

在文章索引文件之vec&vem&vex(Lucene 9.8.0)中介绍了Lucene 9.8.0版本向量数据相关的索引文件(必须先阅读下,很多重复的内容不会再提起),由于在Lucene 9.9.0中引入了Scalar Quantization(简称SQ)技术,因此再次对索引结构进行了改造。另外加上该issue,使得在Lucene 9.9.0中,对于向量数据的索引文件最多由以下6个文件组成,我们先给出简要的说明:
- .vex、.vem:HNSW信息
- .vec、.vemf:原始的向量数据,即基于SQ量化前的数据,以及文档号、文档号跟节点编号映射关系的数据
- .veq、.vemq(启用SQ才会有这两个索引文件,默认不启动):量化后的向量数据,以及文档号、文档号跟节点编号映射关系的数据
先给出这几个索引文件的数据结构之间的关联图,然后我们一一介绍这些字段的含义:
.vex&.vem
图1:
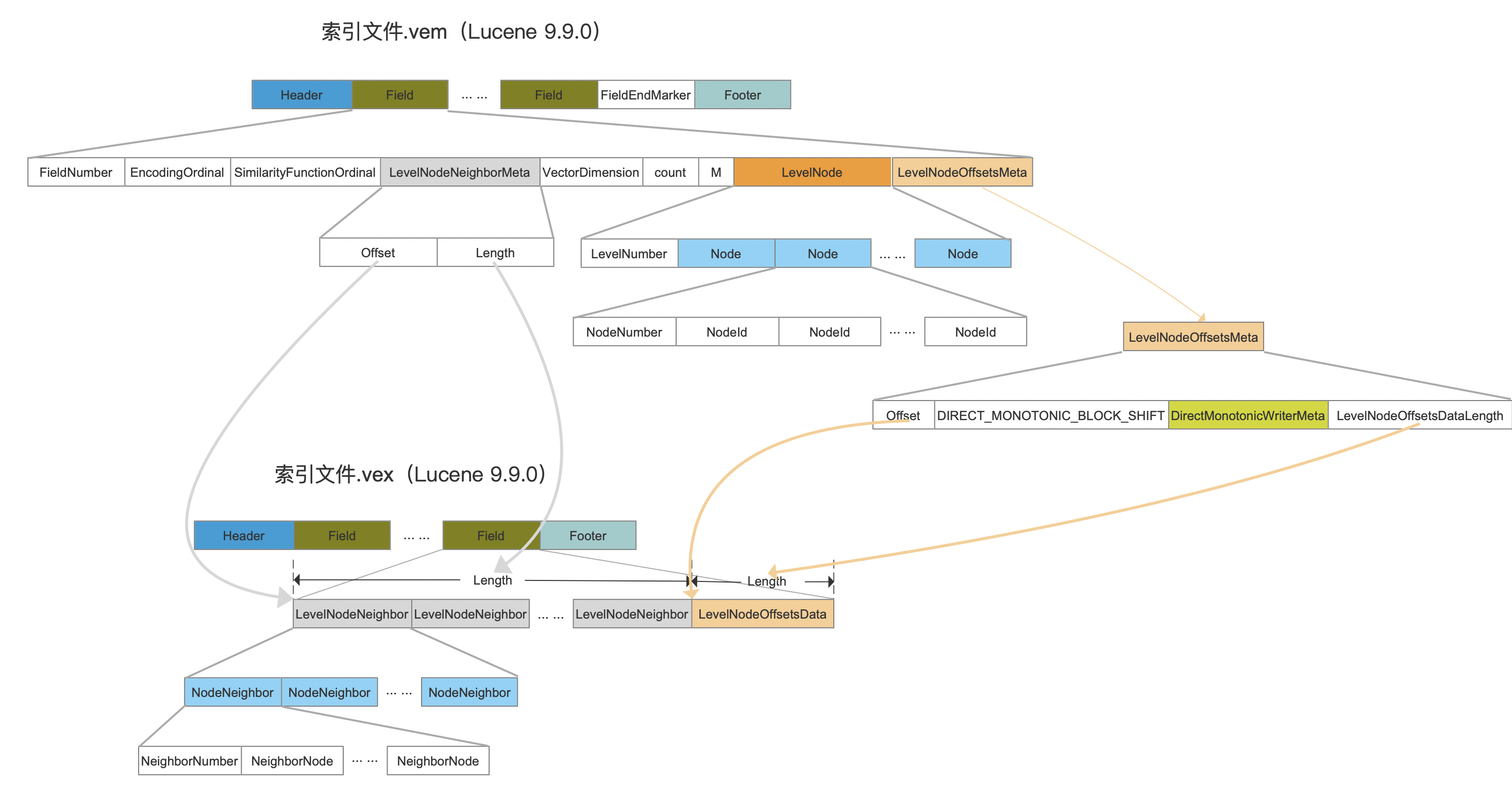
点击查看大图
.vec&.vemf
图2:
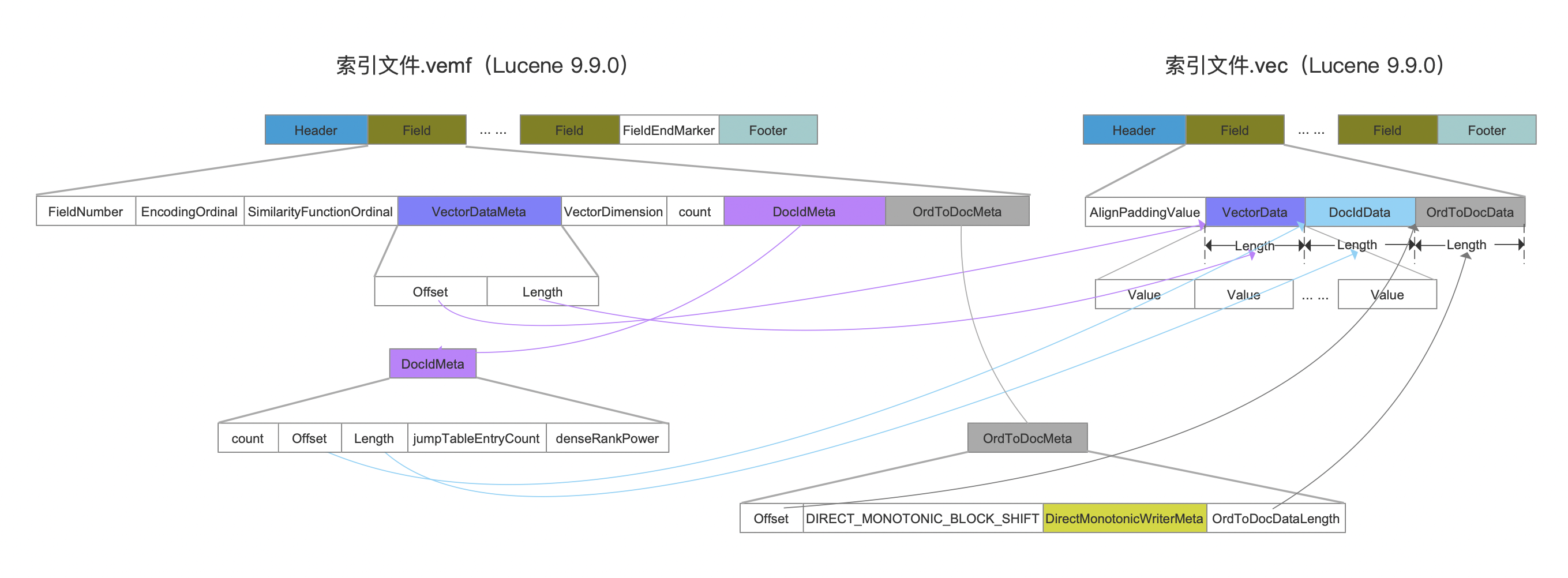
点击查看大图
.veq&.vemq
图3:
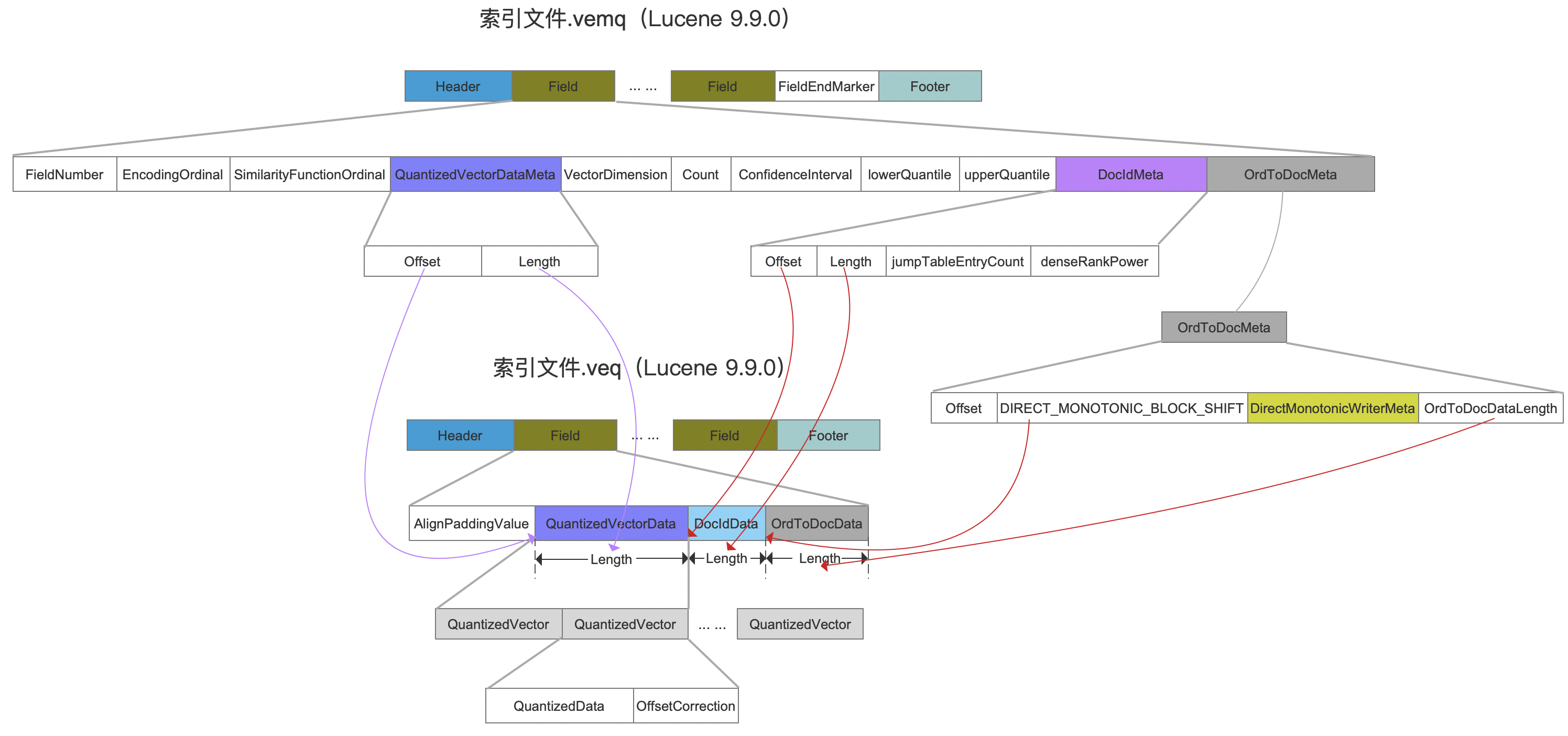
点击查看大图
数据结构
.vex&.vem、.vec&.vemf
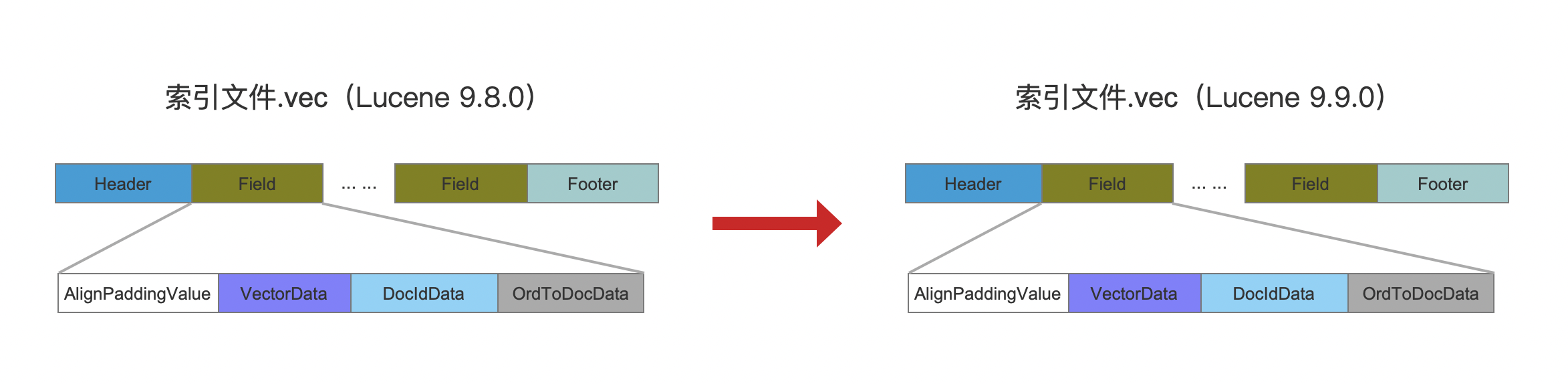
相较于Lucene9.8.0中的索引数据结构,只是调整了某些字段的所属索引文件,比如说:
