

QueryCache是一个用于缓存查询结果的组件,旨在提高重复查询的性能。它通过在段级别缓存查询结果,避免了重复计算,从而减少查询响应时间和系统资源消耗。
数据结构
在介绍QueryCache的缓存逻辑之前,我们有必要先介绍下几个关键的数据结构。
CacheAndCount
QueryCache仅仅缓存命中的文档ID集合以及文档总数。在源码中,使用CacheAndCount描述缓存的内容:
图1:
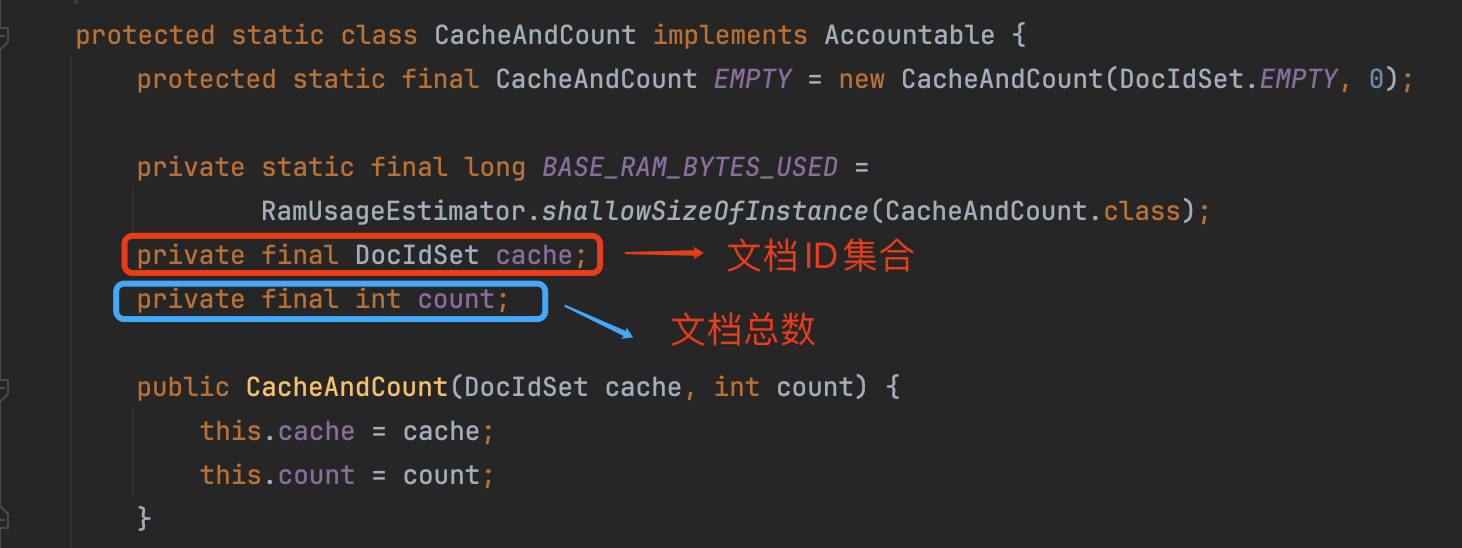
通过文档ID集合可以计算出文档总数,为什么还要额外记录count?
