
我们用一个例子来展示缩放的效果,完整demo见:https://github.com/LuXugang/Lucene-7.5.0/blob/master/python/DirectMonotonicTest/ReductionTest.py , 该例子使用Python实现了处理逻辑。
缩放前的数值分布:
图6:
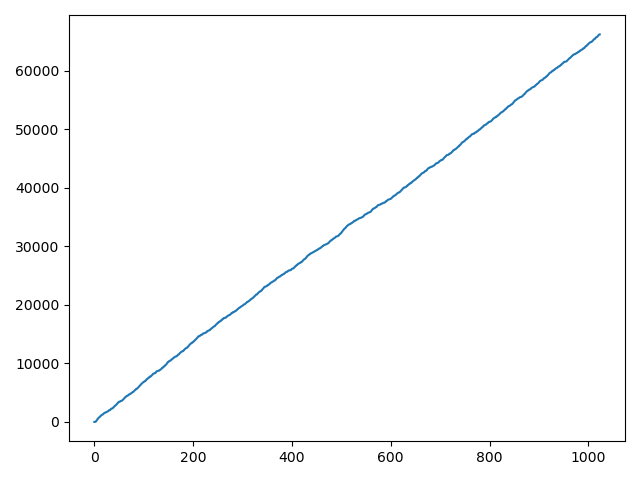
正如上文中所说的,buffer数组是个递增序列。
缩放后的数值分布:
图7:
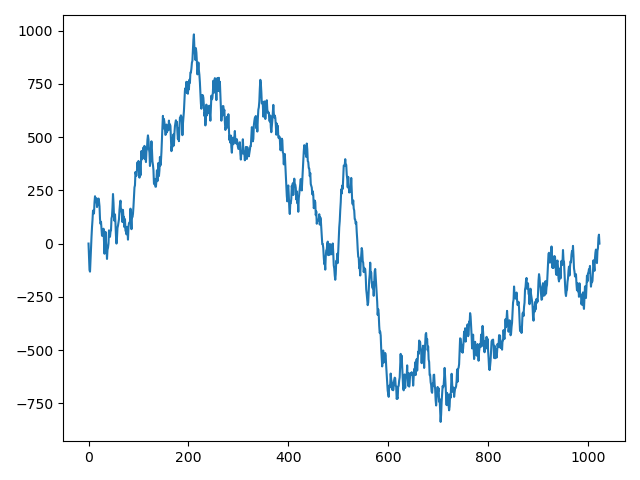
缩放后的大致数值区间由原来的[0, 60000],变成了[-750, 1000]。
计算最小值min
计算最小值的目的是为了下一步做准备,由于在第一次缩放数据的过程中,buffer[ ]数组中的元素可能不再是递增的了,所以只能通过逐个遍历数组元素来找到最小值,代码如下:
1 | for (int i = 1; i < bufferSize; ++i) { |
无符号处理
在缩放数据后,buffer中的有些数据变成了负数,由于随后将会使用PackedInts存储,该方法只支持存储无符号的数值,故结合上一步中获得的最小值min,通过下面的方法使得所有的数值进行无符号处理。
1 | for (int i = 0; i < bufferSize; ++i) { |
图8:
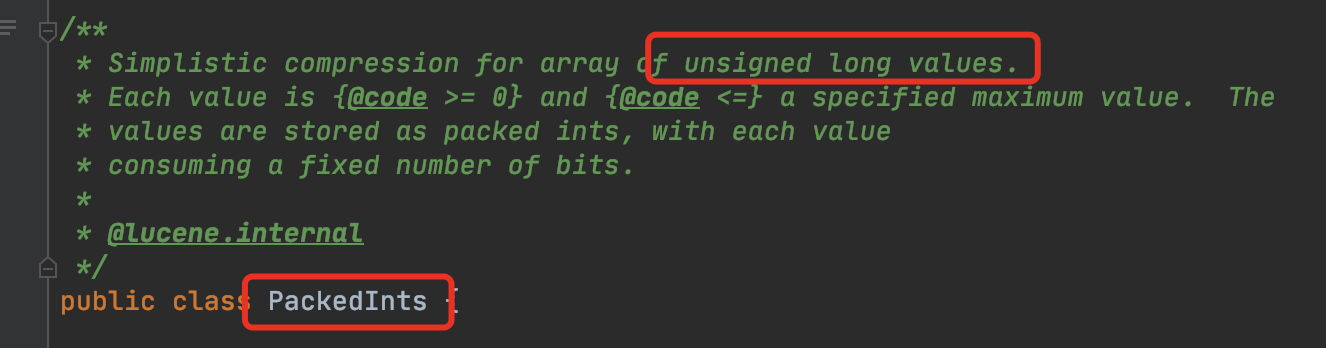
上述代码的第四行中,maxDelta通过或操作获得存储一个数值需要占用的bit数量,即图2中的BitRequired。
无符号处理后的数值分布如下所示:
图9:
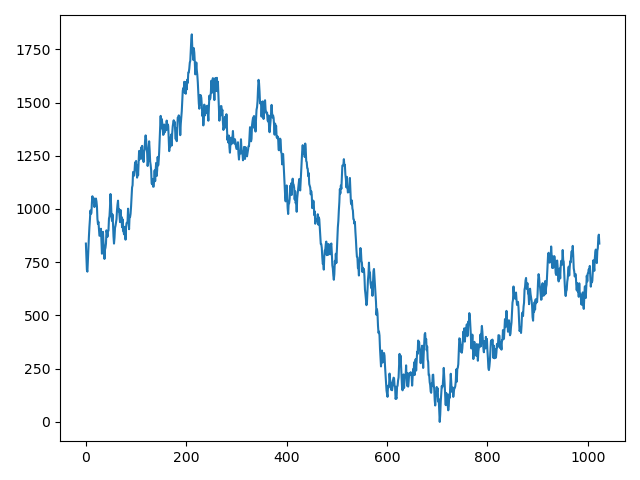
最终数值区间大致处于[0, 1750]。
压缩存储
图10:

压缩存储的过程即为将buffer中的数据生成一个block,例如在索引文件之fdx&&fdt&&fdm中就是生成一个图1中的NumDocBlock,另外由于每1024个数据就生成一个block,当生成多个block时,通过记录offset来描述每一个block的起始读取位置,offset即上文中说道的编码元数据之一。
压缩方式使用DirectWriter&&DirectReader实现,这里不赘述。
元数据存储
图11:

在上述的流程中,我们获得了编码元数据:Min、AvgInc、Offset、BitRequired,那么将这些数据生成一个block,例如图2中的NumDocMeta。
特殊情况
当buffer数组中的元素集合满足等差数列的性质时,那么可以特殊处理,使得更有效的降低存储空间。因为我们只需要存储等差数列的公差即可,根据上文中平均值avgInc的计算方式可知avgInc即公差值,那么此时只需要存储编码元数据,即只需要生成一个block。
哪种场景满足这种特殊情况?
在文章索引文件的生成(二十四)之fdx&&fdt&&fdm中,当生成一个chunk的条件都是因为达到了阈值maxDocsPerChunk,就能满足这种特殊情况,因为每个chunk中的文档数量要么都是128或者512。
点击下载附件