

在索引阶段,如果某个域的属性中包含store,意味着该域的域值信息将被写入到索引文件fdx&&fdt&&fdm中,域的属性可以通过FieldType来设置,如下所示:
图1:
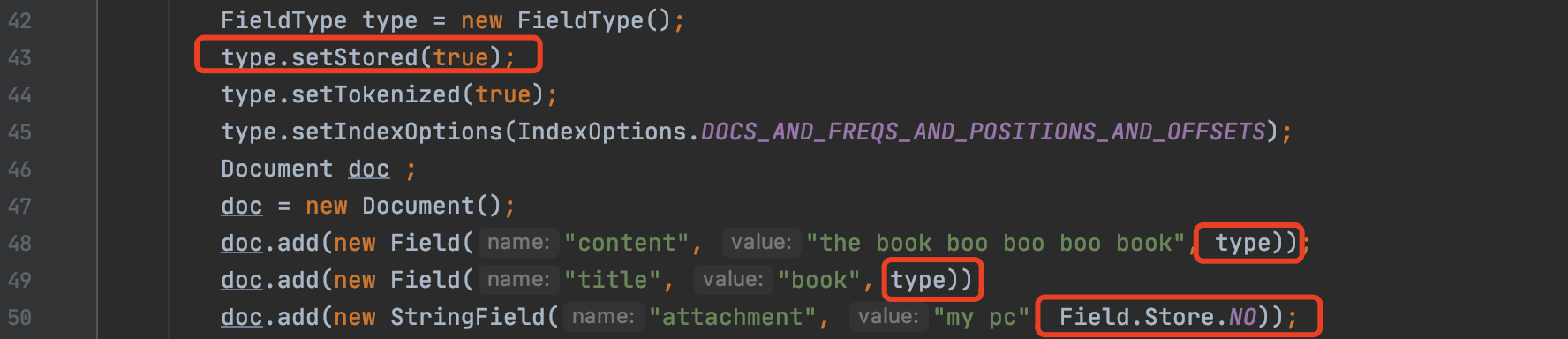
图1中,域"content"跟域"title"的域值将被存储,即写入到索引文件fdx&&fdt&&fdm中,而域”attachment“则不会。
在文章索引文件之fdx&&fdt中介绍了Lucene 7.5.0版本存储域值对应的索引文件,该版本中使用了两个索引文件.fdx、.fdt存储域值信息,而从Lucene 8.5.0版本开始进行了优化,最终用三个索引文件.fdx、fdt、fdm三个索引文件来存储域值信息,其优化的目的以及方式不会在本文中提及,随后在介绍生成这三个索引文件的生成过程的文章中再详细展开,并会跟Lucene 7.5.0版本进行对比,本文只对索引文件中的字段作介绍。
数据结构
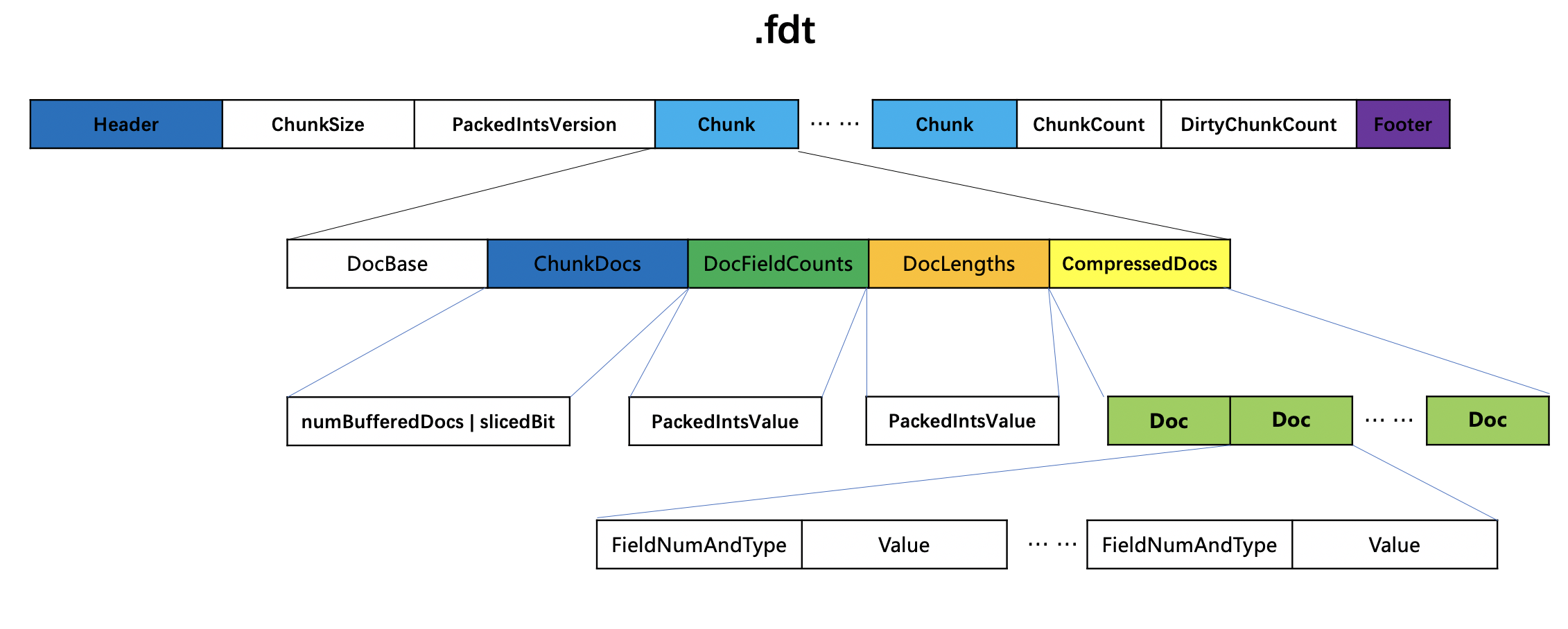
索引文件.fdt
图2:

