

从Lucene 10.0.0开始,新增了DocValuesSkipper功能,用来提高正排索引DocValues类型范围查询(SortedNumericDocValuesRangeQuery、SortedSetDocValuesRangeQuery)的遍历文档号的能力。
提出该优化的issue见:LUCENE-10396。
概述
我们以SortedNumericDocValuesRangeQuery的范围查询为例,比较优化前后遍历文档的差异:
未使用IndexSort
图1:
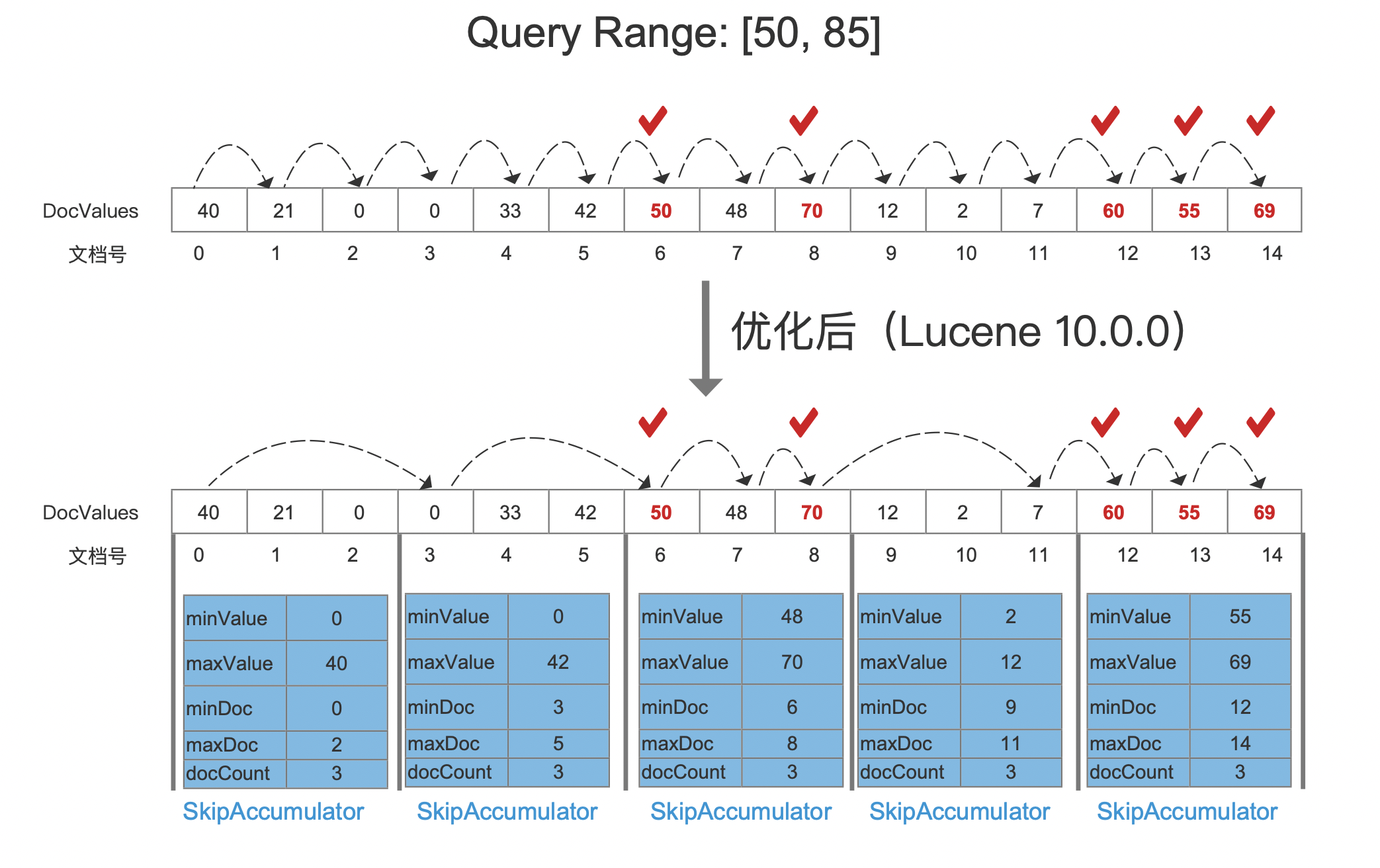
-
优化前:
SortedNumericDocValuesRangeQuery通过逐个遍历文档,然后判断每一篇文档的DocValues值是否在[50, 70]中。 -
优化后:在索引期间,每处理N(源码中为
