

在文章BulkScorer(一)中,我们介绍了抽象类DocIdSetIterator类,而ImpactsDISI是DocIdSetIterator的其中一种实现,当排序规则为文档打分值时,使得在查询TopN遍历文档时,可以跳过那些不具备竞争力的文档。
图1:
前置知识
在展开介绍ImpactsDISI原理之前,我们需要先了解一些Lucene中的其他知识点,包括Impact、打分公式、跳表。
Impact
文章索引文件的读取(十二)中详细的介绍了其概念,本文中我们只简单介绍提下Impact中几个重要的内容。
Impact是Lucene中的一个类,在生成索引阶段,某个term在一篇文档中的词频freq和标准化值(normalization values)norm会使用Impact对象记录,并且写入到索引文件.doc中。
图2:
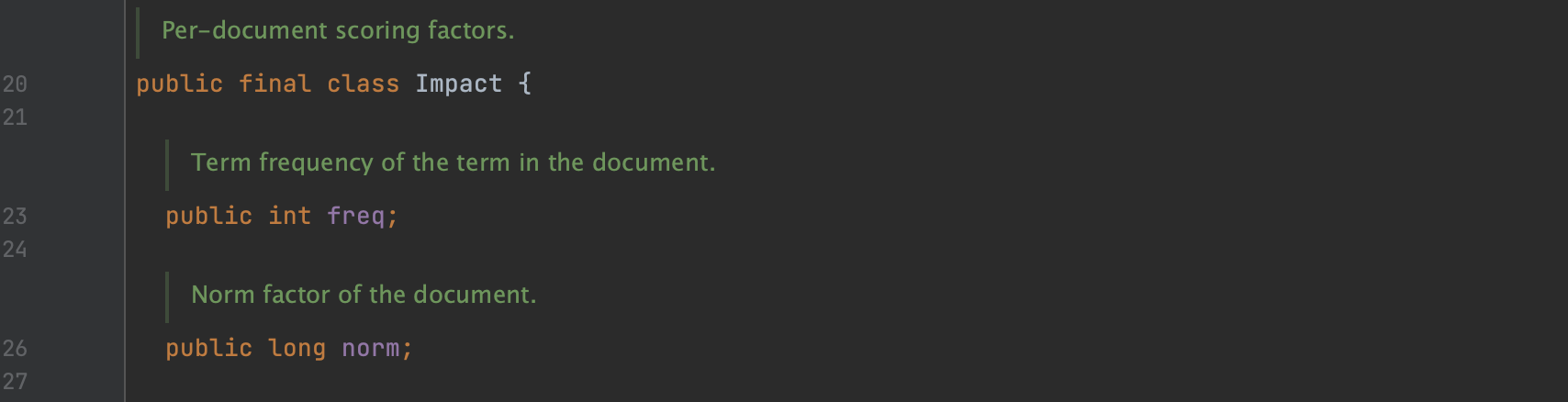
图3:
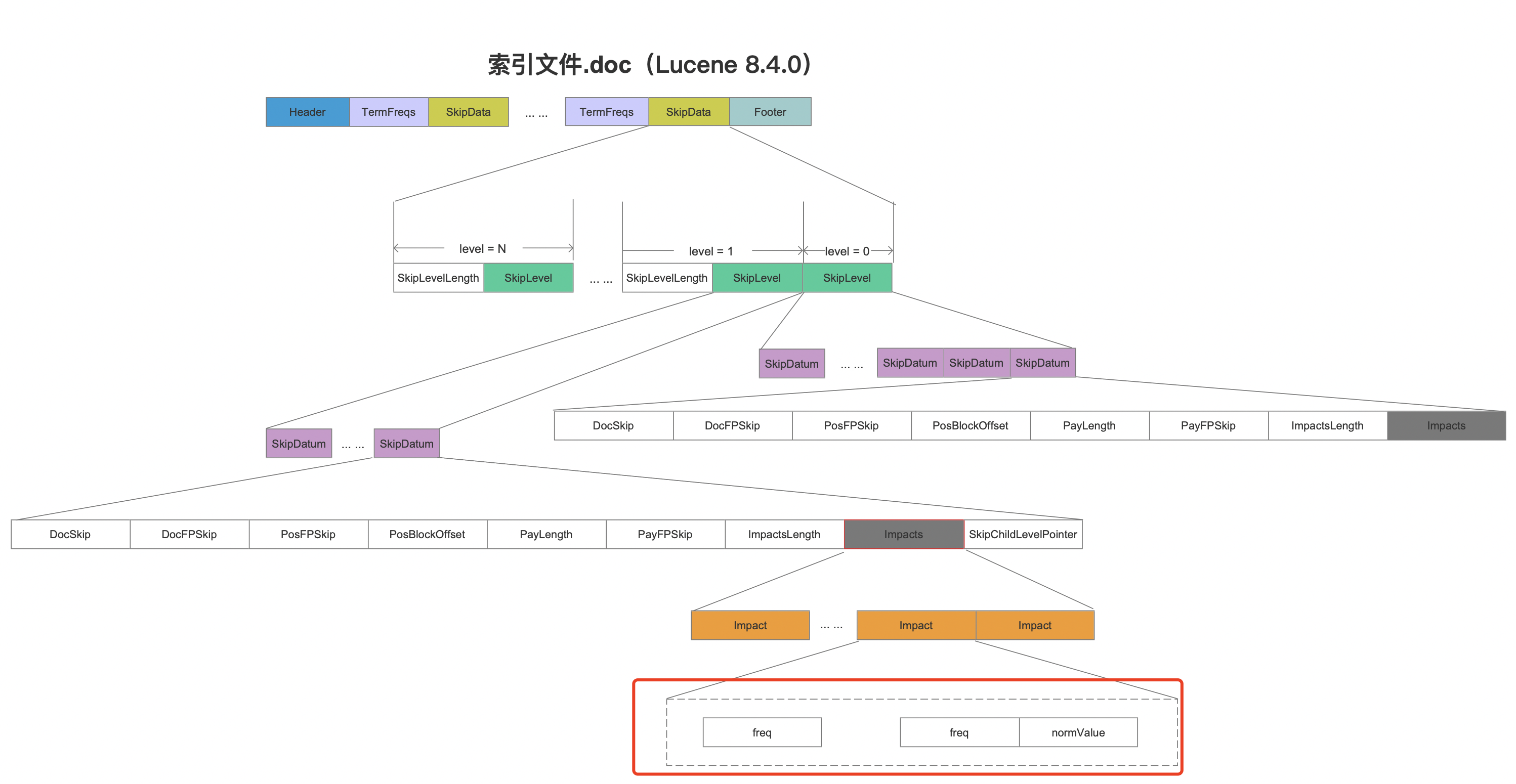
图3红框标注的内容即某个term在一篇文档中的freq和norm。注意的是,由于使用差值存储freq和norm,如果当前norm跟上一个norm的差值为0,则只存储freq。
打分公式
当前版本Lucene9.6.0的打分公式如下所示:
图4:
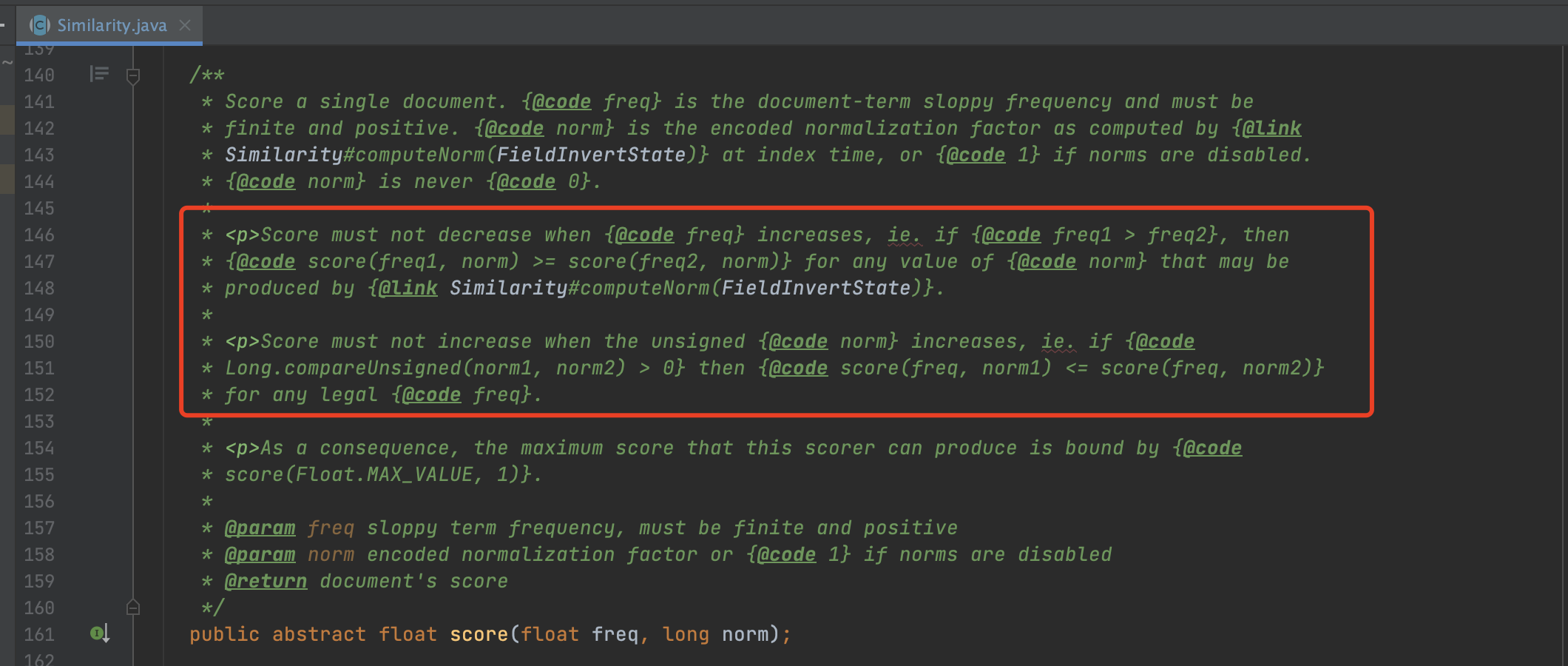