在OLAP系统中,计算命中的数量是一个常用的指标。Lucene在LUCENE-9620新增了count接口,在一些特定的场景中,计算命中数量不需要逐个遍历匹配到的文档。比如在TermQuery中,可以直接通过索引文件.tim中的docFreq字段获取,而不需要找到所有满足查询的文档号并且计算出总数。当然使用这个接口有一定的限制,具体内容将在以后的文章中介绍count接口。
图2:
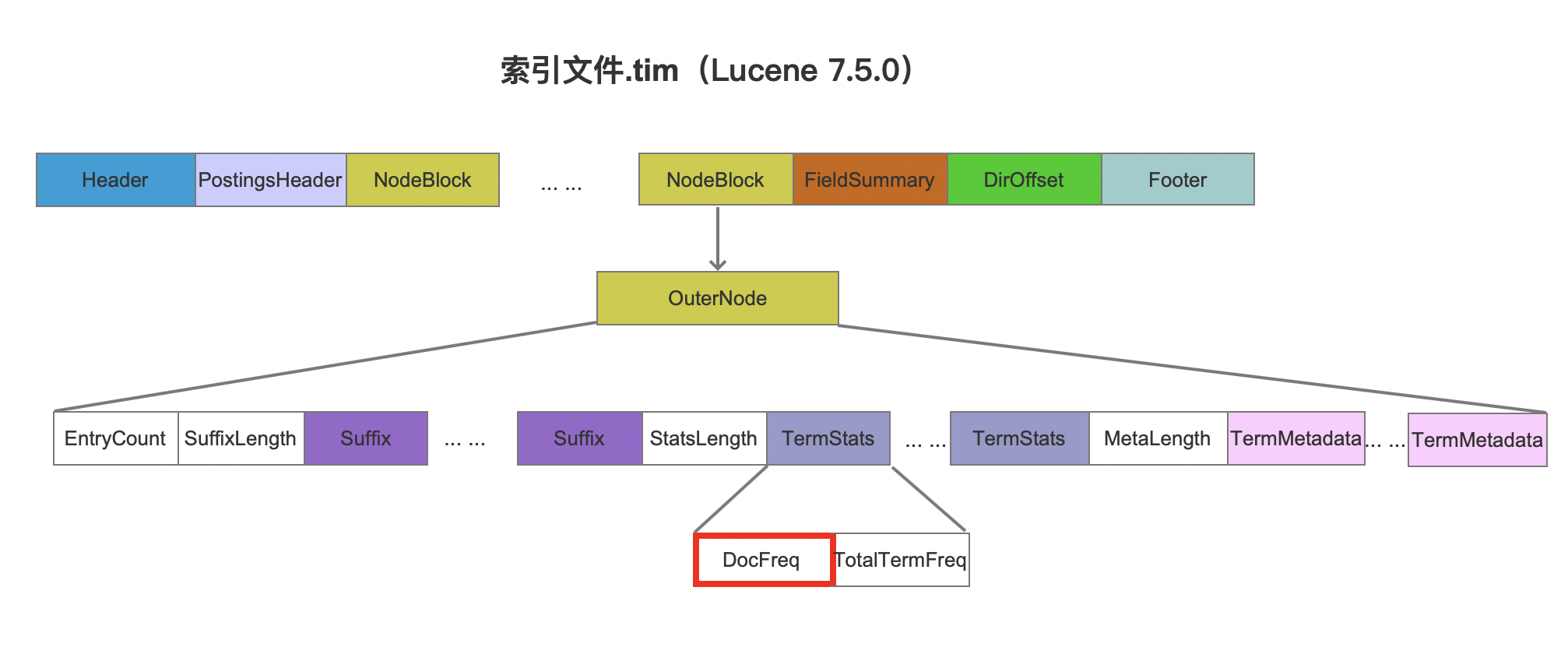
如果只使用了count接口,那么图1中的文档ID集合是无法获取的,因此需要额外的count字段来缓存命中数量。
生成CacheAndCount的方式见下文中BulkScorer(可选阅读)的介绍。
段缓存
QueryCache属于段级别的缓存,对于某一个Query,会在每一个段中生成一个缓存,在每一个段中,会使用LeafCache保存Query的缓存,其数据结构如下所示:
图3:
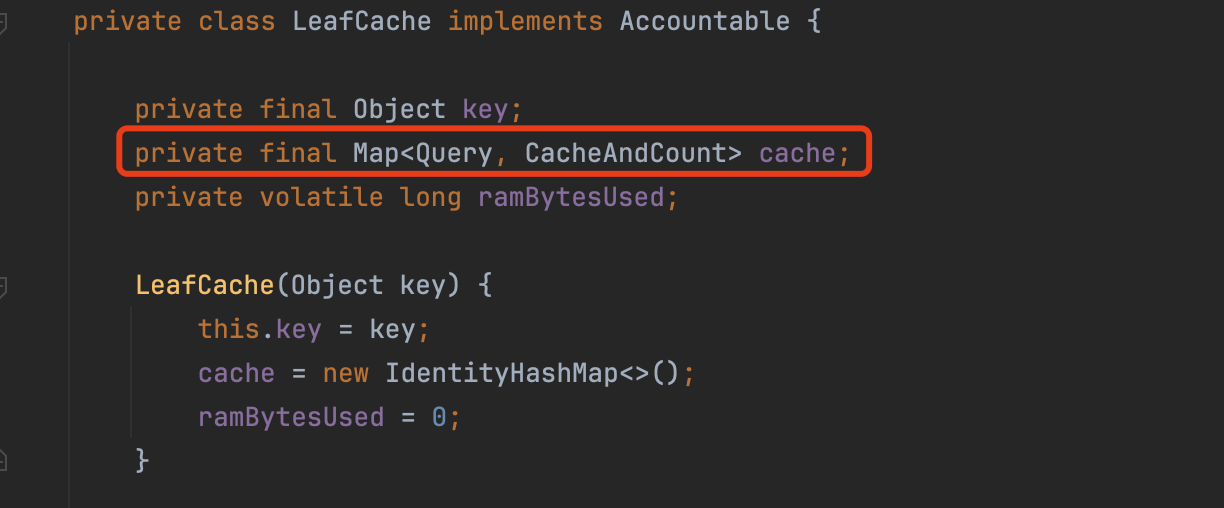
通过图3中cache这个Map的键值对可以很清晰的看出,cache描述了在某个段中,所有Query对应的缓存结果,其中CacheAndCount在上文中已经介绍。
全局缓存
当我们定义IndexSearcher时,会使用一个全局缓存来管理所有段的缓存:
图4-1:

这个Map中,IndexReader.CacheKey用来表示某一个段的标识,而LeafCache为这个段中的所有缓存。