DEFAULT_SKIP_INDEX_INTERVAL_SIZE = 4096)个DocValues生成一个SkipAccumulator的数据结构。为了便于描述,图1中每3篇文档就生一个SkipAccumulator。- 在查询期间,通过
SkipAccumulator中的minxValue和maxValue与查询范围[50, 70]比较,不在范围内的SkipAccumulator则跳过,否则就逐个遍历SkipAccumulator中的文档,判断这些文档对应的DocValues值是否在[50, 70]中
- 在查询期间,通过
使用IndexSort
没有缺失值
根据DocValus排序的前提下,如果没有缺失值(每篇文档中都有DocValues),那么只需要根据Query Range的上下界找到对应的文档号即可。
意味着文档号按照DocValues排序:
图2:
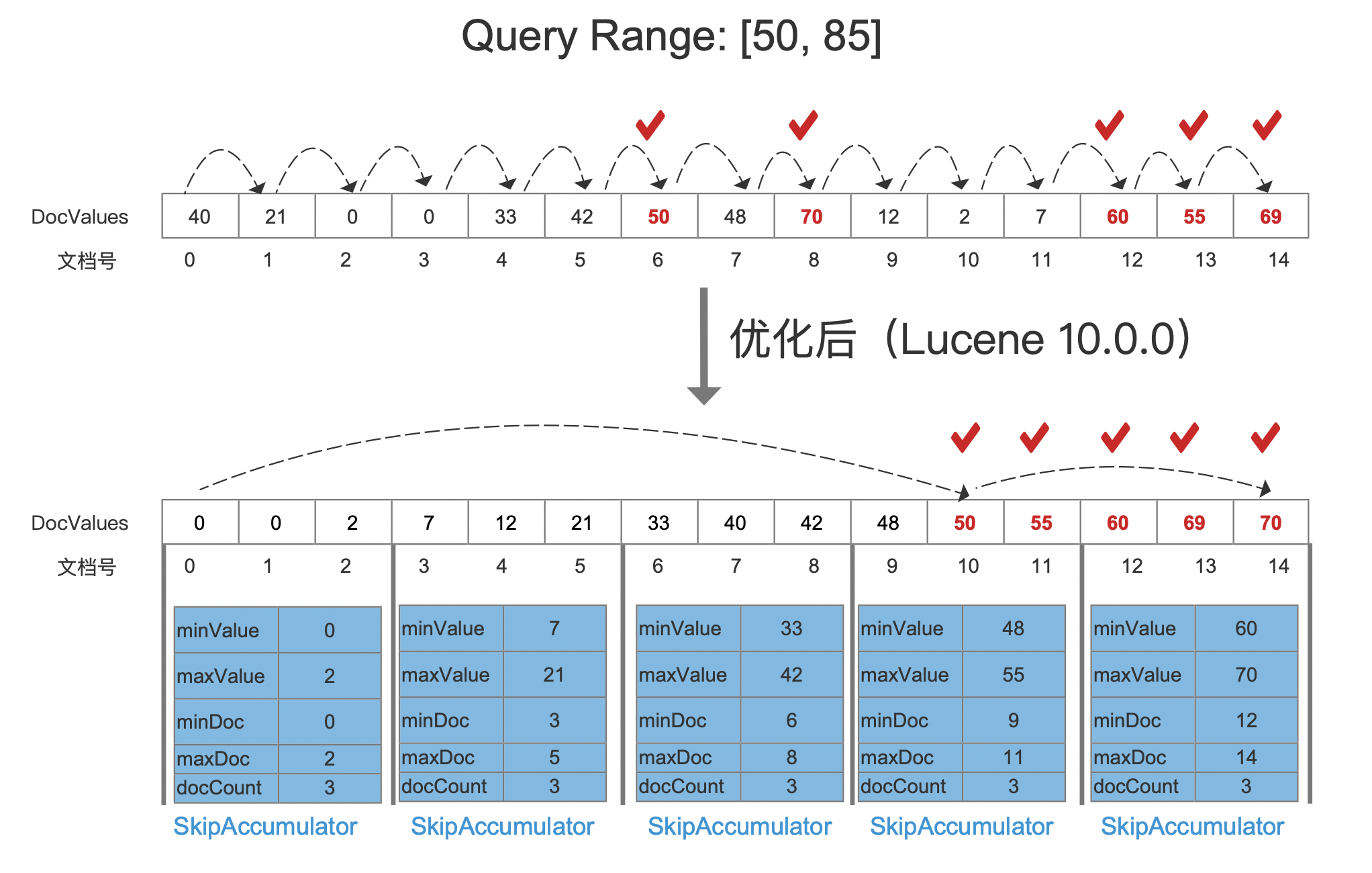