ChunkSize
ChunkSize作为一个参数,用来判断是否要生成一个Chunk,以及用来描述压缩存储域值信息的方式,后面会详细介绍。
PackedIntsVersion
PackedIntsVersion描述了压缩使用的方式,当前版本中是VERSION_MONOTONIC_WITHOUT_ZIGZAG。
Chunk
图3:

在处理文档的过程中,如果满足以下任意一个条件,那么将已处理的文档的域值信息生成一个chunk:
- 已处理的文档数量达到128
- 已处理的所有域值的总长度达到ChunkSize。
NumDoc
当前chunk中第一个文档的文档号(该文档号为段内文档号),因为根据这个文档号来差值存储,在读取的阶段需要根据该值恢复其他文档号。
ChunkDocs
图4:
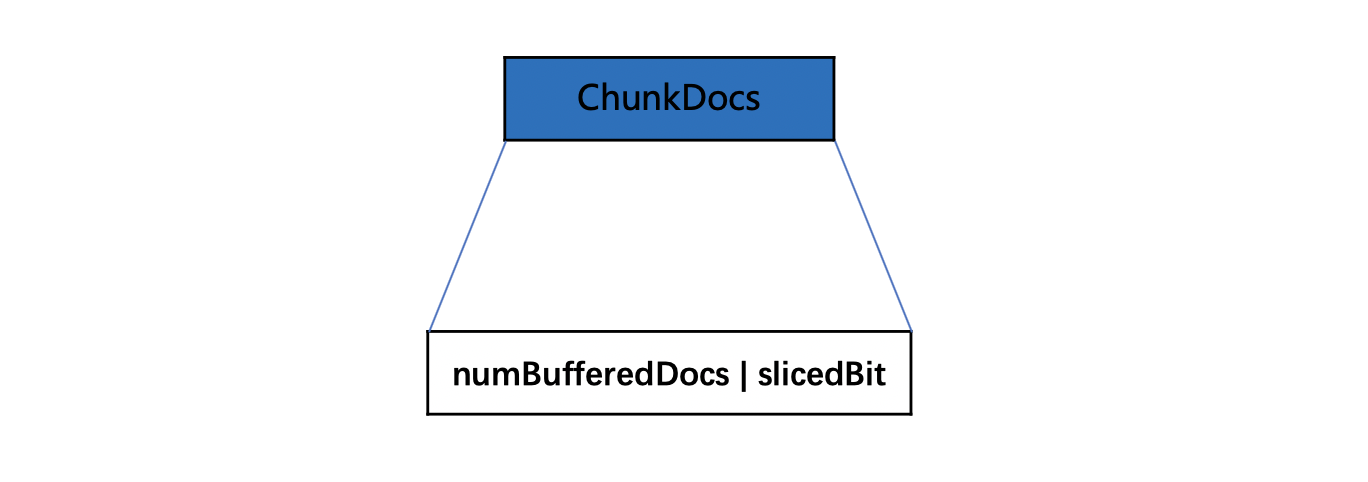
ChunkDocs是一个numBufferedDocs跟slicedBit的组合值。ChunkDocs = (numBufferedDocs |slicedBit )。
numBufferedDocs
