

Lucene中基于论文:Optimizing Top-k Document Retrieval Strategies for Block-Max Indexes 实现了Block-Max-Maxscore (BMM) 算法,用来优化关键字之间只有OR关系,并且minShouldMatch <= 1时的查询。比如有查询条件为:term1 OR term2 OR term3,那么文档中至少包含其中一个term就认为是满足查询条件。
算法概述
该算法通过对每个term的倒排表排序,排序规则为最大分数/倒排表长度,将高分倒排表作为必要倒排表,低分倒排表作为非必要倒排表。先遍历必要倒排表的文档ID,计算部分评分,如果部分评分加上非必要倒排表的最大分数之和仍低于阈值,则跳过该文档。否则,进行完整评分,包括非必要倒排表的评分。这样,算法减少了不必要的计算操作,因为它避免了对所有文档进行评分,只关注最有可能进入top-k结果的文档。
Lucene中BMM算法的处理逻辑基本跟论文中是一致的,结合上文的算法概述,我们通过以下三个步骤介绍该算法在Lucene中的实现:
- 计算最大分数(Maxscore)
- 选择必要倒排表(essential posting)跟非必要倒排表(non-essential posting)
- 遍历必要倒排表中的文档,选择合适的文档号
算法实现
计算最大分数(Maxscore)
算法名Block-Max-Maxscore中的block-max指的就是将倒排表划分为多个连续区间,每个区间即一个block,最大分数就是在每个block中最大的文档打分值。
