

概述
在OLAP系统,尤其在大数据分析和决策支持系统中,获取某个查询对应的命中数量(也称为查询结果的计数),即count是一个非常重要的指标。本篇文章将介绍Lucene中count功能的实现原理,以及该功能的部分演进历程。
Lucene提供了IndexSearcher#count(Query query)方法来获取某个查询的count,实现方式为在收集器Collector(具体实现为TotalHitCountCollector)中累加匹配到的文档数量。
TotalHitCountCollector(Lucene 8.10.0)
TotalHitCountCollector专门用来统计命中的文档数量,它不会处理任何其他事情。实现非常简单,所以我们直接贴出代码:
图1:
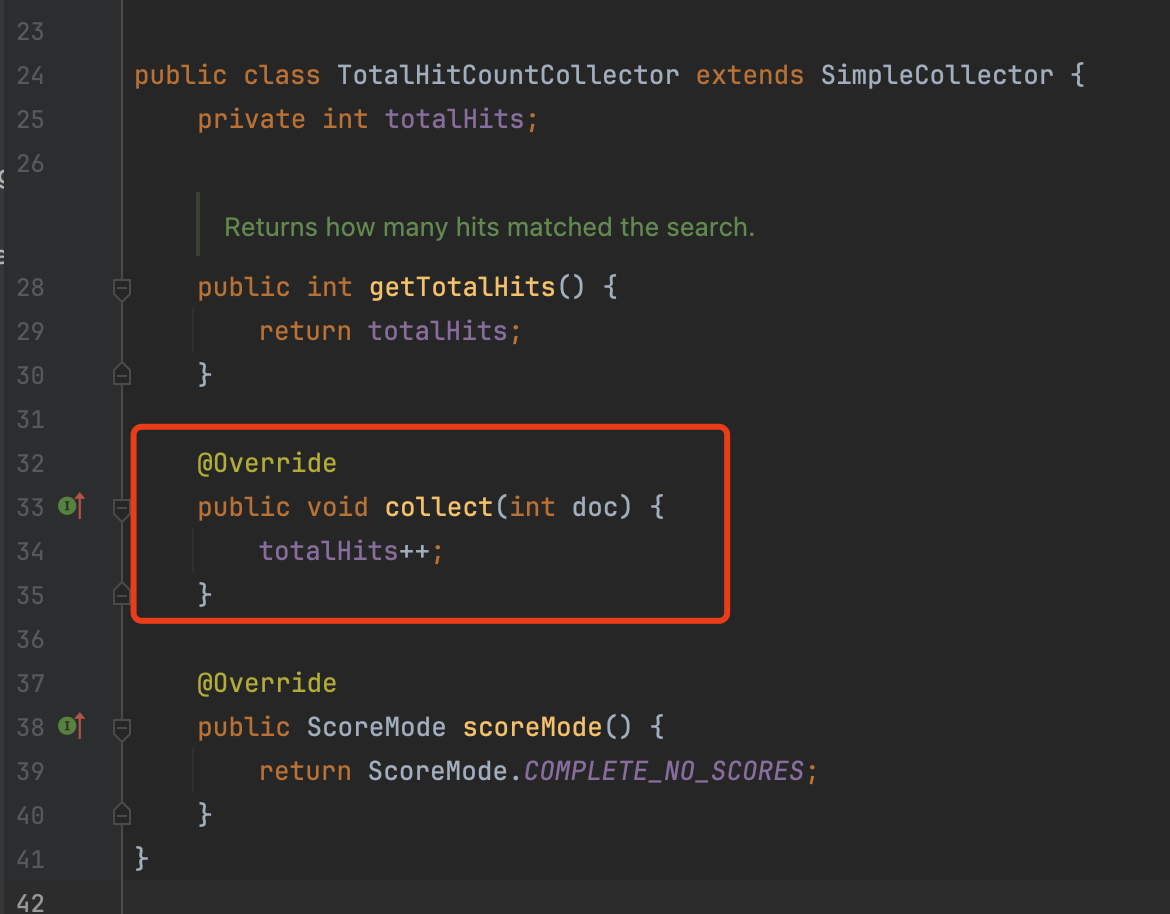
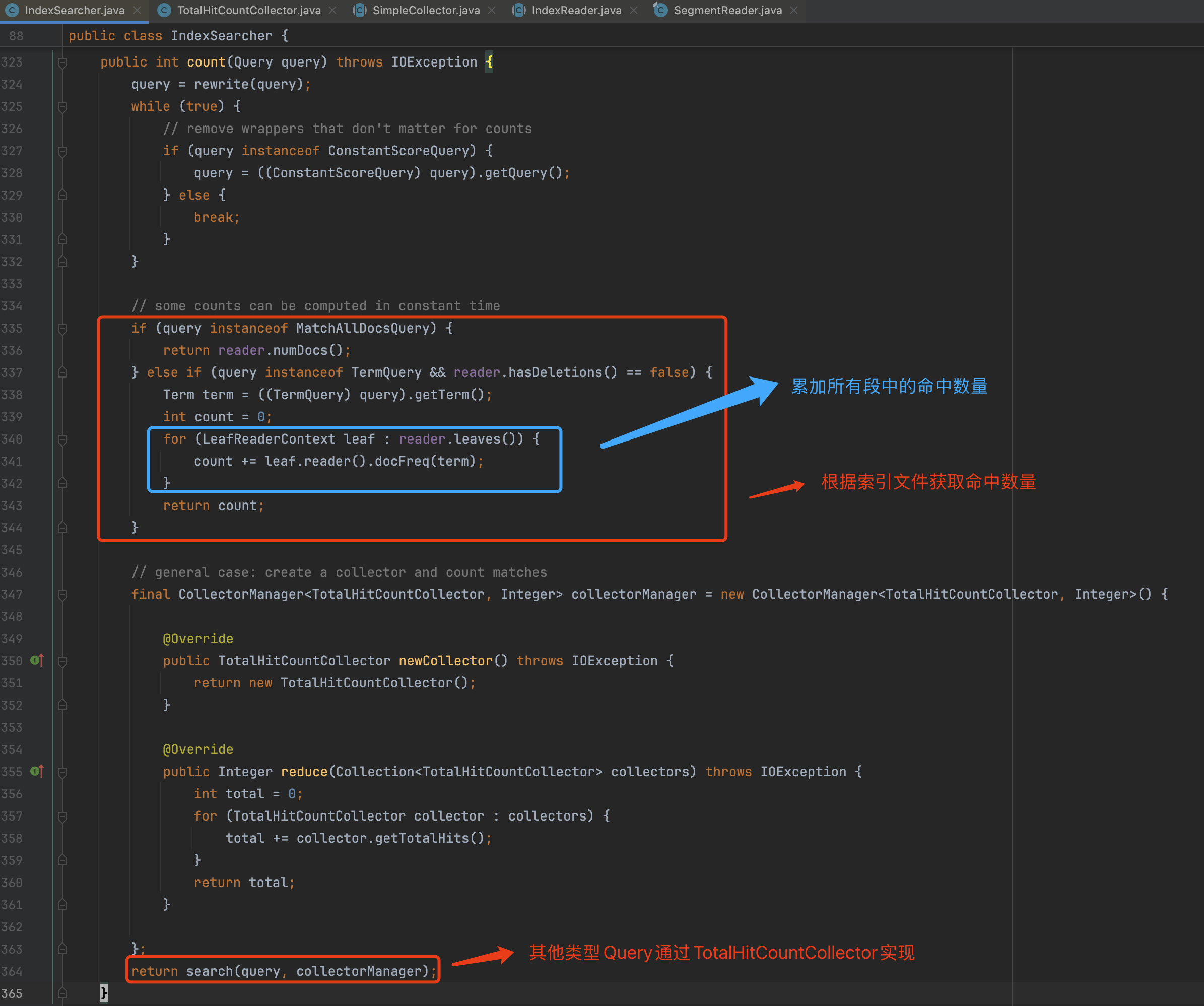
然而累加匹配这种方式存在一个问题:获取count的响应时间与命中的文档数量成正比,因为在Collector中,它是逐个处理文档的(见图1中红框方法)。但是有些Query,例如MatchAllDocsQuery、TermQuery,它们获取count的时间不会受到数据量的影响,能在一个相对固定时间(constant time)内计算出count。因为count的信息被记录在索引文件中,所以直接读取索引文件对应的字段就行了。
TermQuery
通过索引文件.tim中DocFreq字段获取count,如下所示。