图1中,根据Query Range的上下界,分别找到对应的文档号10、14那么满足查询提交的文档号集合为[10, 14]。
存在缺失值
该场景的处理方式跟图1一致。
SkipIndex
上文中优化后的正排索引通过跳跃(Skip)实现了次线性时间复杂度的文档遍历。其原理依赖在索引期间构建的SkipIndex。我们先看下优化后的索引文件数据结构:
dvd
图3:
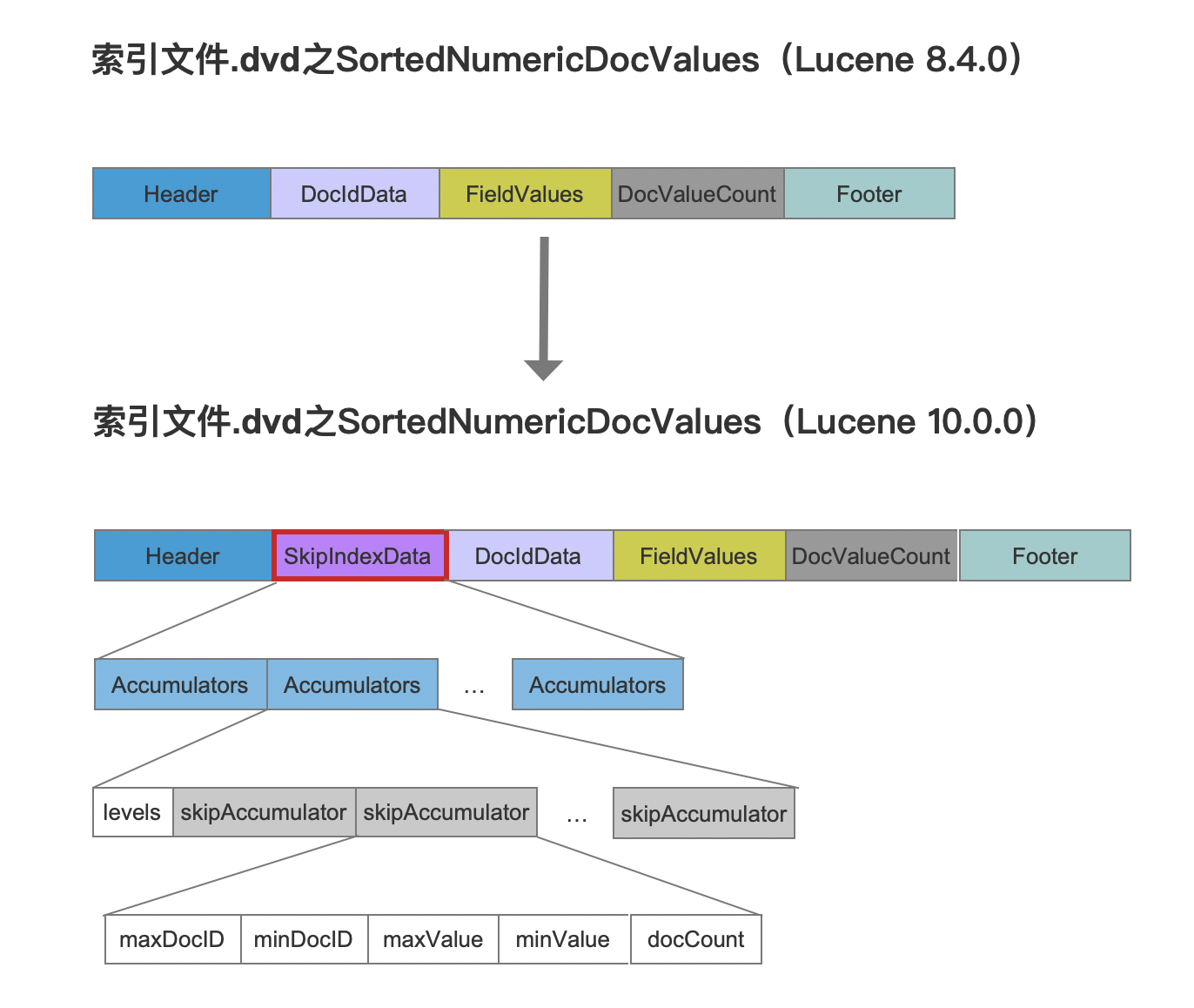
图3中,除了SkipIndexData,其他字段已在文章索引文件的生成(十七)之dvm&&dvd(Lucene 8.4.0)中介绍。
图2中SkipAccumulator即索引文件中的skipAccumulator。
新增的SkipIndexData对应的这些字段,我们暂时先不介绍,等下文中介绍跳表(skipList)时一并介绍,更容易理解。