由于在查询期间计算这个区间内所有的文档打分值然后选出最大值是昂贵的,因此Lucene提供了Impact机制,使得在索引期间先挑选出部分候选者,能保证最高的文档打分值只会出现于这些候选者中。在查询期间计算这些候选者,找出最大分数。
关于Impact的完整介绍可以阅读文章:索引文件的读取(十二)、ImpactsDISI。本文中我们简述下Impact机制。
Impact
图1:
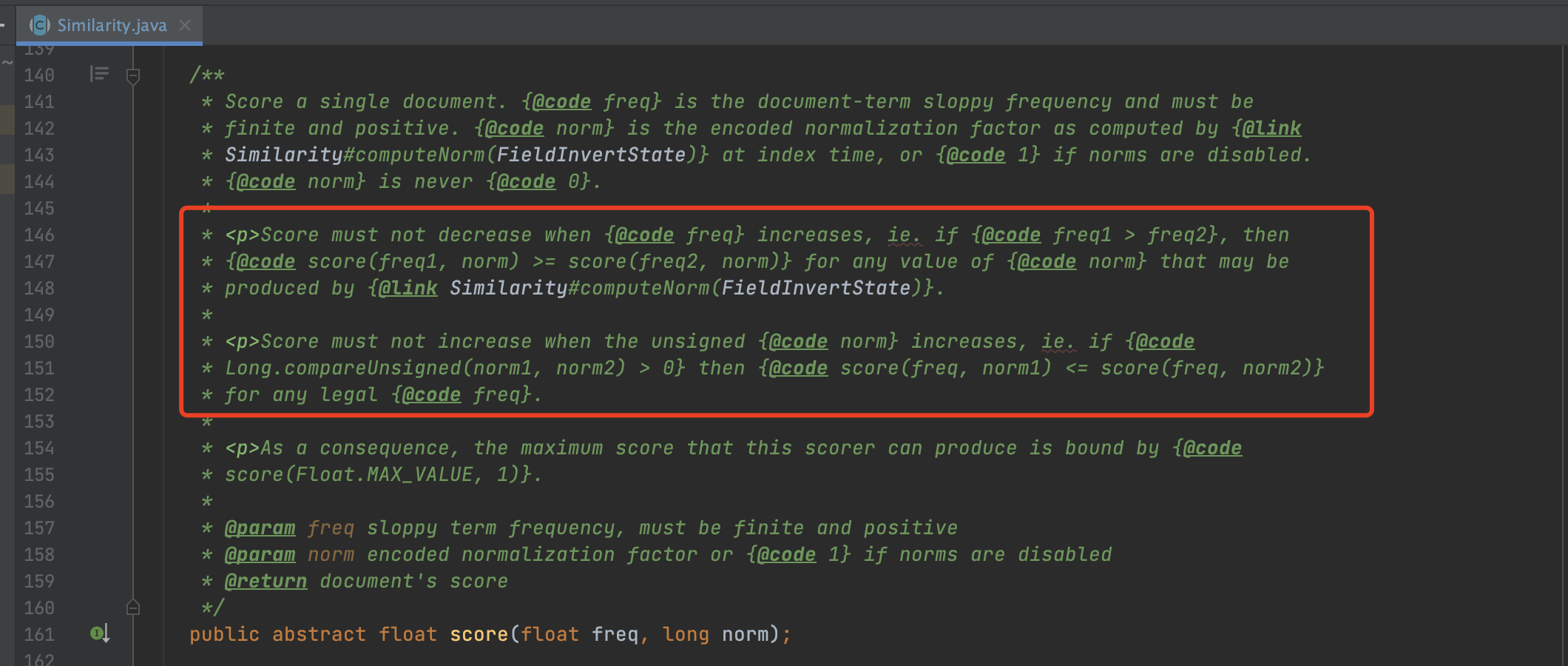
从Lucene打分公式的注释可以看出:
- 如果norm相等,那么freq较大对应的文档打分值会相等或者更高
- 如果freq相等,那么norm较小对应的文档打分值会相等或者更高
因此在索引期间,我们不需要真正的调用打分公式,而是简单的比较term在每一篇文档中的freq和norm,就可以筛选出候选者。也就是freq相等时,norm最小,或者norm相等时,freq最大的文档作为候选者,将他们的freq跟norm信息写入到索引文件中:
图2:
随后在查询阶段,我们就可以根据索引文件中所有的freq和norm,调用图1的打分公式,计算出最终的最大分数。
选择必要倒排表(essential posting)跟非必要倒排表(non-essential posting)
我们先直接介绍在Lucene中选择的实现方式,最后给出必要倒排表跟非必要倒排表的定义。
每一个term都有一个倒排表,在查询时,依次处理所有term的倒排表同一个区间的block(比如处理文档号0~2048这个区间的文档号),每次根据下面的规则对block排序,按照rule值从小到大排序:
1 | rule = maxScore / cost |