图2:
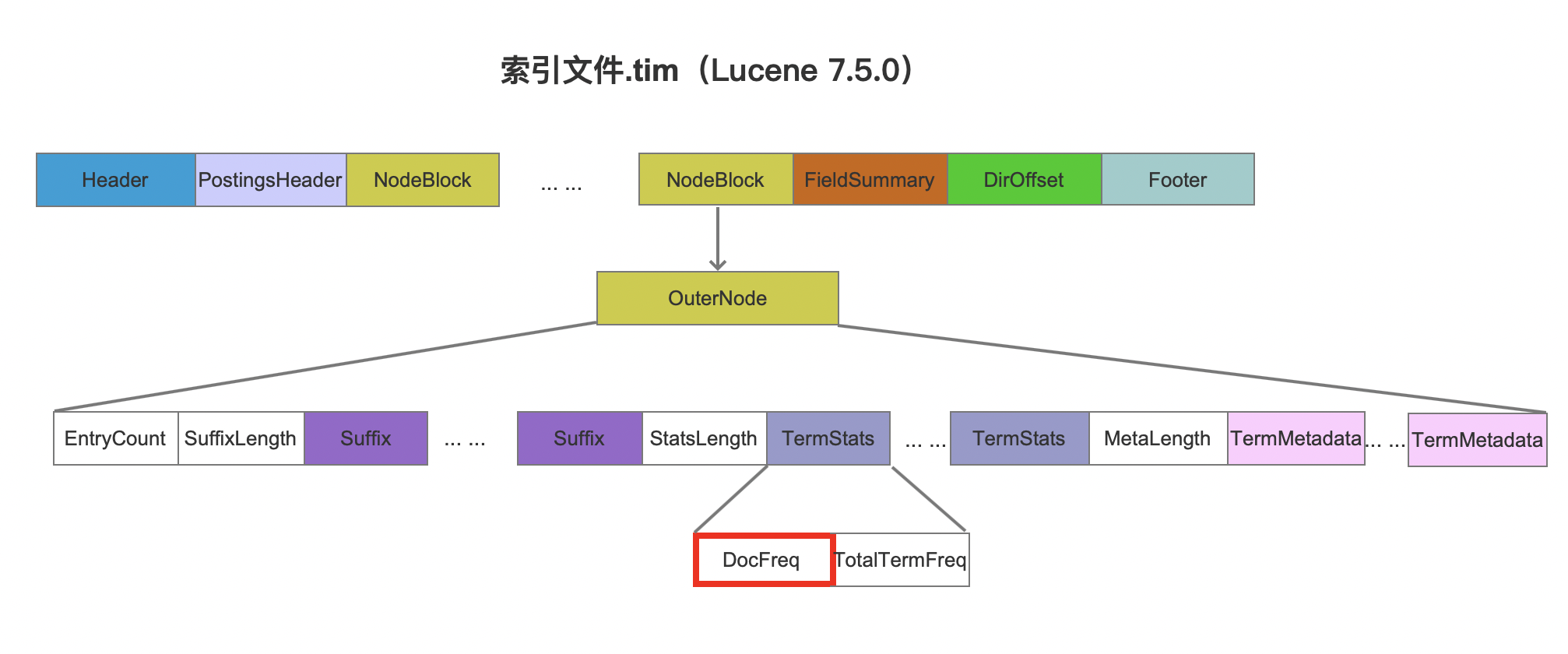
图1中DocFreq描述的是某一个段中某个字段的count,因此如果索引中有多个段,那么需要累加所有段中的DocFreq。
注意的是,如果段中存在被删除的文档,那么就不能通过DocFreq获取count,因为不能确定当前term是不是属于被删除的文档中。
MatchAllDocsQuery
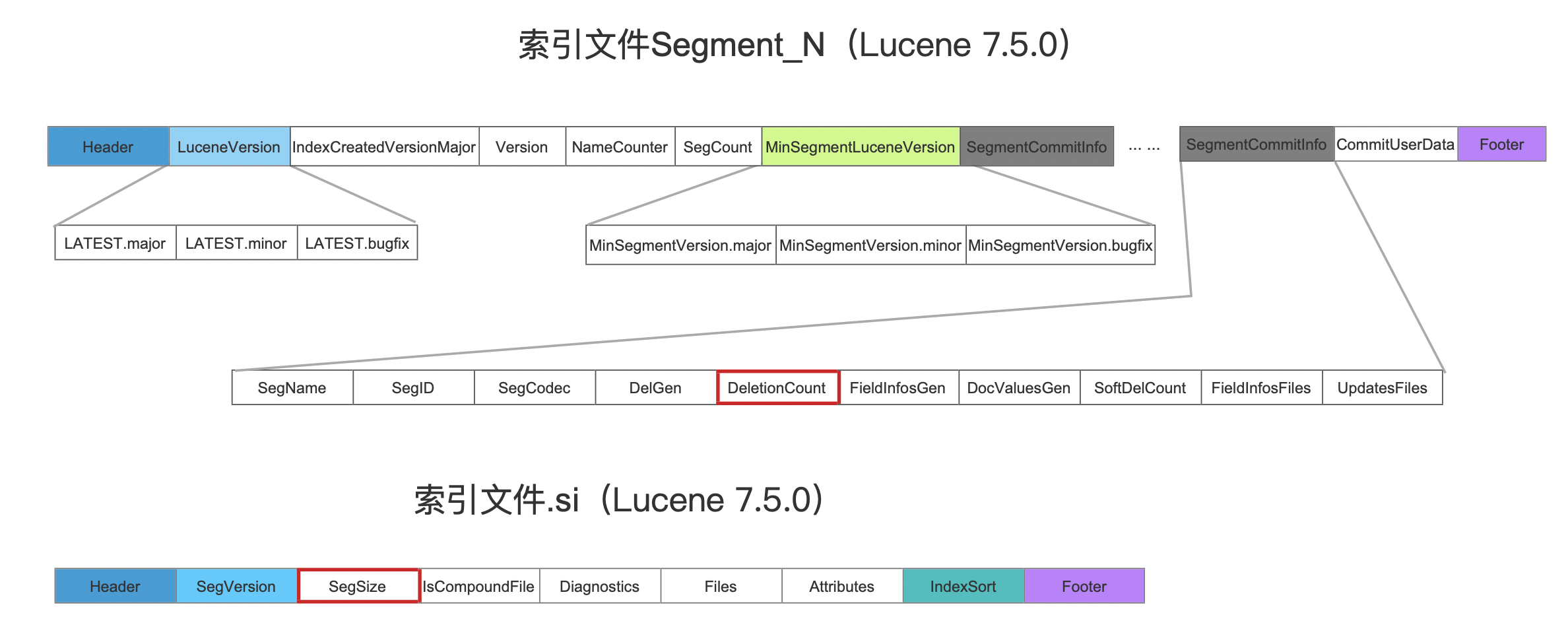
这个Query分别通过索引文件segments_N中的DeletionCount字段以及索引文件.si中的SegSize字段来获取count。其中DeletionCount描述的是某一个段中被标记为删除的文档数量,SegSize描述的是某一个段中文档总数。因此这两个字段的差值即命中数量count:
图3:
IndexSearcher#count(Query query)方法中实现了TermQuery以及MatchAllDocsQuery快速获取命中数量的逻辑,也就是说它不需要通过Collector来逐个累加命中的文档数量:
图4:
TotalHitCountCollector(Lucene 9.2.0)
Lucene后续提交了两个变更:LUCENE-9620以及LUCENE-10620,进一步增强了count功能:
- LUCENE-9620:在
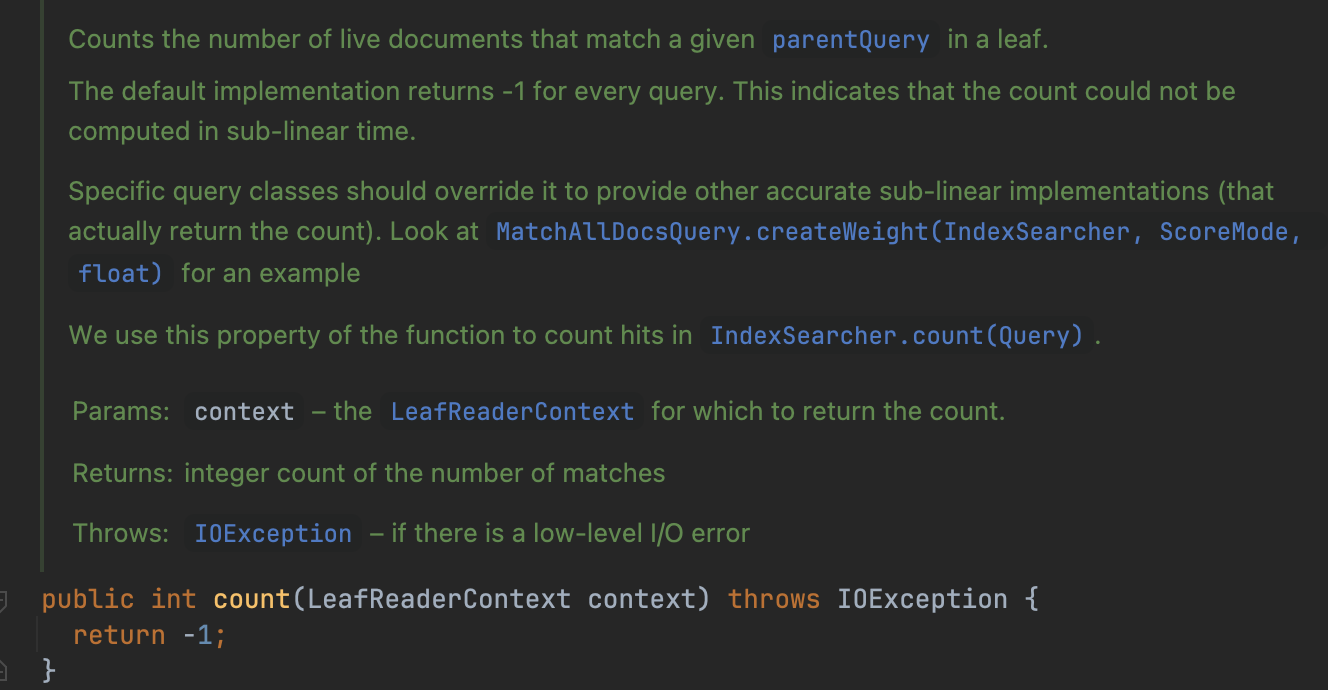