numBufferedDocs描述了当前chunk中的文档数量。numBufferedDocs是一个 ≤ 128的值。
slicedBit
如果待处理的域值信息的长度超过2倍的chunkSize(默认值 16384),那么需要分块压缩,下文会具体介绍。
DocFieldCounts
根据chunk中包含的文档个数numBufferedDocs、每篇文档包含的存储域的数量numStoredFields分为不同的情况。
numBufferedDocs的个数为1
图5:

numBufferedDocs的个数> 1 并且每篇文档中的numStoredFields都是相同的
图6:
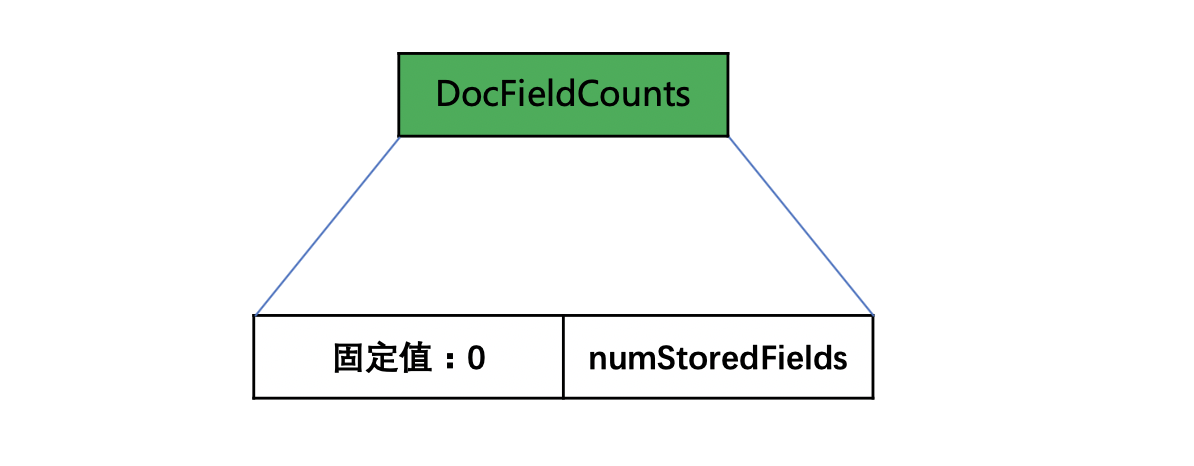
只要存储一个numStoredFields的值就行啦。
numBufferedDocs的个数> 1 并且每篇文档中的numStoredFields不都相同的
图7:

使用PackedInt来存储所有的numStoredFields,这里不赘述了,点击这里可以看其中的一种压缩方式。
DocLengths