- 对Lucene9.8.0中的元数据分别移到Lucene9.9.0中.vemf以及.vem中(调整的原因:GITHUB#12729)。
- Lucene9.8.0中的.vec以及.vex的数据结构保持不变
图4:
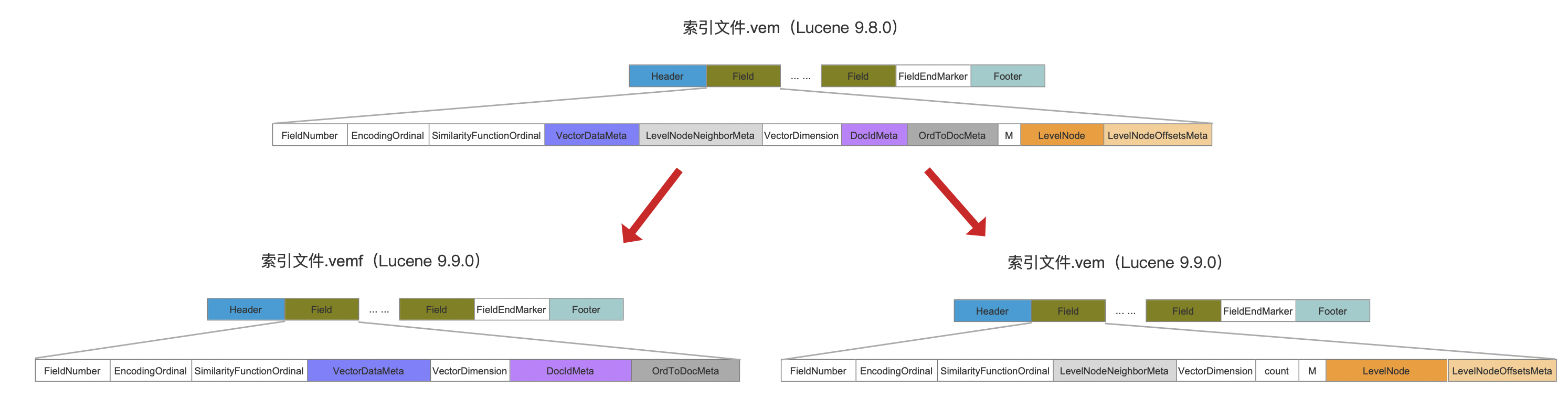
点击查看大图
图5:

点击查看大图
图6:
点击查看大图
因此,对于Lucene9.9.0中的索引文件.vex&.vem、.vec&.vemf中的字段,相比较Lucene9.8.0,并没有新增或者移除字段,因此这些字段的含义在本文中就不重新介绍了,可以阅读文章索引文件之vec&vem&vex(Lucene 9.8.0)。
.veq&.vemq