Weight中新增了int count(LeafReaderContext context),它为每一种Query提供了一个抽象方法,如果这个Query能以次线性时间复杂度(sub-linear)计算出count,则不需要通过TotalHitCountCollector这种需要线性时间复杂度的方式。很明显上文中提到TermQuery跟MatchAllDocsQuery是能做到的,然后还有一些Query在某些特定场景下也是能做到的,在下面的文章中会介绍这些Query的实现方式。下面顺便贴出这个方法的注释:
图5:
- LUCENE-10620:这个变更将
Weight传入到Collector中,其变更原因大家自行看下这个链接,但其中一个跟本篇文章相关的理由就是可以统一所有类型Query计算count的逻辑,也就是在TotalHitCountCollector中统一处理,并且不影响原有的时间复杂度
对比图4中IndexSearcher#count(Query query)的实现方式,变更后的代码如下所示:
图6:

顺便简单介绍下图6中`TotalHitCountCollectorManager,它只有一个作用:累加在所有段中的命中数量:
图7:
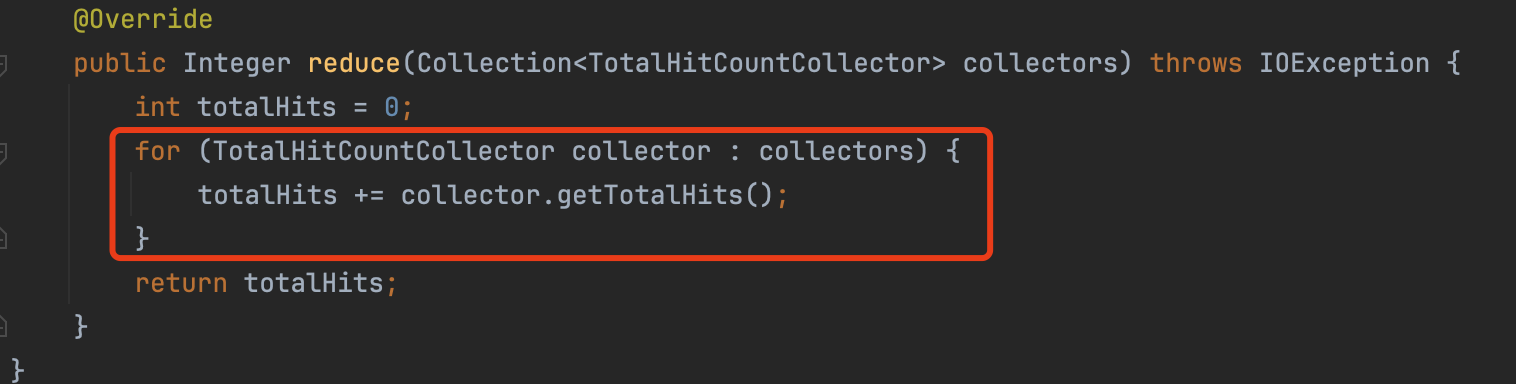
图7中,每一个段通过TotalHitCountCollector统计count,累加后的totalHits就是某个Query在索引中的命中数量
TotalHitCountCollector的变更
这段没有查询原理的知识可能会看不懂,可以跳过