同DocFieldCounts类似,据chunk中包含的文档个数numBufferedDocs、每篇文档中域值信息的长度分为不同的情况。
numBufferedDocs的个数为1
图8:
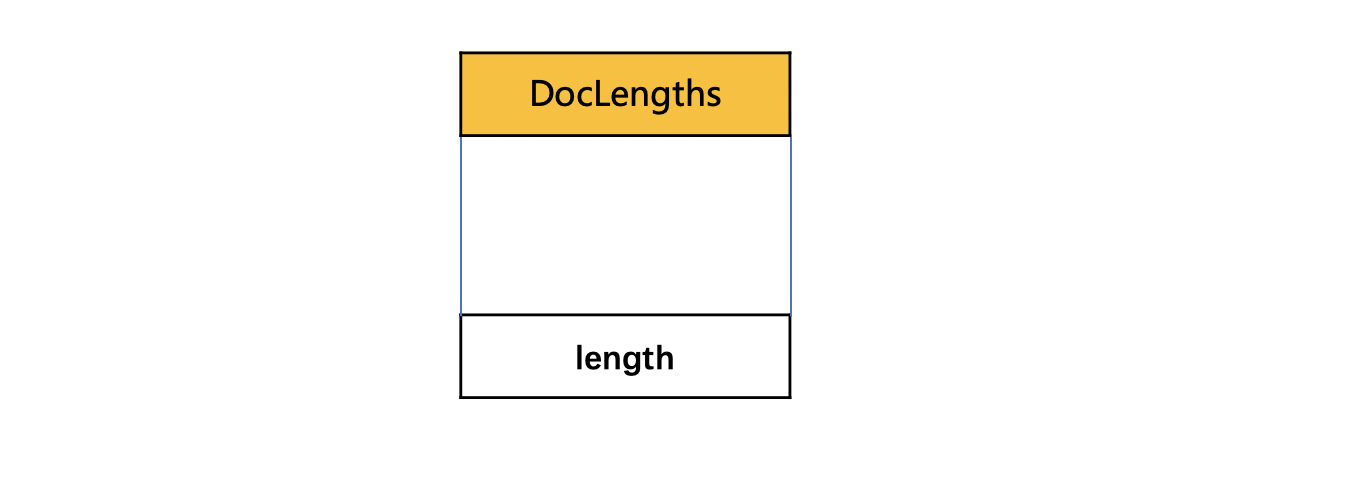
numBufferedDocs的个数> 1 并且每篇文档中的域值信息长度都是相同的
图9:
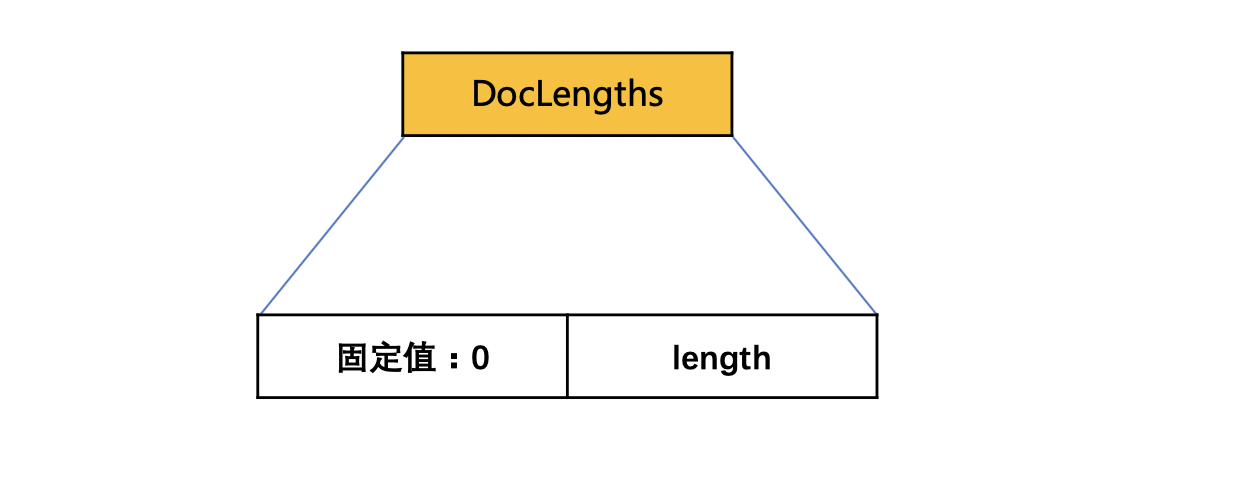
numBufferedDocs的个数> 1 并且每篇文档中的域值信息长度不都是相同的
图10:
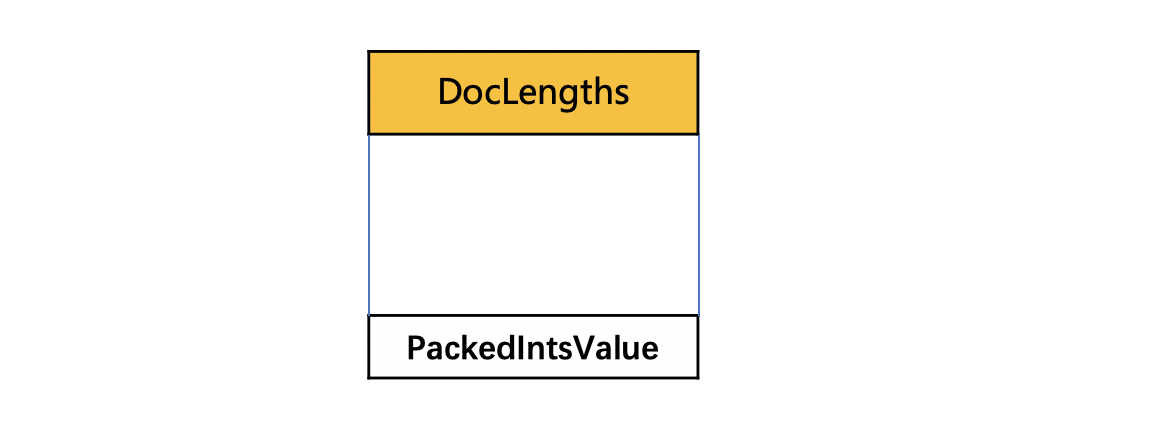
使用PackedInt来存储所有的域值信息长度,这里不赘述了,点击这里可以看其中的一种压缩方式。
CompressedDocs
图11:
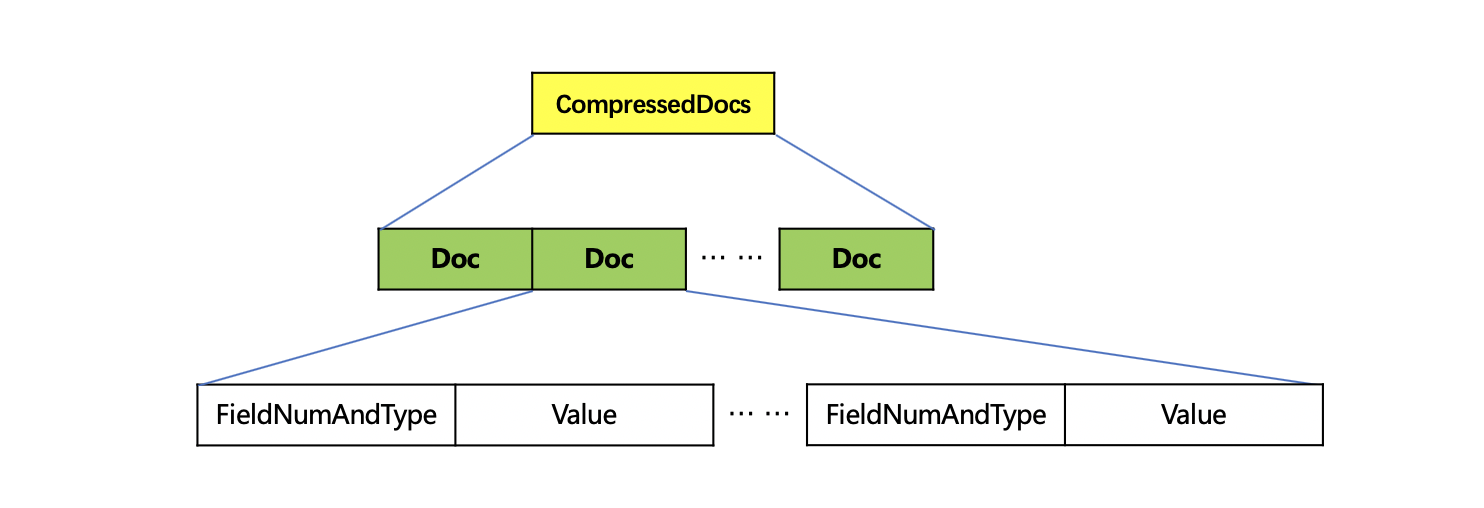
CompressedDocs中使用LZ4算法将域值信息压缩存储。域值信息包含如下内容,字段Doc的数量对应为一个chunk中包含的文档数量:
- 域的编号
- 域值的类型:String、BinaryValue、Int、Float、Long、Double
- 域值的编号跟域值的类型组合存储为FieldNumAndType
- Value:域值
ChunkCount
chunk的个数。
DirtyChunkCount
在索引阶段,如果还有一些文档未被写入到索引文件中(未满足生成chunk的条件的文档),那么在flush阶段会强制写入,并用该字段记录。
.fdt整体数据结构
图12:
索引文件.fdx
图13:
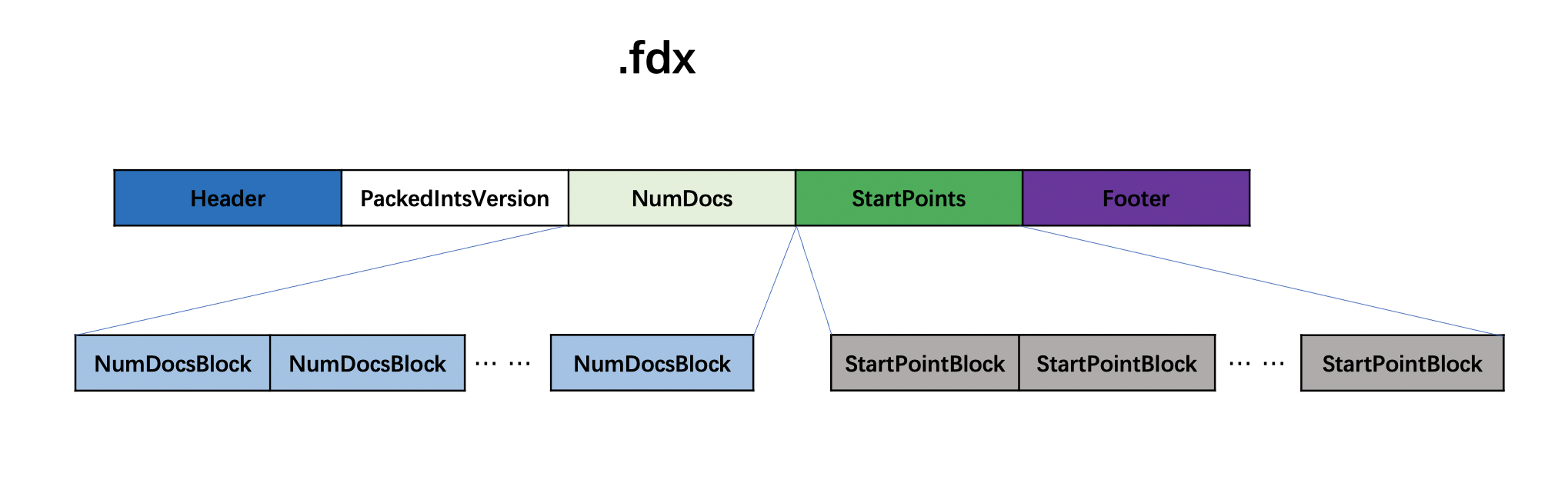
在索引文件.fdx中,每处理1024(blockShitf参数,下文会介绍)个图3中的chunk,就将chunk中的信息就生成一个NumDocsBlock和StartPointBlock,多个NumDocsBlock和多个StartPointBlock分别组成NumDocs字段以及StartPoints字段,注意的是最后一个NumDocsBlock和StartPoints中的chunk的信息数量可能不足1024个。