当需要计算包含某个term的文档的打分值时就会调用图3中的score方法。红框中的注释大意是:
- 如果norm相等,那么freq较大对应的文档打分值会相等或者更高
- 如果freq相等,那么norm较小对应的文档打分值会相等或者更高
这意味我们不需要真正的去调用图3中的打分方法获取文档的精确的打分值,而是可以仅通过freq和norm这两个值就可以粗略判断文档之间的打分值高低。
跳表
文章索引文件的生成(三)之跳表SkipList、索引文件的生成(四)之跳表SkipList详细介绍了Lucene中跳表的构建过程以及读取过程,本文中不再赘述。Lucene中通过分块(block)、分层(level)的方式对文档号构建跳表。
图5:
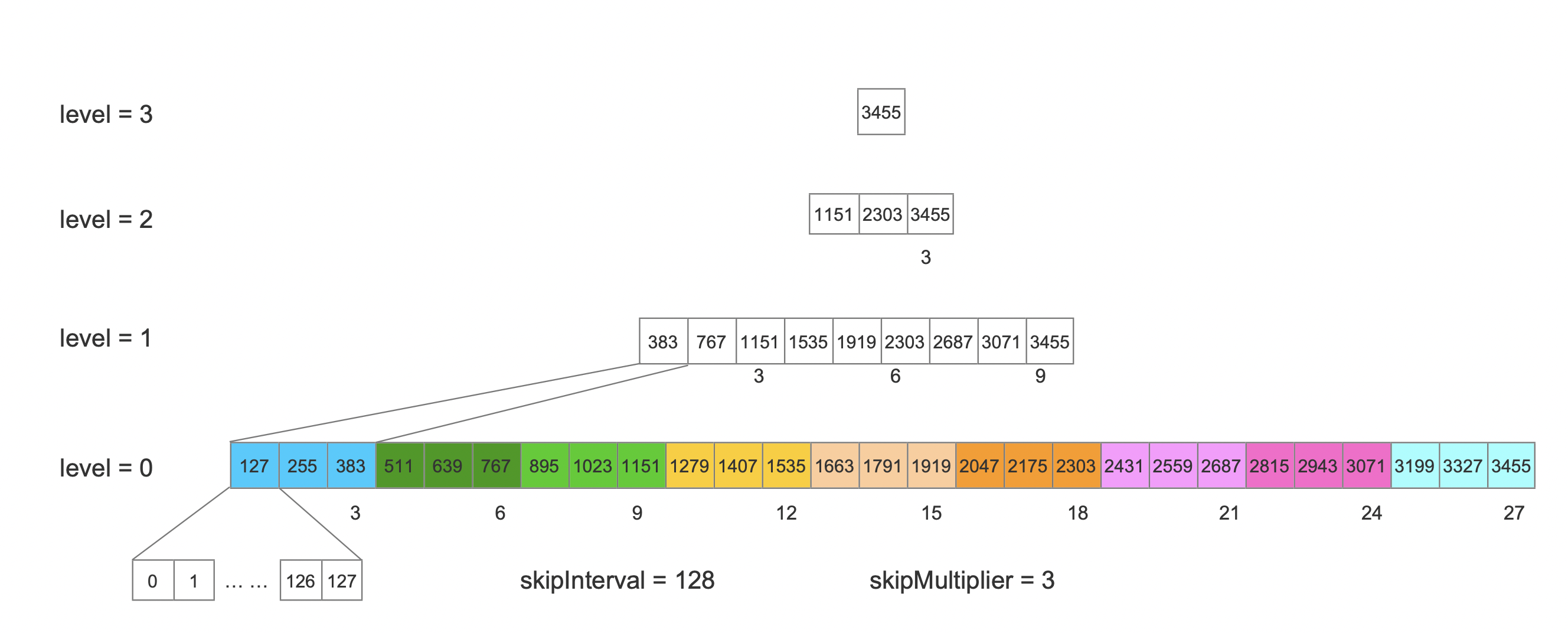
图5是只基于Lucene中跳表的的实现思想,并不是真正的实现方式。该图描述的是对文档号集合[0, 3455]一共3456个文档号进行跳表的构建。Lucene默认每处理128(即图5中的skipInterval,源码中的变量)个文档号就构建一个block(分块),该block在源码中对应为图3中level=0层中第一个SkipDatum,并且每生成3(即图5中的skipMultiplier,源码中的变量,默认值为8)个SKipDatum就在上一层,即level=1层构建一个新的SkipDatum(分层)。