因此在查询阶段,在访问某个段时,先根据这个段的唯一标示IndexReader.CacheKey,找到这个段中的缓存LeafCache,然后接着根据Query尝试查找在这个段中的缓存。
IndexReader.CacheKey
IndexReader.CacheKey作为段的唯一标示,每个段会New一个下面的对象来实现,使用对象作为Key:
图4-2:

IdentityHashMap
这里使用IdentityHashMap使得使用对象引用(地址)而不是对象内容(equal())来判断两个键是否相等。
何时使用缓存
不是每一次的查询都会使用缓存,详细内容见在文章LRUQueryCache中的介绍。
缓存限制
源码中定义了两个参数来平衡缓存的性能和资源使用:
- maxSize:缓存中允许存储的最大查询数量,设定为查询缓存的条目数上限,默认值为
1000。该参数限制了缓存中存储的查询条目的总数,以防止缓存过度膨胀,影响内存利用效率 - maxRamBytesUsed:缓存中所占用的最大内存字节数限制。该参数限制了缓存使用的最大内存量,确保缓存不会占用过多的 JVM 堆内存。其具体计算方法如下
1 | maxRamBytesUsed = Math.min(1L << 25, Runtime.getRuntime().maxMemory() / 20); |
也就是默认允许最多1000条不同Query的缓存以及最多32M的内存。
缓存统计数据
QueryCache中增加以下的统计值以及一些接口,有助于理解缓存的使用情况以及其对系统性能的影响,从而帮助用户进行缓存策略的优化和调优。
- hitCount:记录缓存命中的次数
- missCount:记录缓存未命中的次数