NumDocsBlock
该字段中的数据使用了PackedInts进行压缩。
图14:
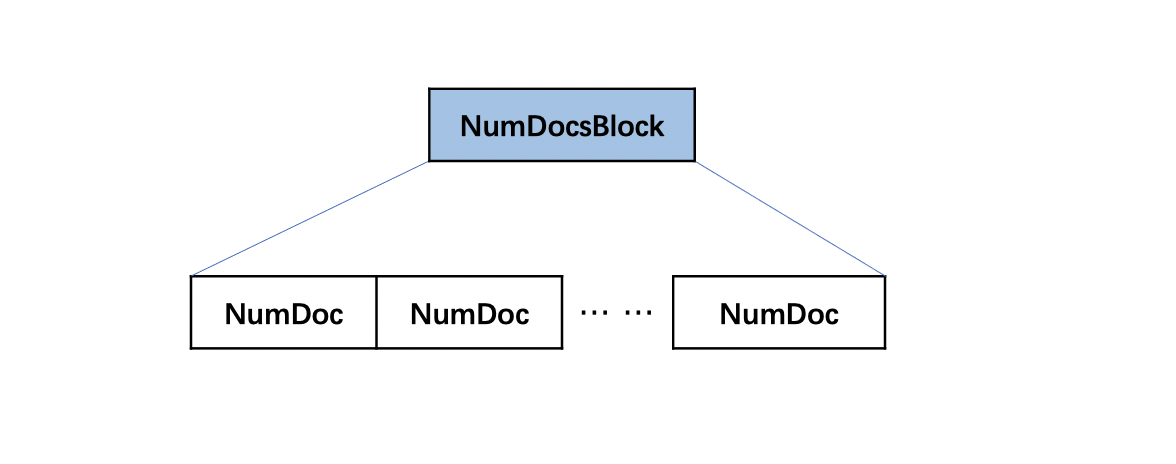
NumDoc
NumDoc描述了chunk中的文档数量。
StartPointBlock
该字段中的数据使用了PackedInts进行压缩。
图15:
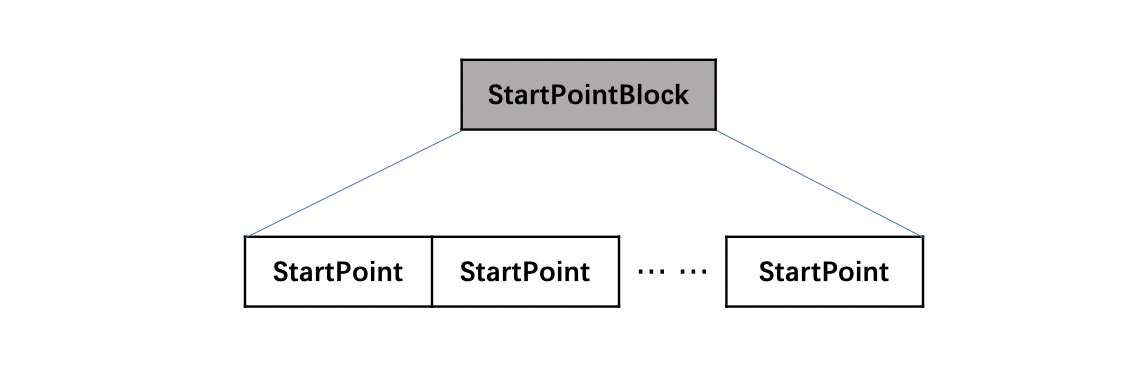
StartPoint
StartPoint描述了图2中每个chunk的信息在索引文件.fdt中的起始位置。
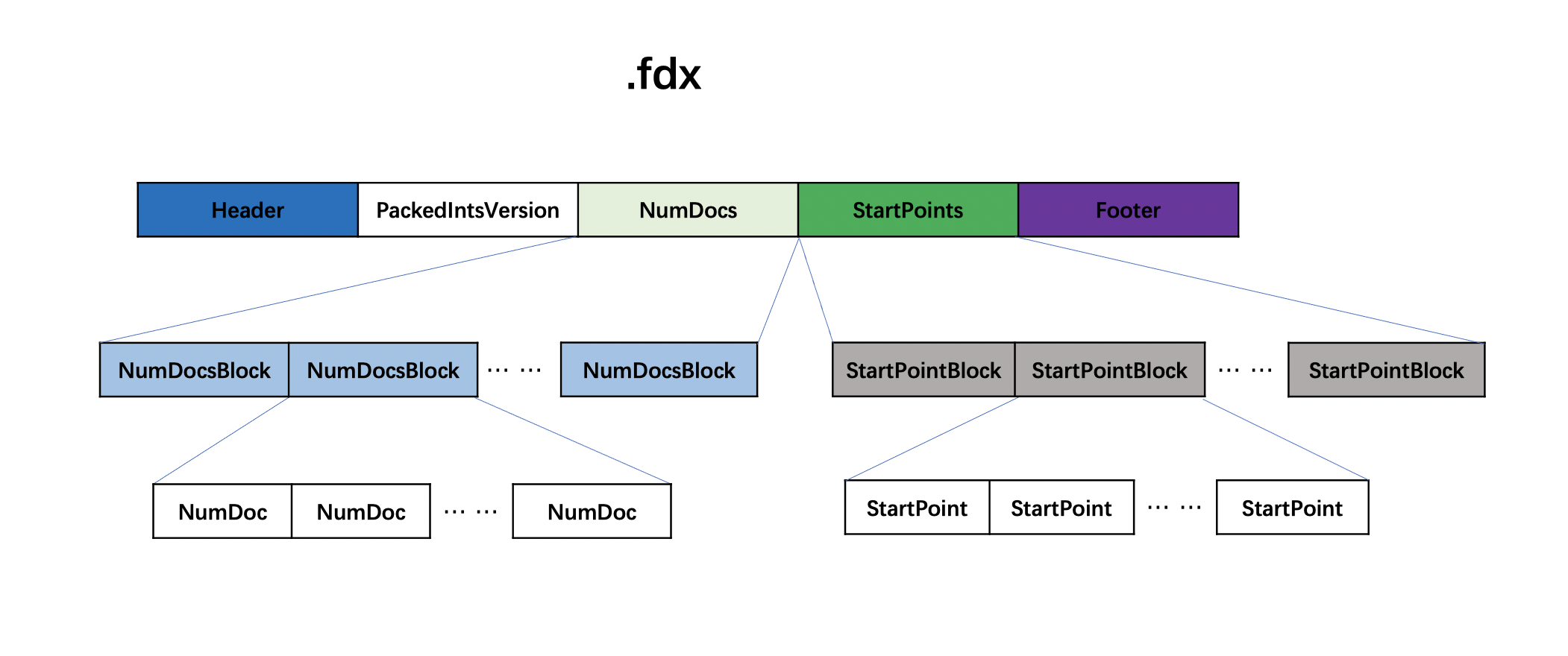
.fdx整体数据结构
图16:
索引文件.fdm
图17:

索引文件.fdm中的信息用于在读取阶段映射索引文件.fdx中的信息。
NumDocs
该字段描述了包含文档数量(无论文档是否包含存储域)。
BlockShift
该字段用来描述在索引文件.fdx中,当处理2 << BlockShitf个chunk后就生成一个NumDocsBlock或StartPointBlock,默认是10。