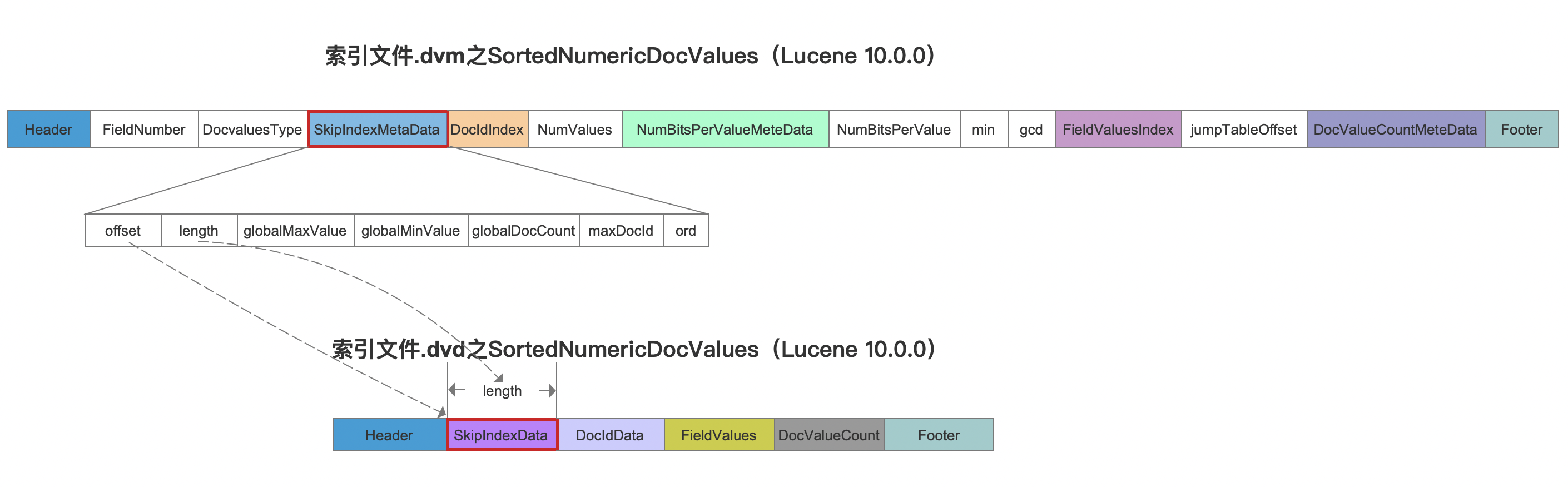
dvm
图4:
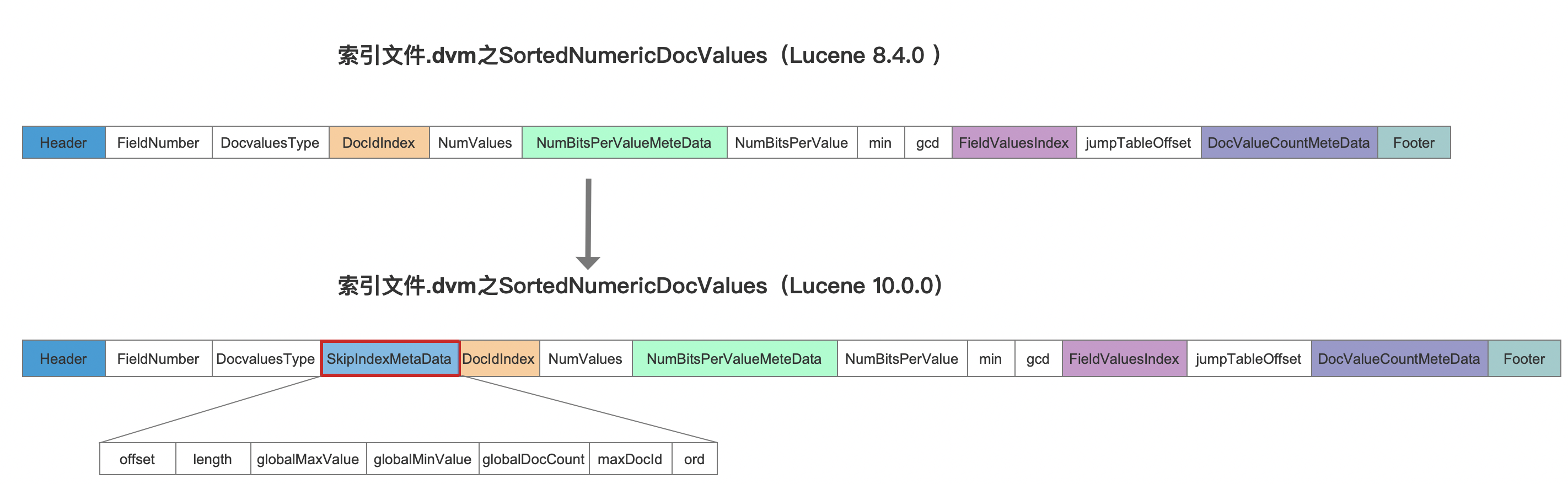
图4中除了SkipIndexMetaData字段,其他字段已在文章索引文件的生成(十七)之dvm&&dvd(Lucene 8.4.0)中介绍。
- offset、length:offset跟length用来描述在索引文件.dvd中
SkipIndexData的位置区间
图5:
-
globalMaxValue:所有文档中最大的DocValues值
-
globalMinValue:所有文档中最小的DocValues值
-
globalDocCount:包含DocValues的文档数量(可以在读取阶段用来判断是否存在缺失值:文档中没有DocValues视为缺失)
-
maxDocId:最大文档号
-