如果启用SQ,那么段中会额外多出两个索引文件,即.veq&.vemq。下图中除了红框标注的字段,其他的在文章索引文件之vec&vem&vex(Lucene 9.8.0)或者其他索引文件中同名字段有相同的含义。
图7:
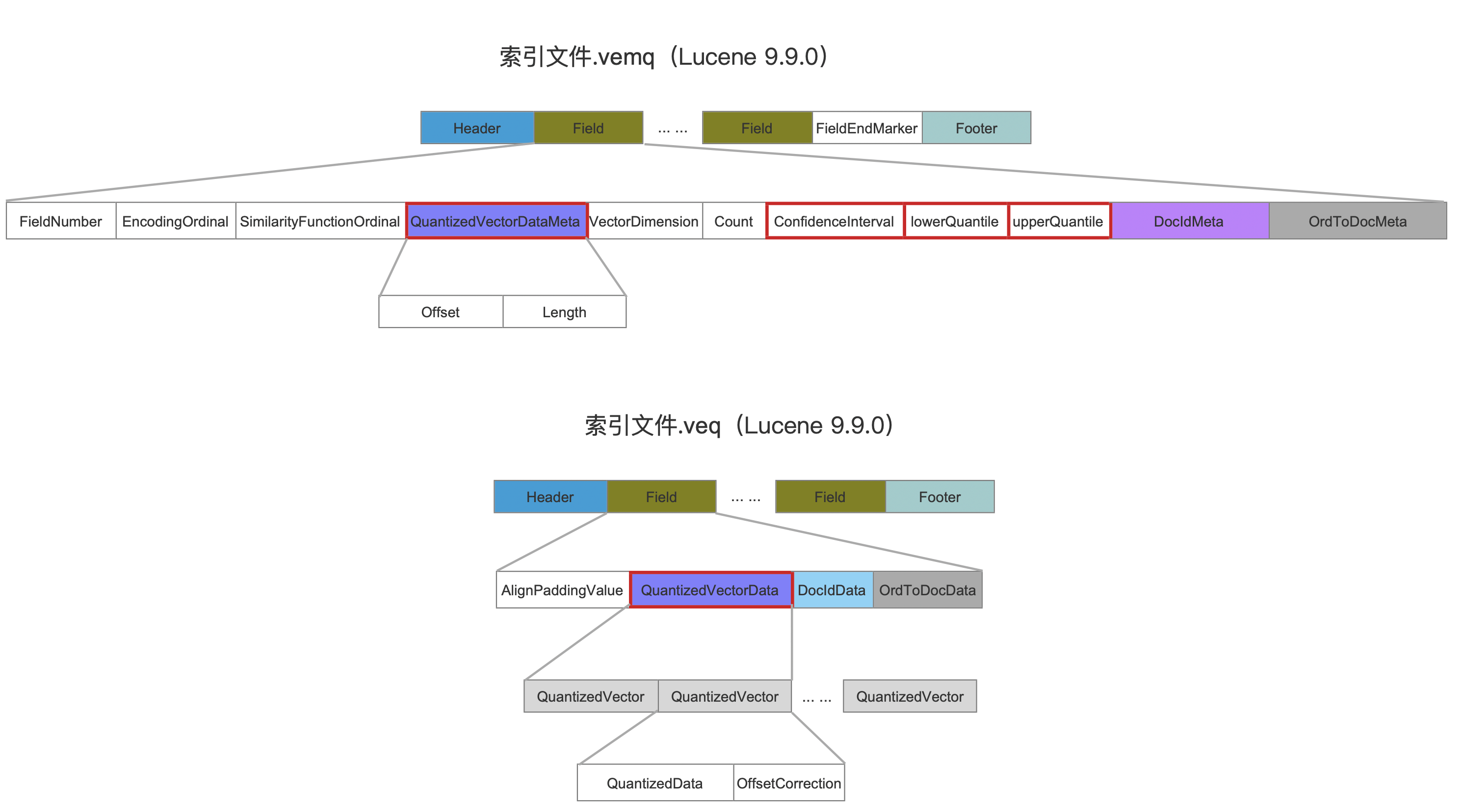
QuantizedVectorDataMeta
图8:
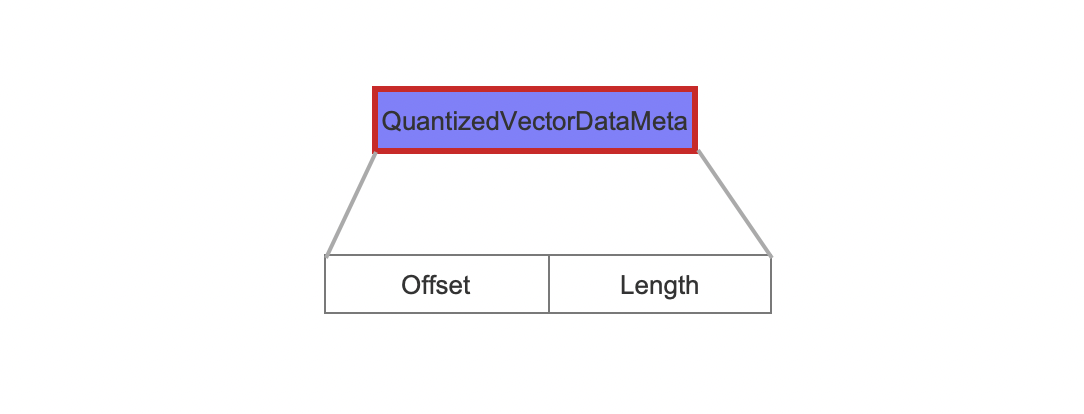
该字段作为元数据,Offset跟Length对应的区间,用来描述量化后的数据信息在索引文件.veq中的位置信息,见图3
ConfidenceInterval、lowerQuantile、upperQuantile
图9:

这三个字段用于量化操作:
- ConfidenceInterval:(0.9~1.0之间的值)置信区间。它本来应该是用来计算分位数的,但在目前版本中,还未使用该参数。