maxScore即block中最大分数,cost为倒排表的长度。
选择必要倒排表跟非必要倒排表的代码如图3所示
图3:
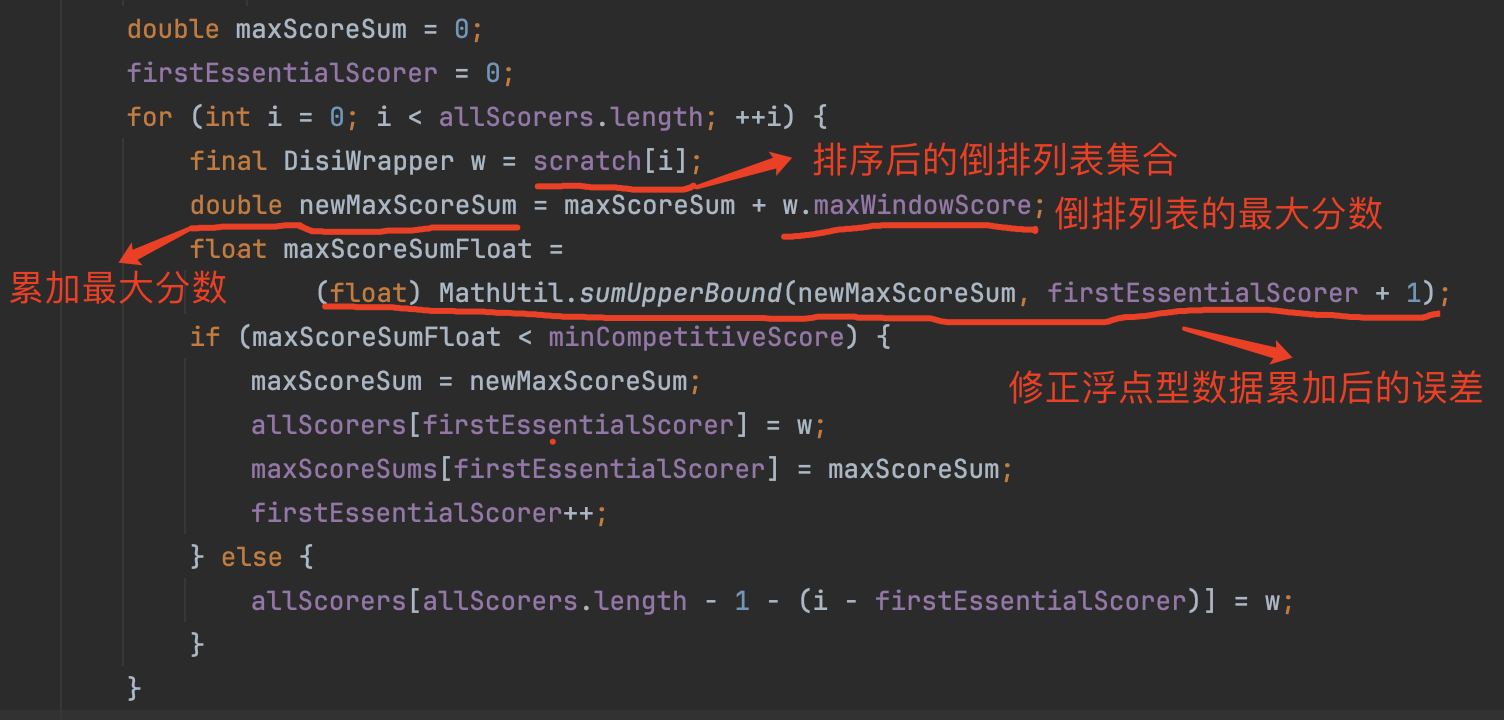
在图3中,从最小rule值的倒排表开始,依次累加倒排表的最大分数Maxscore(即图3中的maxWindowScore),如果maxScoreSumFloat未达到阈值minCompetitiveScore,则将倒排表添加到allScorer数组的头部,否则剩余的倒排表添加到allScorer的尾部。最后在allScorer 数组中,小于索引值firstEssentialScorer的倒排表都是非必要倒排表(non-essential posting),数组中其他的倒排表都是必要倒排表(essential posting)。
最后将必要倒排表中所有的倒排表塞入到优先级队列essentialQueue中,排序规则为比较每个倒排表中第一个文档号,堆顶元素为最小的文档号:
图4:

因此,这两类倒排表的定义如下:
- 非必要倒排表:在对倒排表集合排序后,最大分数(maxscore)的总和小于当前阈值的倒排表集合
- 必要倒排表:在对倒排表集合排序后,最大分数(maxscore)的总和大于等于当前阈值的倒排表集合
再次回顾下图3,如果所有的倒排表都是非必要倒排表,那么这个block中所有文档都可以Skip,而这正是该算法的核心之一。
为什么要区分必要倒排表(essential posting)跟非必要倒排表(non-essential posting)
- 必要倒排表中的文档号将用来遍历