ord:布尔类型的值(ord = 1:多值)
- 某一篇文档中如果索引了某个域名的多个域值视为多值
1
2
3
4Document doc = new Document();
// 多值
doc.add(new SortedNumericDocValuesField("content", 2));
doc.add(new SortedNumericDocValuesField("content", 4));
SkipList
DocValuesSkipper通过跳表(SkipList)实现文档号的跳转,然而SkipList是一个多层的数据结构。在索引期间,每处理N(源码中为DEFAULT_SKIP_INDEX_INTERVAL_SIZE = 4096)个DocValues生成一个SkipAccumulator的数据结构。这种方式生成的SkipAccumulator被定义为属于SkipList的最底层(level = 0)。
- 为了便于描述,文章中每处理
2个DocValues后生成一个SkipAccumulator。
图6:

随后每当生成1 << SKIP_INDEX_LEVEL_SHIFT(源码中SKIP_INDEX_LEVEL_SHIFT的值为3,那么1 << 3 = 8)个SkipAccumulator后,则在level = 1层生成一个新的SkipAccumulator,并且合并这8个SkipAccumulator中的信息:
- 为了便于描述,文章中每处理2个
SkipAccumulator,则在新的层级中生成一个新的SkipAccumulator
图7:

同样的在level = 1中,每处理2个SkipAccumulator就要再新的层级中生成一个新的SkipAccumulator,依次类似,最后的跳表如下所示:
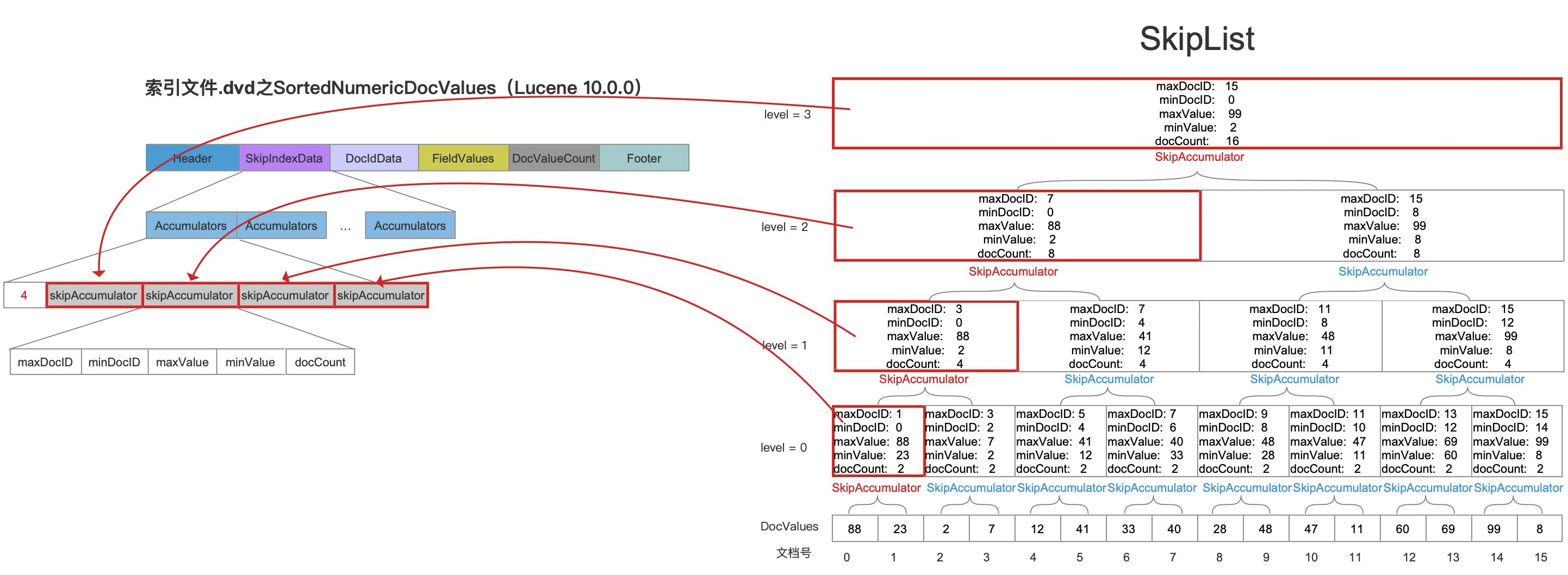