- lowerQuantile、upperQuantile:(32位的浮点数)最大和最小分位数。引入这两个字段至少有以下的目的:
- 离群值的影响:数据中的离群值(outliers)可能会对量化区间产生极端的影响。如果简单地选取数据的最小值和最大值作为量化的边界,一个异常的高或低值会导致整个量化区间的扩展,这会使得绝大多数的数据在量化后的动态范围内分布得非常紧凑。这样就会减少量化级别之间的区分度,增加了量化误差。
- 动态范围的优化:使用分位数可以有效地切除极端的离群值,使量化区间专注于数据的核心分布区域。这样做可以优化量化级别的使用,使得数据分布更均匀,从而减少量化误差。
在以后Lucene中量化技术的文章中会介绍这几个字段的作用。
QuantizedVectorData
图10:
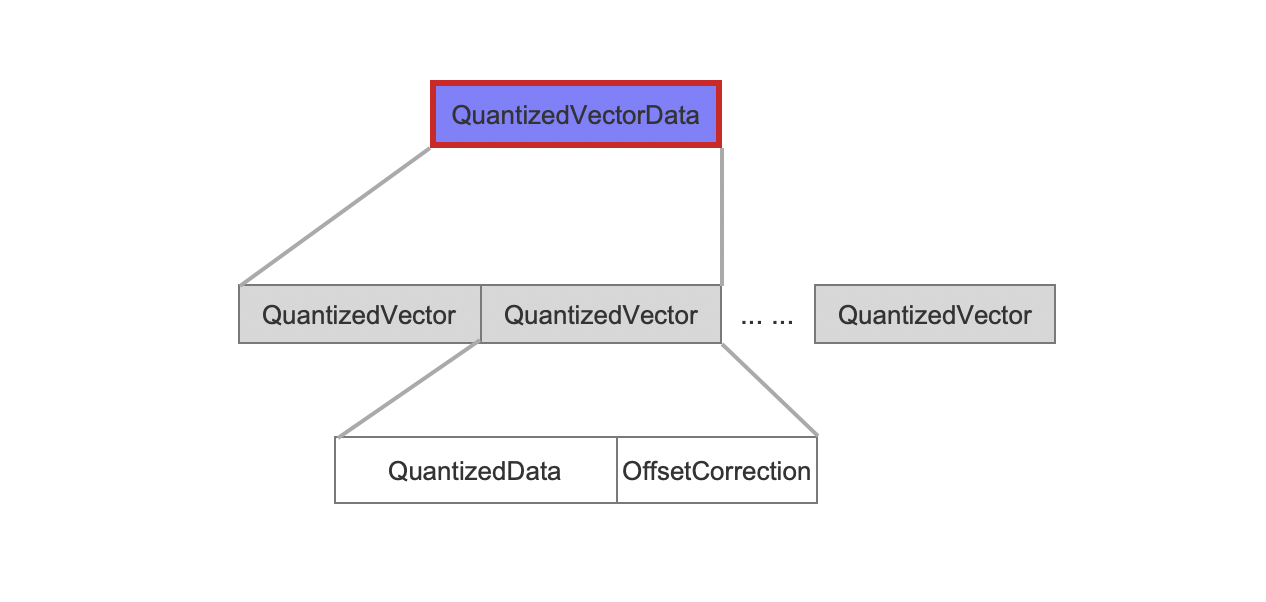
量化后的每一个向量信息由QuantizedData以及OffsetCorrection组成。
- QuantizedData:8bit大小,即使用一个字节来描述一个向量值,量化后的向量值的范围为[0,127]
- OffsetCorrection: 用来调整量化误差。这个偏移量是为了补偿量化值因为舍入到最近的整数而失去的一些精度。在计算向量距离的打分公式中会使用。同样的,该字段具体的使用场景将在以后的文章中展开
结语
本文主要介绍了因引入Scalar Quantization,向量搜索对应的索引文件的从Lucene9.8.0到Lucene9.9.0的差异。