接下来我们看下TotalHitCountCollector的变化:
图8:
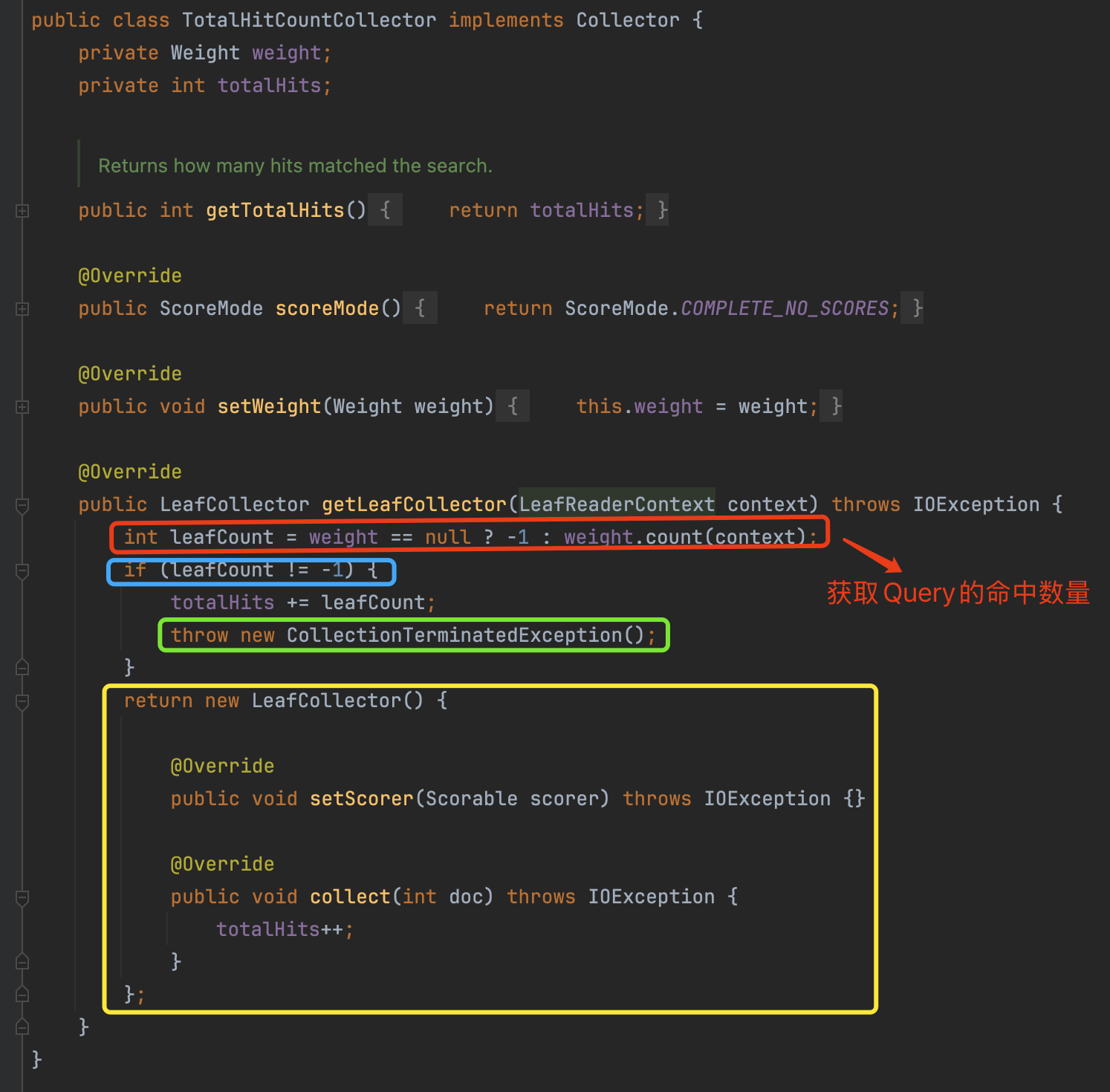
- 红框标注:通过
Weight#count(LeafReaderContext context)方法尝试获取count - 蓝框标注:如果返回值为
-1,说明这个Query不能以次线性复杂度········计算count - 绿框标注::由于我们已经获取到
count,通过抛出一个异常的方式,结束这个段的处理,也就是不需要进行后续的Collector阶段(如果看不明白就算了,需要一些前置知识,可以简单) - 黄框标注::提供8.10.0版本的
TotalHitCountCollector,通过累加匹配到的文档数量计算count
次线性时间复杂度的Query
上文中我们提到,Weight为每个Query提供了int count(LeafReaderContext context)的抽象方法,如果能在次线性时间复杂度实现这个方法,那么计算Query的count时就不需要通过累加匹配到的文档数量。
除了TermQuery以及MatchAllDocsQuery,接下来介绍下几个能实现次线性时间复杂度的一些Query。
BooleanQuery
BooleanQuery由一个或多个子Query组成,并且每个子Query可以有SHOULD、MUST、MUST_NOT、FILTER这种四种属性的任意组合,BooleanQuery只能在部分场景下以次线性时间复杂度统计count。出于篇幅考虑,我们只介绍所有子Query都是SHOULD的情况:
- 所有子Query都是
SHOULD- 如果所有的子Query都没有匹配到文档,那么BooleanQuery的
count == 0 - 如果至少有一个子Query能匹配到段中所有的文档,那么BooleanQuery的
count = ALL(不包含被删除的文档) - 如果有一个子Query匹配到
N,其中0 < N < ALL,并且其他所有的子Query都没有匹配到文档,那么BooleanQuery的count == N
- 如果所有的子Query都没有匹配到文档,那么BooleanQuery的
其他情况因为实现代码量很少,建议自行阅读BooleanWeight#count(LeafReaderContext context)的源码。
PointRangeQuery
PointRangeQuery用于数值类型数据的范围查询。快速统计PointRangeQuery的count的逻辑仍然是深度遍历二叉树的方式。差别在于在处理某个内部节点时,如果它的子节点中的最大跟最小值在查询条件的区间内,那我们就不需要通过深度遍历方式处理这些子节点,直接根据它包含的叶子节点的数量就可以统计出count。
图9:
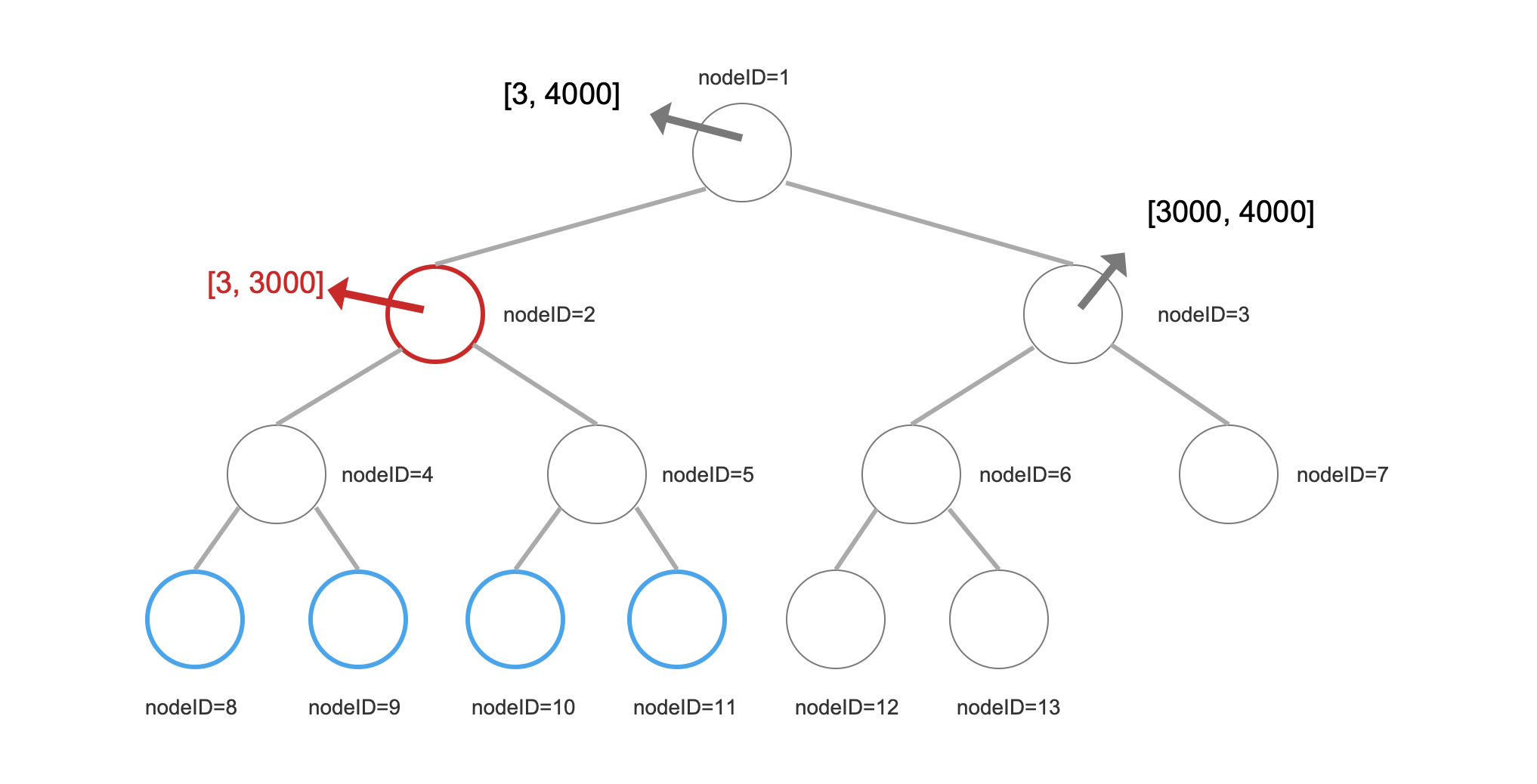
图9中,根节点,即nodeID=1的节点,在写入时将[3, 3000]划分为左子树,[3000, 4000]划分为右子树。