TotalChunks
该字段描述了图2中Chunk的数量,执行+1操作后写入到索引文件
NumDocsIndex
该字段描述了图16中NumDocs字段的信息在索引文件.fdx的起始读取位置
NumDocsMeta
该字段由多个NumDocMeta组成,其数量最多是1024(2 << BlockShitf),由于图14中的NumDocsBlock中的信息在存储过程中执行了先编码后压缩的操作(后面的文章中会展开介绍),NumDocMeta中存储了一些参数,使得在读取阶段能读取到NumDoc的原始值。
图18:
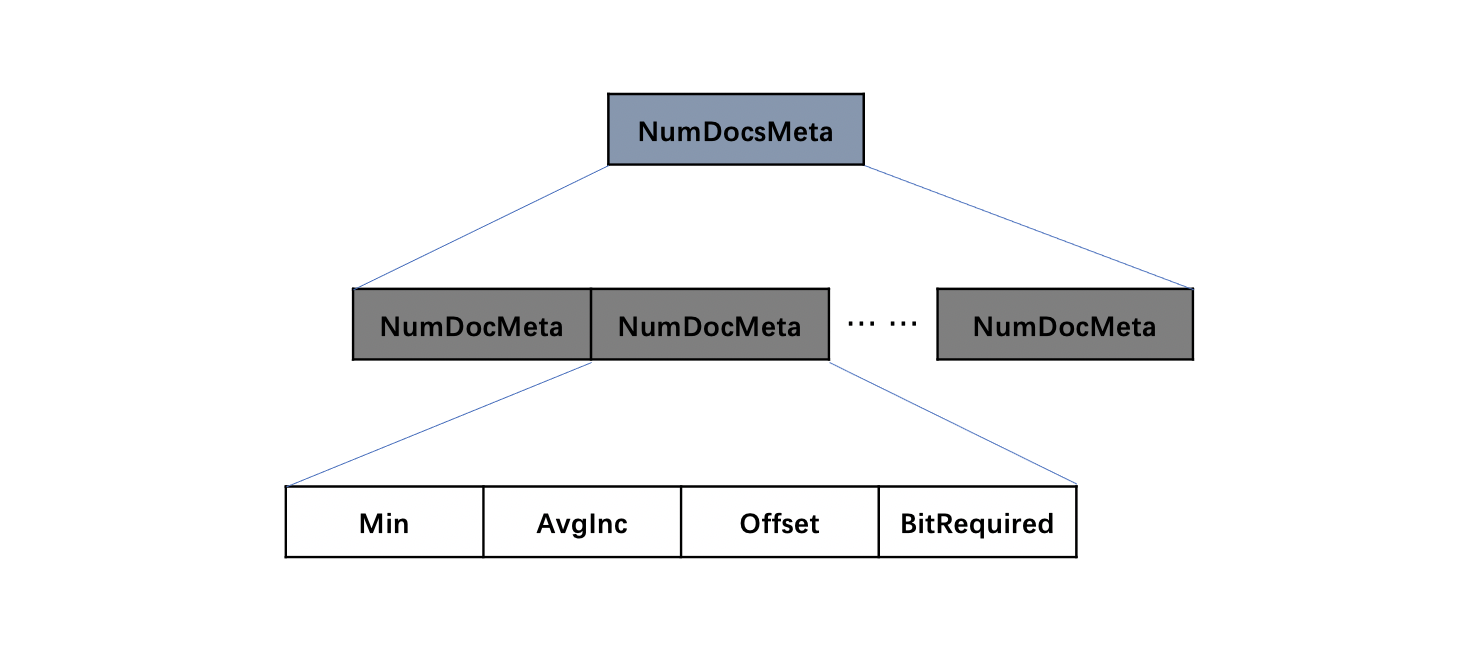
图18中Min、AvgInc、Offset、BitRequired字段的值作为参数,将会在读取阶段用于解码图14中的NumDocsBlock中的信息,本文中不展开对这些参数的介绍。
StartPointsMeta