- cacheSize:记录当前缓存中存储的查询结果数量。了解缓存的利用率和是否需要增加或减少缓存的容量
- cacheCount:记录自缓存创建以来,曾经被缓存过的
CacheAndCount总数(无论是否已被移除)帮助理解缓存的使用历史和工作负载特性 - getEvictionCount():记录缓存中被移除(删除)的缓存数量。频繁的驱逐可能表明缓存空间不足或者缓存策略不适合当前的查询工作负载
- ramBytesUsed:所有段的缓存占用的内存量。该值可以通来判断是否达到缓存限制(即上文中的
maxRamBytesUsed)
缓存逻辑
我们先介绍下触发QueryCache的流程点:
图5:
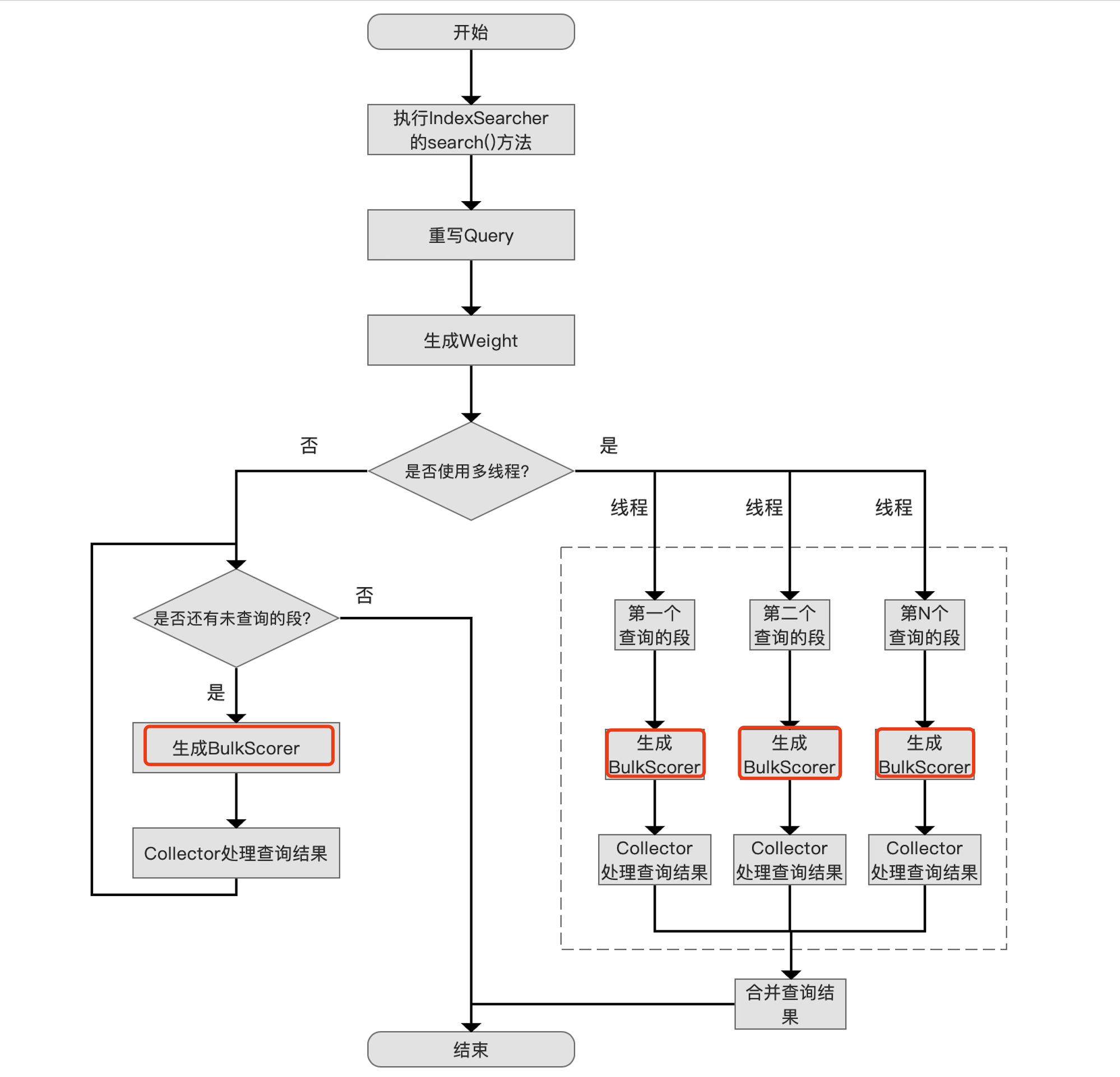
QueryCache在查询流程中并不是一个额外的流程点,它封装了其他的Weight对象,并提供自己的BulkScorer的实现。
BulkScorer(可选阅读)
在文章BulkScorer(一)跟BulkScorer(二)详细介绍了BulkScorer的内容。可以将BulkScorer最核心的一个功能简单的理解为:它至少包含了一个文档号集合,然后定义了文档号集合读取方式。
对于QueryCache,如果是第一次缓存某个Query,则会基于满足这个Query的文档号集合,使用DefaultBulkScorer实现BulkScorer的逻辑,DefaultBulkScorer的介绍见文章BulkScorer(一)。
上文中我们提到缓存的内容用CacheAndCount描述,那么CacheAndCount是如何获取的呢?