- 非必要倒排表中最大分数的总和小于当前阈值,那么如果只使用这些倒排表中的文档,是无法进入Top-K,如果想要进入Top-K,必须包含必要倒排表
- 必要倒排表的最大分数比较高,那么能更早的找到高评分的文档
- 非必要倒排表用来完整文档打分值
- 在遍历必要倒排表中的文档时,如果非必要倒排表有相同的文档,需要贡献打分值
遍历必要倒排表中的文档,选择合适的文档号
该步骤的过程可以简述为:依次遍历必要倒排表的文档号,计算文档打分值,如果在非必要倒排表中存在相同的文档号,则累加文档打分值。
详细的处理过程可以分为两个步骤:
-
确定参与打分的文档号
- 确定哪些文档号可能可以进入Top-k,实现文档号的Skip
-
累加文档打分值。
另外在确定参与打分的文档号这个步骤中,基于必要倒排表中倒排表数量有各自的实现方式来优化性能。
确定参与打分的文档号
必要倒排表中有多个倒排表
依次遍历必要倒排表中的多个倒排表,将它们的文档号写入到位图中,完成参与打分的文档号这一步骤。
- 对应代码中的MaxScoreBulkScorer#scoreInnerWindowMultipleEssentialClauses(…)方法
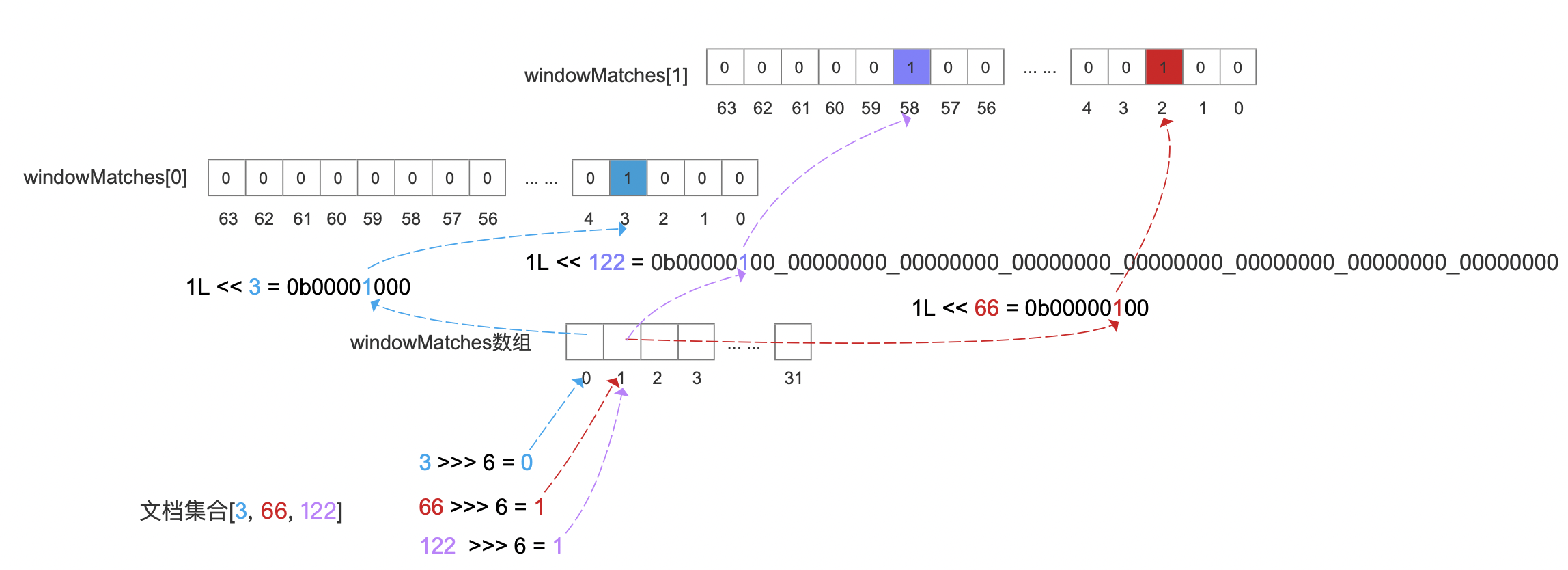
在源码中,使用一个名为windowMatches的long类型数组描述文档号,long占用64个bit,每一个bit用来表示一个文档号。
下面的例子中展示了将文档集合为[3, 66, 122]写入到位图中,计算公式为:
1 | int index = docId >>> 6 |
图5:
优化