如果查询条件范围为[1, 3500],那么从根节点开始遍历,当深度遍历到nodeID=2时,就不需要继续往下遍历,因为这个节点中最大和最小值都被包含在查询条件中,那么此时我们只需要按照以下步骤就可以很快的计算出count
-
第一步:根据节点编号计算出最左节点跟最右节点的编号
- 左节点的nodeID等于父节点的
nodeID * 2,右节点的nodeID等于父节点的nodeID * 2 + 1- 内部节点编号nodeID=2,那么结果分别是nodeID=8、nodeID=11。
- 左节点的nodeID等于父节点的
-
第二步:某个内部节点下所有叶子结点中的元素数量即:(最右节点编号 - 最左节点编号 + 1) *
maxPointsInLeafNode。- maxPointsInLeafNode:由于除了最后一个叶子结点(nodeID=13,见LUCENE-9087),其他的叶子节点中的元素数量总是为固定值(源码中该值为512)
- 这里简单提一下,自从Lucene 8.6.0之后,BKD不总是生成一颗满二叉树。
- 对于图9中的例子,nodeID=2的内部节点下所有叶子结点中的元素数量为:(11 - 8 + 1) * 512
- maxPointsInLeafNode:由于除了最后一个叶子结点(nodeID=13,见LUCENE-9087),其他的叶子节点中的元素数量总是为固定值(源码中该值为512)
目前PointRangeQuery的count功能只支持一维点数据。
从上文的描述可以得知,还是得通过遍历二叉树的方式,这是因为该实现用于通用场景。在一些特定场景中统计数值类型数据的范围查询的count则可以使用IndexSortSortedNumericDocValuesRangeQuery,其性能更好。