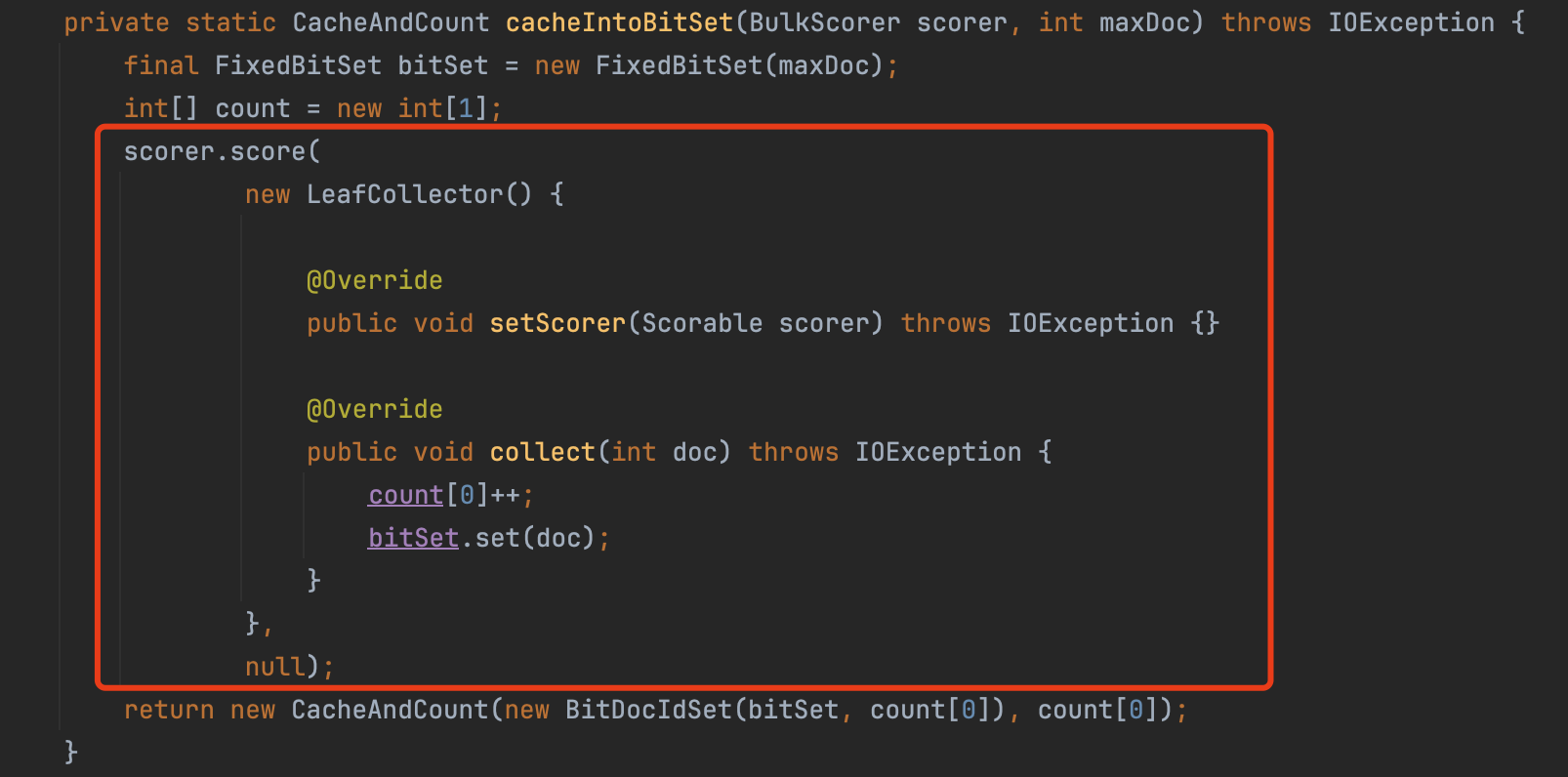
由于QueryCache封装了一个BulkScorer,因此只需要提供一个最简化的收集器Collector,使用这个Collector执行BulkScorer.score(LeafCollector collector, Bits acceptDocs)方法就可以获取到满足查询条件的文档号。
图6:
写入缓存
图7:
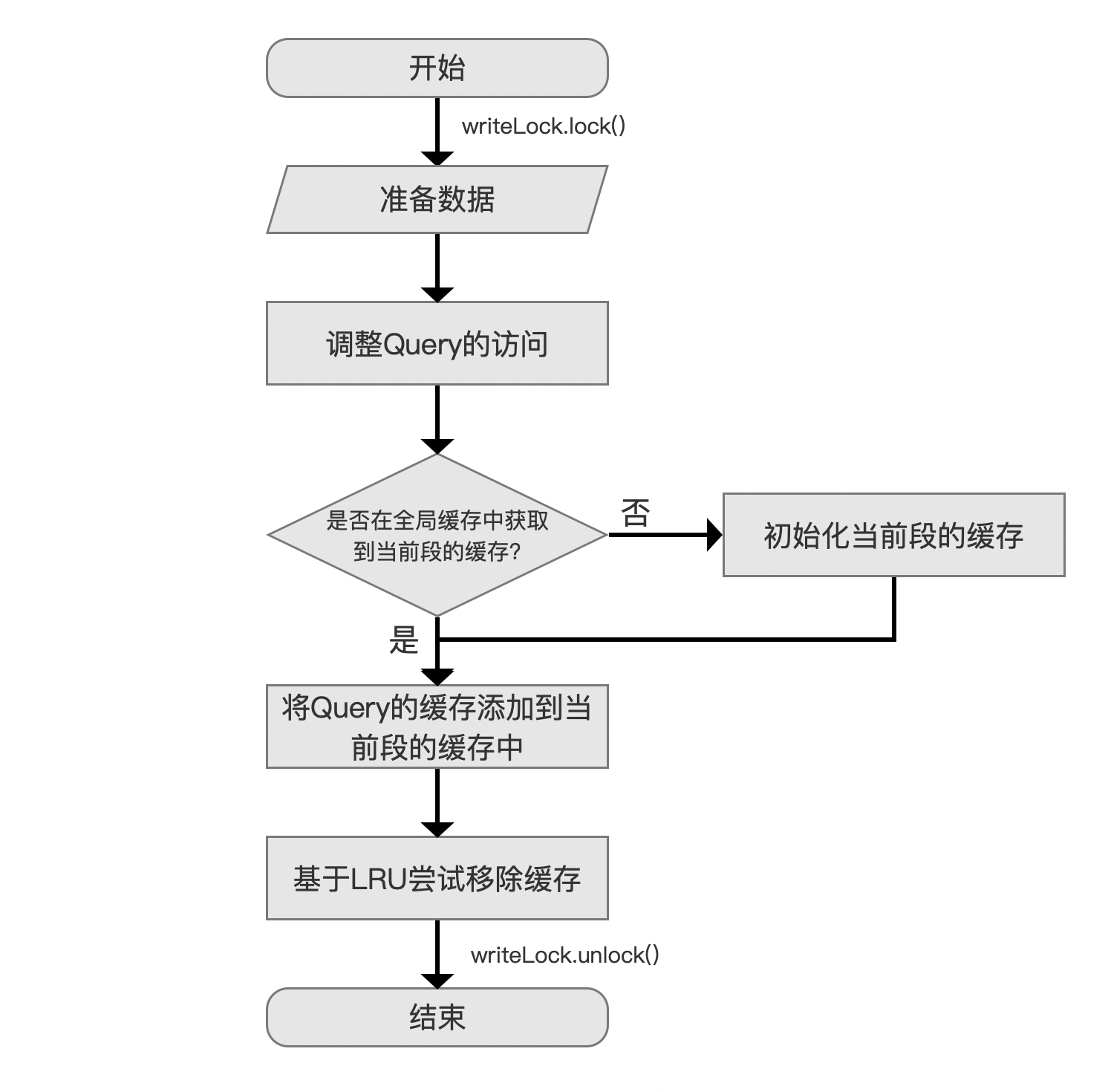
图6展示的是在写入缓存的流程图,采用的是经典的LRU(Least Recently Used)算法。
准备数据
图8:
写入缓存前需要准备三样东西:
- Query:待缓存的Query对象,在上文
LeafCache中提到,它可以作为一个Key,找到对应的缓存内容CacheAndCount - CacheAndCount:某个Query对应的缓存内容,即文档号以及文档号总数
- IndexReader.CacheHelper:这个概念在下文图10中会展开介绍其作用
调整Query的访问
图9:

源码中使用了下面的Map对象来描述LRU中Query的访问先后顺序:
1 | Map<Query, Query> uniqueQueries = Collections.synchronizedMap(new LinkedHashMap<>(16, 0.75f, true)) |
拆解分析下这个Map:
-
LinkedHashMap<>(16, 0.75f, true)是基于访问顺序的LinkedHashMap:在每次访问元素(不论是通过 get 方法读取,还是通过 put 方法插入)时,这个元素都会被移动到链表的末尾。这样,最早被访问的元素会排在最前面,最近被访问的元素会排在最后。 -
Collections.synchronizedMap()是用于生成线程安全的 Map 的包装器,默认情况下,HashMap及其子类(如 LinkedHas·hMap)不是线程安全的。在多线程环境中访问或修改 Map 时,如果没有同步措施,就可能导致数据不一致或异常。
将Query的缓存添加到当前段的缓存中
图10:
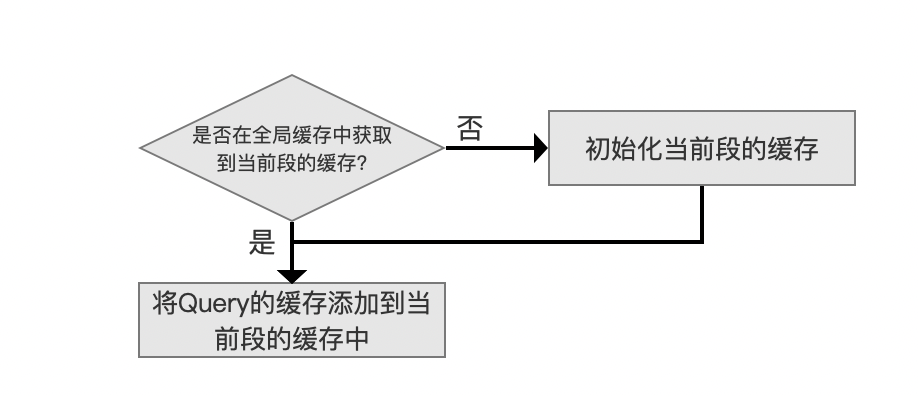
该流程尝试从图4-1的cache容器中找到当前段内的所有缓存LeafCache,如果当前段没有任何缓存,则初始化当前段的缓存,否则将Query的的缓存CacheAndCount直接添加到LeafCahce中,见图3。
如果需要初始化当前段的缓存,则随后还有一个很重要的步骤:为这个段添加一个回调方法,使得当这个段不在被使用(比如这个段不被任何IndexReader引用时)时清空段中的缓存,目的是释放内存。