图8:
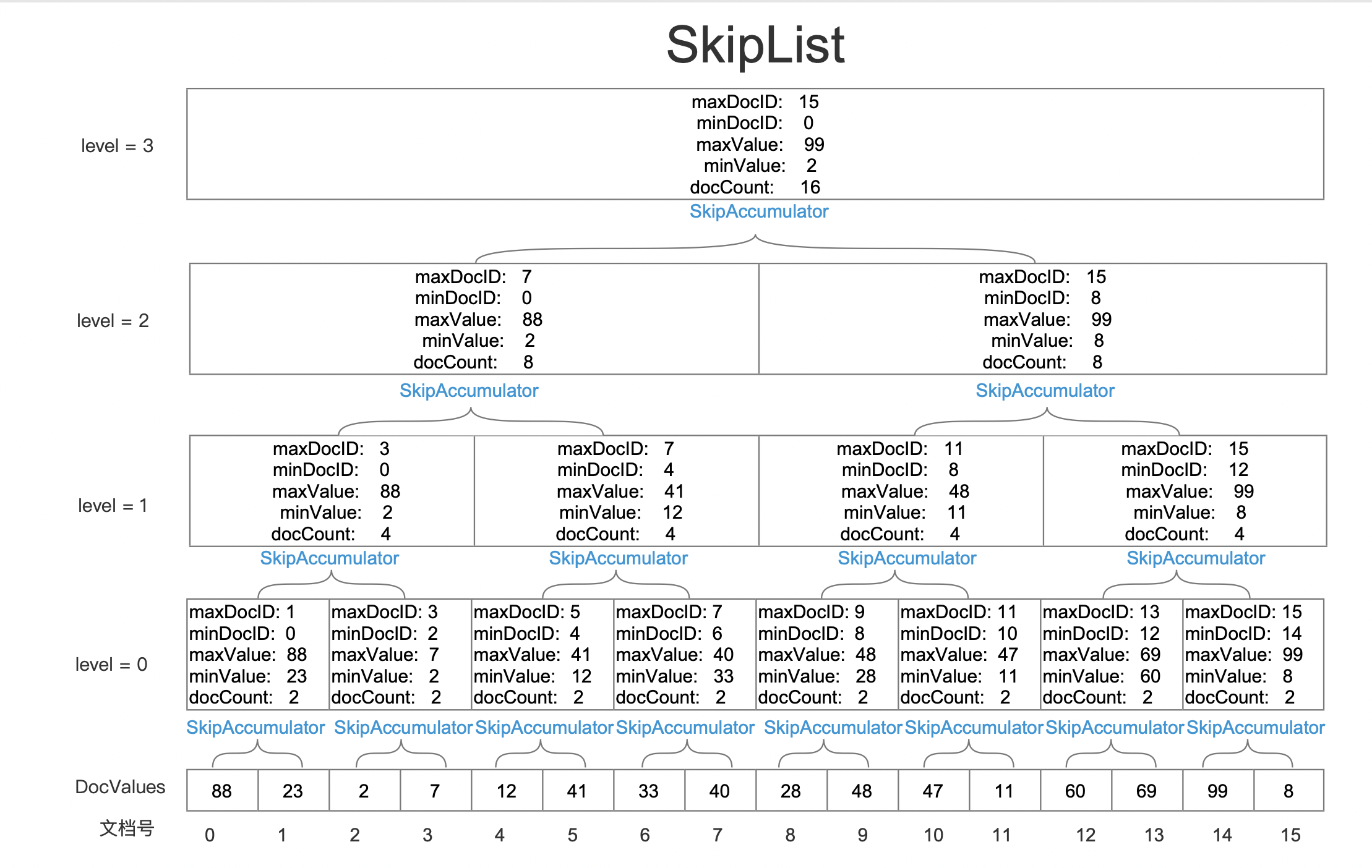
源码中,定义了参数SKIP_INDEX_MAX_LEVEL,限制SkipList的最大层数为4,并且要求每处理8个SkipAccumulator生成一个新的SkipAccumulator。因此在level = 0 层,最多有512个SkipAccumulator。
将图8中写入到索引文件.dvm中,其字段对应关系如下:
图9:
结语
本篇文章简单介绍了DocValuesSkipper加强DocValues的范围查询遍历能力的机制,SkipList以及正排索引文件的变化。然而如何通过SkipList实现跳转并未体现在文中。DocValuesSkipper是一个刚刚上线的功能(2024年10月14日随着Lucene 10.0.0发布),相信该功能还会进一步优化迭代,作者准备等待后续几次新版本后再来介绍。