IndexSortSortedNumericDocValuesRangeQuery
可以看下这篇文件IndexSortSortedNumericDocValuesRangeQuery简单了解下这个Query的作用。
在执行数值类型数据的范围查询时,如果查询期间的排序规则跟索引写入(IndexSort)的排序规则是一致的,那么使用IndexSortSortedNumericDocValuesRangeQuery会比PointRangeQuery有着更好的性能。我们看下这个Query的count是如何实现的。
目前有两种方式实现:BKD以及DocValue,但无论是那种方式,前提条件必须索引是有序的,第一个排序规则对应的field必须跟查询条件的域相同。
- 这意味着文档号的先后顺序就是字段值的先后顺序。
两种实现方式都是通过查询条件中上下边界值对应的文档号差值实现。很明显,如果有文档中有缺失值,则无法获取count,那么就委托给PointRangeQuery。BKD相对于DocValue方式性能更高,因此优先考虑基于BKD获取count,如果无法获取则再次尝试基于DocValue方式。
下面内容中,我们将查询条件中上下界值分别称为upperValue、lowerValue。
BKD
由于文档号跟数据有相同的排序顺序,因此我们只需要找到lowerValue和upperValue对应的文档号minDocId、maxDocId即可,那么即count的值为maxDocId - lowerValue 。