清空段中的缓存
需要清除的内容包括:
- 从上文中提到的
ramBytesUsed中移除这个段中的所有缓存占用的内存。 - 从上文中提到的
cacheSize中移除这个段中缓存的数量
基于LRU尝试移除一些缓存
图11:

步骤一:是否需要移除现有的缓存
首先判断是否需要移除现有的一些缓存,判断条件如下:
1 | size > maxSize || ramBytesUsed > maxRamBytesUsed |
size指的是图9中uniqueQueries中Key的数量,也就是缓存的Query数量,判断是否达到上文中提到的maxSizeramBytesUsed跟maxRamBytesUsed在上文中已经介绍,判断目前缓存占用的内存是否达到阈值。
步骤二:移除缓存
如果需要移除现有的缓存,则从uniqueQueries的第一个元素开始依次移除,每移除一个Query对应的缓存就执行下步骤一,判断是否要继续移除,直到不满足步骤一中的判断条件。
注意是,需要从所有段中移除某一个Query对应的缓存。
缓存过期
Lucene中不存在缓存过期的问题,因为每个段在生成后其内容是不会变的,如果后续的删除/更新操作作用到这个段,那么只有重新打开新的IndexReader以及新的IndexSearch才能感知这些变更,使得会生成新的QueryCache对象。