上文中我们说到,使用了优先级队列essentialQueue对必要倒排表中的倒排表排序。在这一步骤中如果堆中前2个倒排表满足下面的关系,则会进行优化,而不是使用位图:
-
top2.doc - INNER_WINDOW_SIZE / 2 >= top.doc
top.doc描述的是,第一个倒排表中最小的文档号
top2.doc描述的是,第二个倒排表中最小的文档号
INNER_WINDOW_SIZE 可以简单的理解block中最多的文档数量,默认是2048
当满足这个关系后,则这次只按照第一个倒排表中的文档号遍历,遍历范围为[top.doc, top2.doc]
- 对应的代码为MaxScoreBulkScorer#scoreInnerWindowSingleEssentialClause(…)
必要倒排表中只有一个倒排表
如果只有一个倒排表,那么直接将这个倒排表中的文档号作为参与打分的文档号即可。
- 对应的代码为MaxScoreBulkScorer#scoreInnerWindowSingleEssentialClause(…)
优化
但是在某些场景下还可以进一步优化,源码中也给出了解释:
图6:
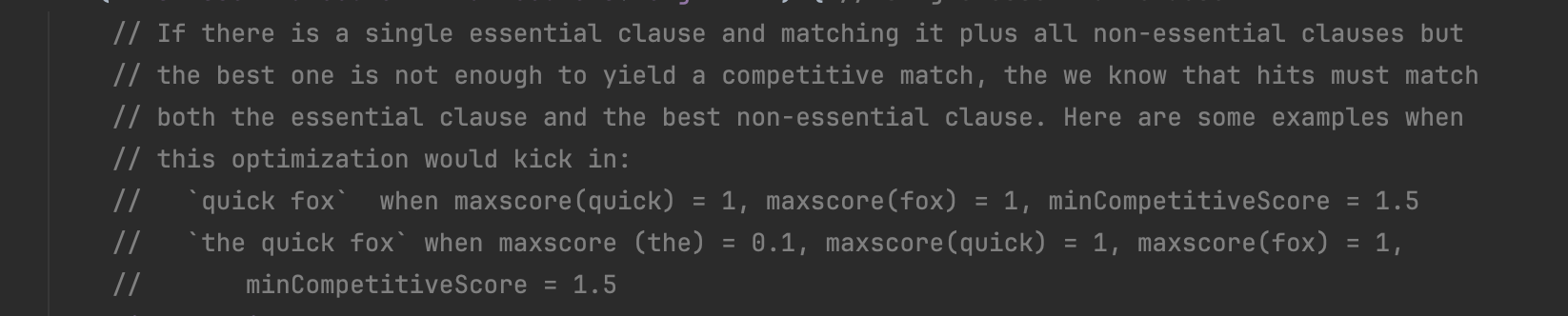
这个注释描述的是,non-essential中除去最佳的那个倒排表,其他倒排表的最大分数累加值跟essential中的那个唯一的倒排表的最大分数相加后,如果和值小于minCompetitiveScore,说明同时出现在essential的倒排表和non-essential最佳的倒排表中的文档号才有可能进入Top-K。如下所示:
图7:
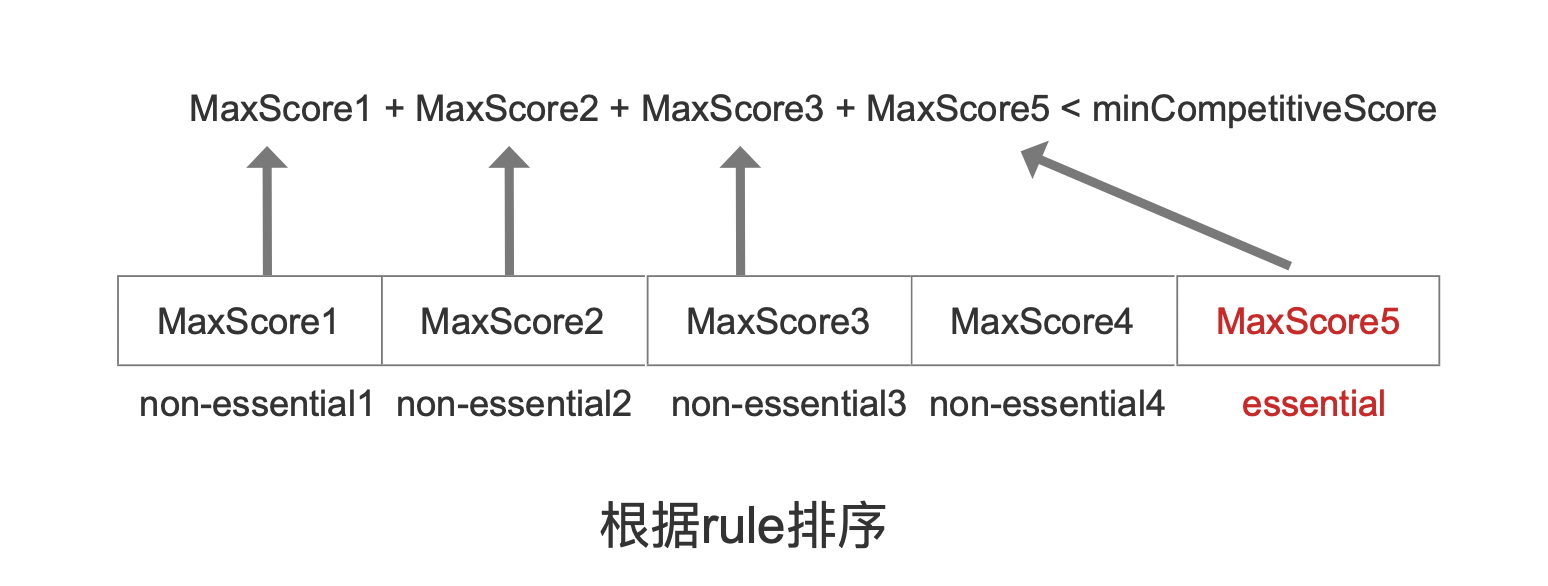
图7中,所有的non-essential按照上文中提到的rule排序,其中 non-essential4就是 non-essential中最佳的那个倒排表。
也就是说完成确定参与打分的文档号后,其文档号集合为essential和non-essential4的文档号交集(交集意味着后续需要处理更少的文档数量)
在图7的基础上,还可以进一步判断是否要计算non-essential3的交集:
图8:
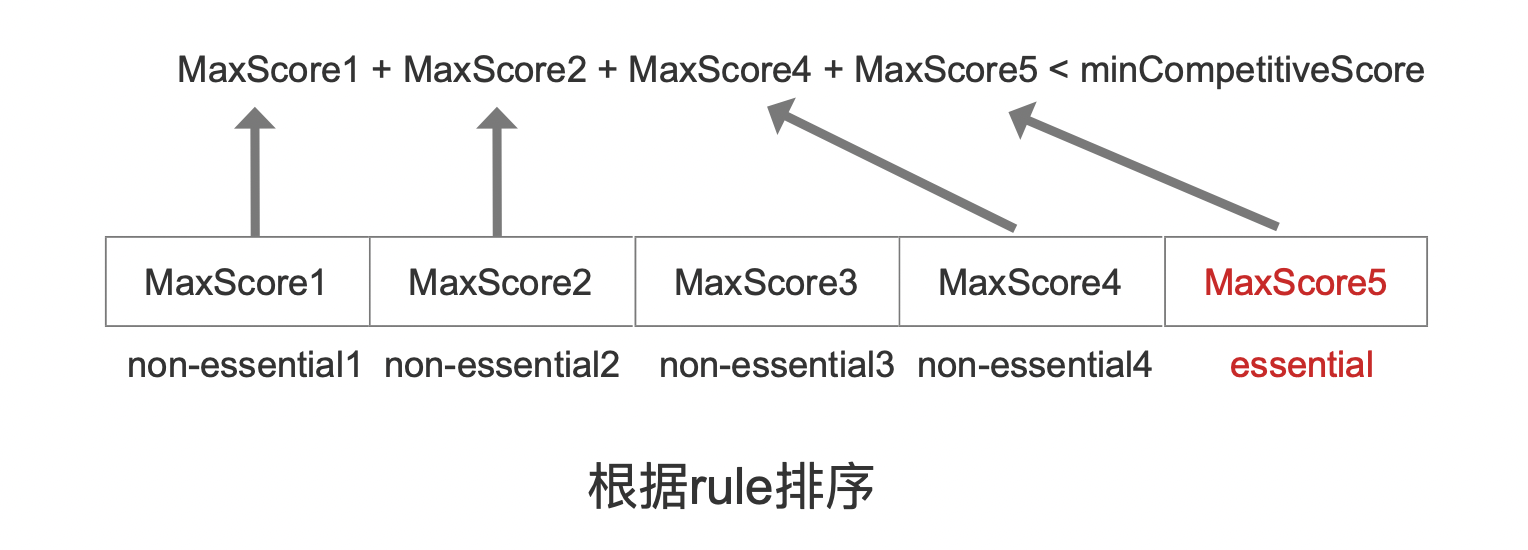
如果满足图8中的条件,那么完成确定参与打分的文档号后,其文档号集合为essential和non-essential4、non-essential3的文档号交集。以此类推,可以获得更少的待遍历的文档数量
当确定好non-essential中需要参与交集的倒排表后,跟essential的交集操作相对简单,可以自行参考源码。
- 对应的代码为MaxScoreBulkScorer#scoreInnerWindowAsConjunction(…)方法
累加文档打分值
上文中,我们只是通过最大分数MaxScore确定哪些文档号是可能可以进Top-k,具体到某一篇文档的实际打分值则是在当前步骤累加文档打分值完成。
该步骤的逻辑就非常简单了,可以简述为:
- 根据从上一步骤获取到的文档号,计算该文档号在必要倒排表中对应的文档分数,如果非必要倒排表中存在相同的文档号,则累加文档的打分值,得出文档的实际打分值。如果实际打分值达不到minCompetitiveScore,那么这个文档号不会被Collecter收集。