也就是说,在深度遍历的过程中,我们直接遍历到叶子节点并找到对应的文档号,也就是最多访问两个叶子节点即可。
图10:
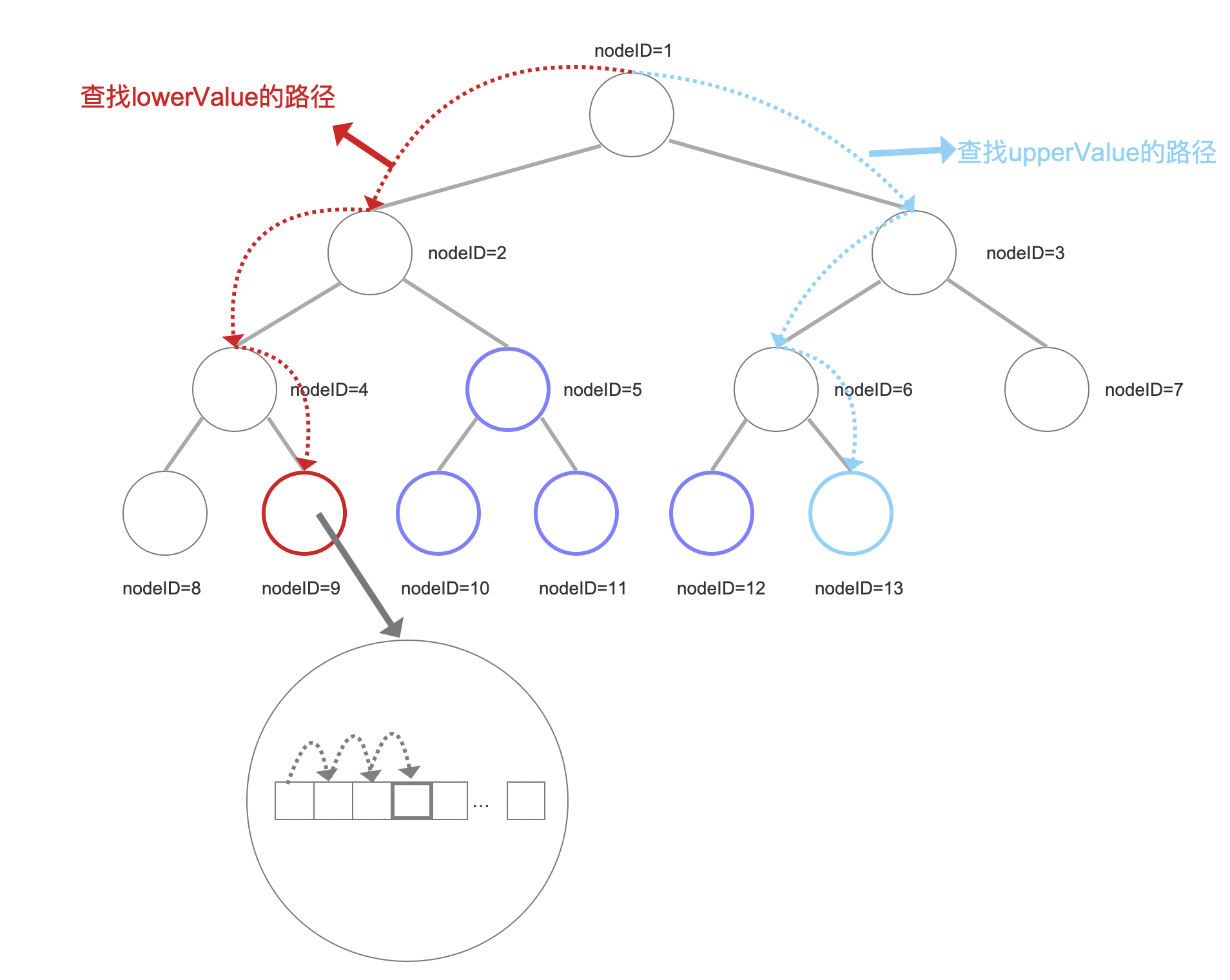
图10中,我们需要遍历两次二叉树来分别获得lowerValue和upperValue对应的文档号minDocId、maxDocId。
对于lowerValue来说,当遍历到叶子节点(nodeID=9)时,继续在叶子结点中通过顺序遍历找到lowerValue以及对应文档号。
相比较PointRangeQuery中的逻辑,这里不需要处理图10中蓝框标注的节点。
局限性
如果满足以下任意一个条件,则无法通过这种方式获取正确的count
- 点数据的维度大于一维
- 每个文档中,不能索引这个字段的多个值
1 | Document doc = new Document(); |
DocValue
这种方式通过二分法分别找到查询条件中上下界值(分别称为)对应的文档号。
以lowerValue为例,我们最先使用段中最小跟最大文档号,即0、maxDoc作为二分法的开始,找到其中间值mid,然后基于DocValue,以0(1)的复杂度找到文档号mid对应的值(利用了正排索引中根据文档号找值的特点),与lowerValue比较,然后进行下一步二分法,直到直到lowerValue对应的文档号。
接着以相同的方法找到upperValue对应的文档号即可,两个文档号的差值即count。
结语
无