缓存的负面影响
当Query第一次缓存时,也就是满足上文中何时使用缓存条件后,可能会导致这一次的Query响应较慢。
例如索引数据在写入时按照某个字段排序,并且查询阶段使用了相同字段的排序规则。在不使用缓存获取TopN时,当收集器收集到N个文档号就可以基于early termination提前结束查询。
由于early termination收集器Collector中实现,并且QueryCache替换成了图6中的简易Collector,使得这个Collector需要收集完整的满足这个Query的文档号集合。
但是后续的Query响应速度会快于缓存前以及第一次缓存时的Query,因为同时利用了缓存以及early termination机制。
上述场景可以看这个Demo。执行15次循环查询同一个Query花费的时间如下所示:
图12:
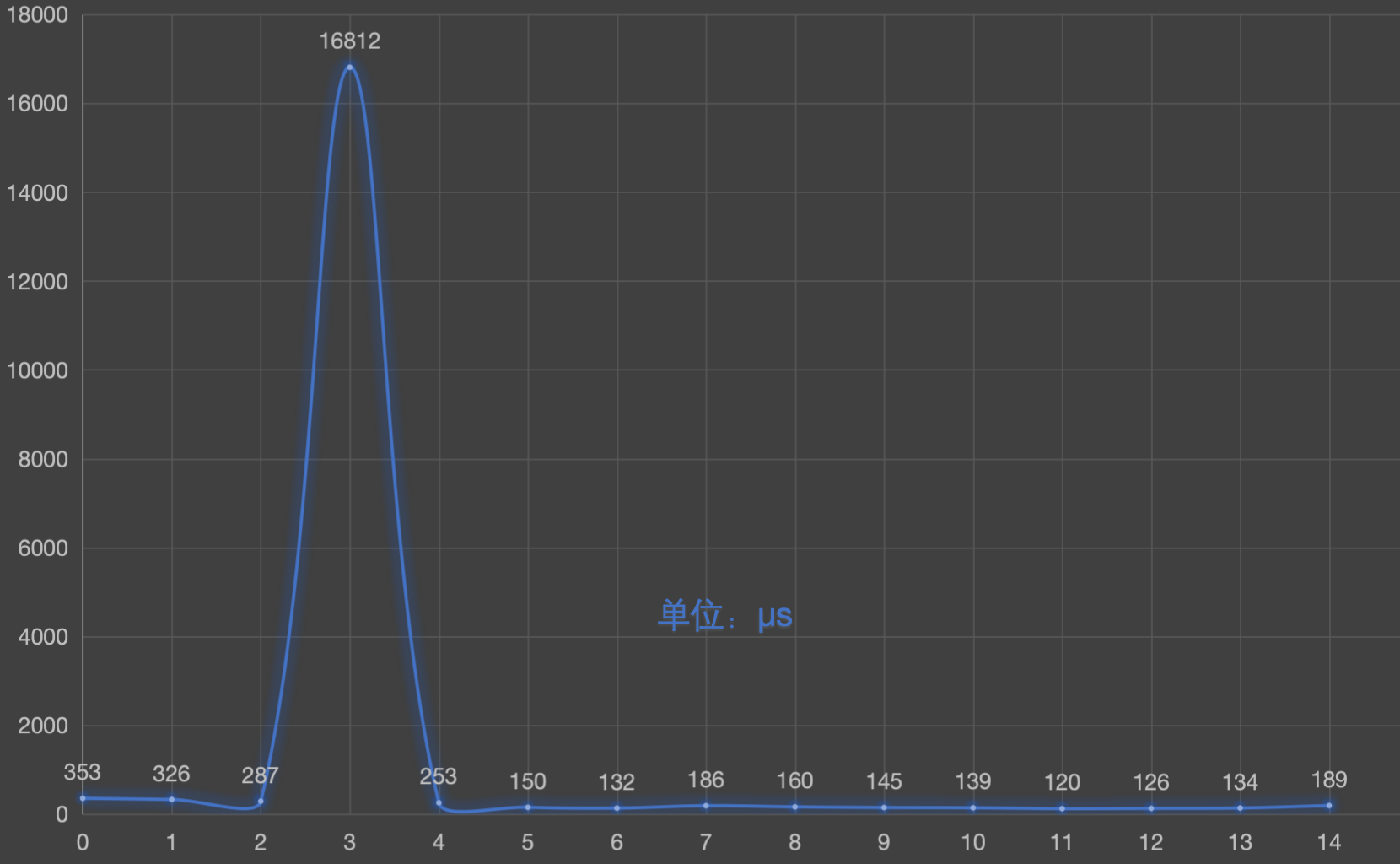
图12中前三次查询未满足缓存的条件,未触发缓存,但是使用了early termination机制
第4次查询将写入缓存,并且处理了满足查询的所有文档号
第5次及以后的查询使用了缓存以及early termination。