该字段由多个StartPointMeta组成,其数量最多是1024(2 << BlockShitf),由于图15中的StartPointBlock中的信息在存储过程中执行了先编码后压缩的操作(后面的文章中会展开介绍),StartPointMeta中存储了一些参数,使得在读取阶段能读取到StartPoint的原始值。
图19:
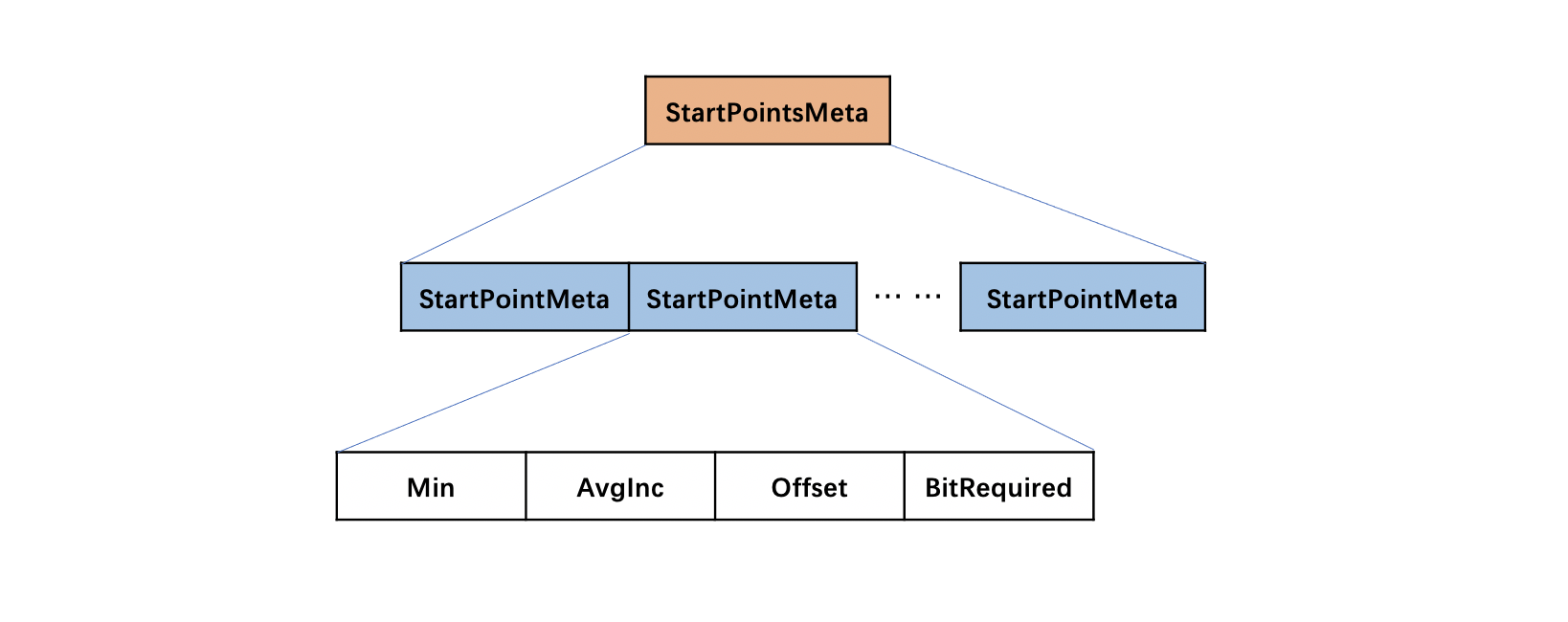
图18中Min、AvgInc、Offset、BitRequired字段的值作为参数,将会在读取阶段用于解码图15中的StartPointBlock中的信息,本文中不展开对这些参数的介绍。
SPEndPointer
该字段描述的是图16中StartPoints字段对应的数据块的在索引文件.fdx中的结束位置。
maxPointer
该字段描述的是图2中的最后一个chunk字段对应的数据块在索引文件.fdt中的结束位置。
.fdm整体数据结构
图20:
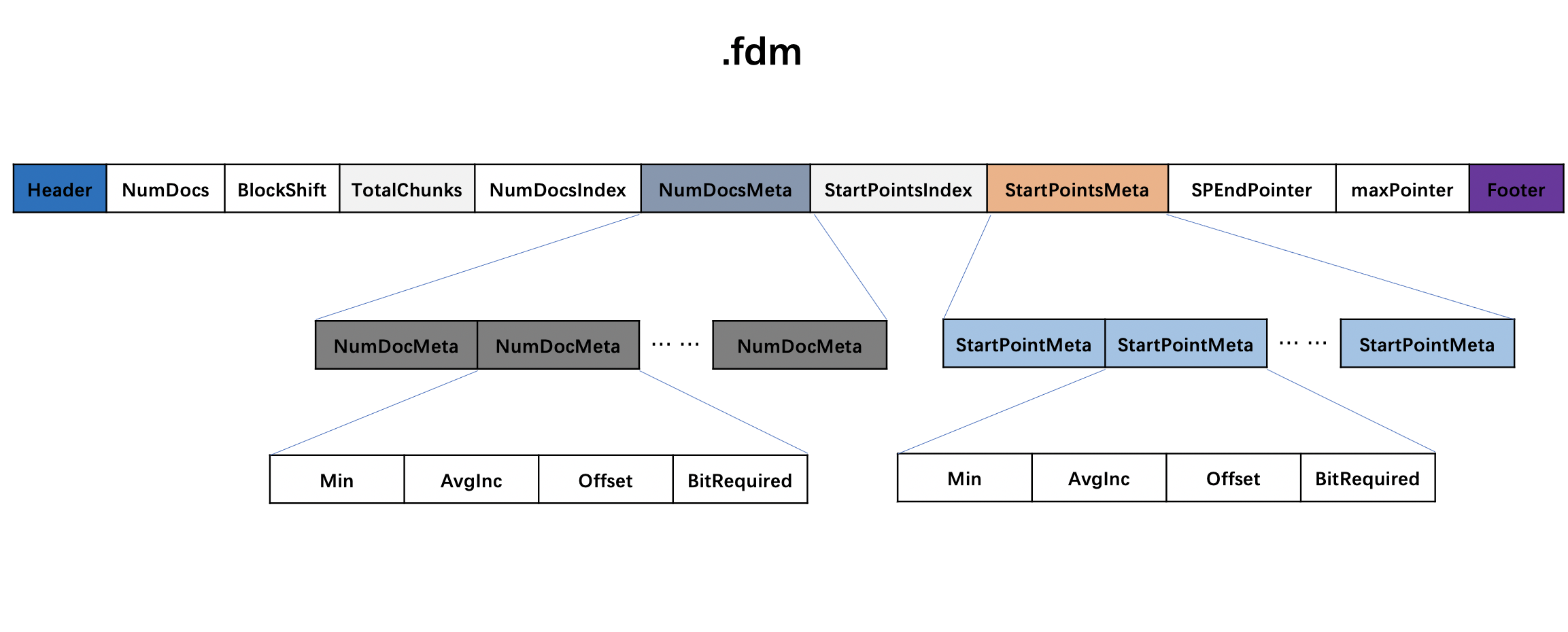
结语
看完这篇文章后,如果感到一脸懵逼, 木有关系,在随后的文章将会详细介绍索引文件fdx&&fdt&&fdm的生成过程。
点击下载Markdown文件