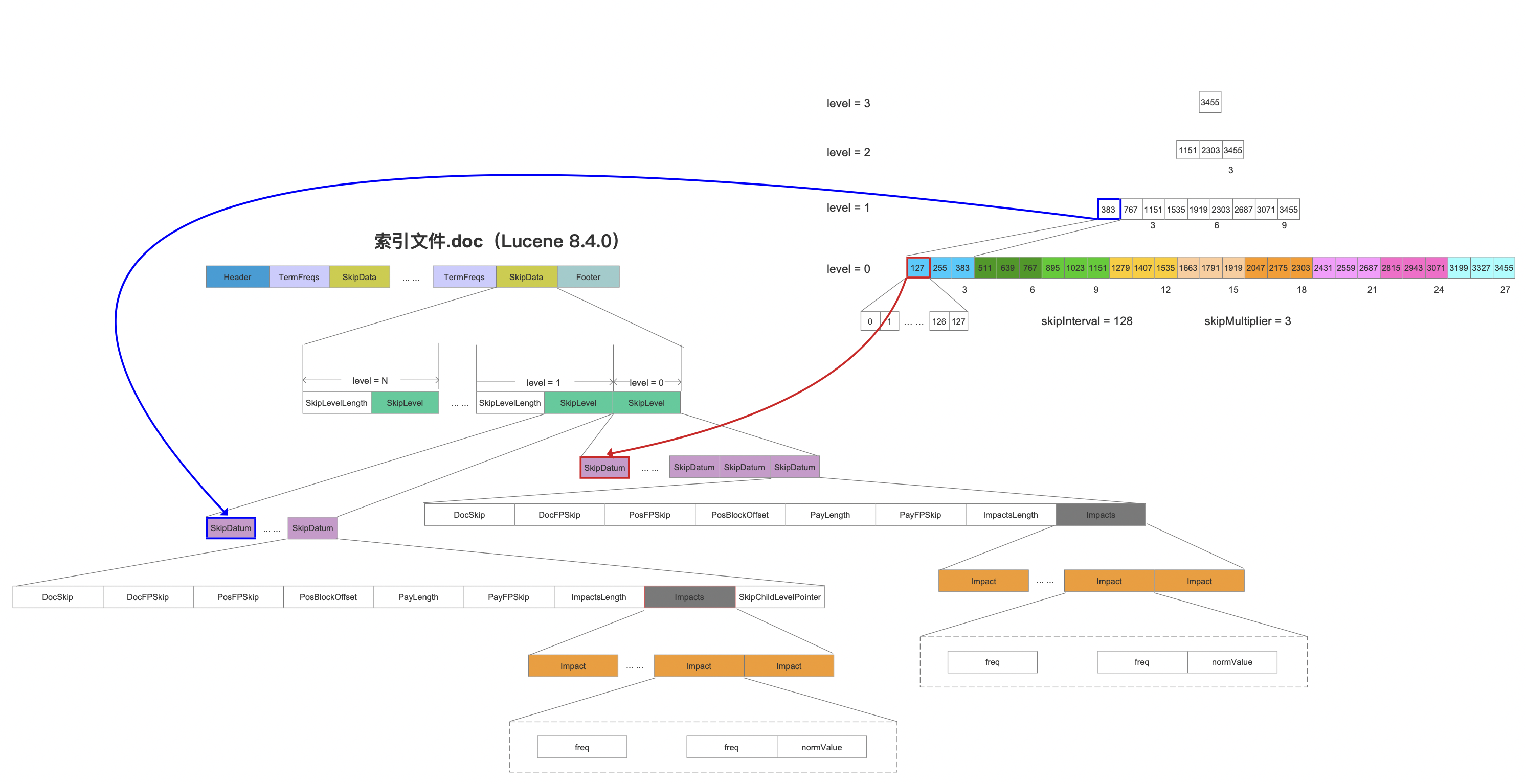
图5中每一个SkipDatum跟图3的索引文件的对应关系如下所示:
图6:
ImpactsDISI的文档遍历
ImpactsDISI作为DocIdSetIterator的子类,其核心为如何实现图7中的抽象方法advance(int target)方法,该方法描述都是从满足查询条件的文档号集合中找到下一个大于等于target的文档号。
如果target的值为3,并且有下面两个文档号集合:
1 | 集合一:[0,2,3,4,5] |
对于集合一,advance方法的返回值为3;对于集合二,advance方法的返回值为4.
图7:

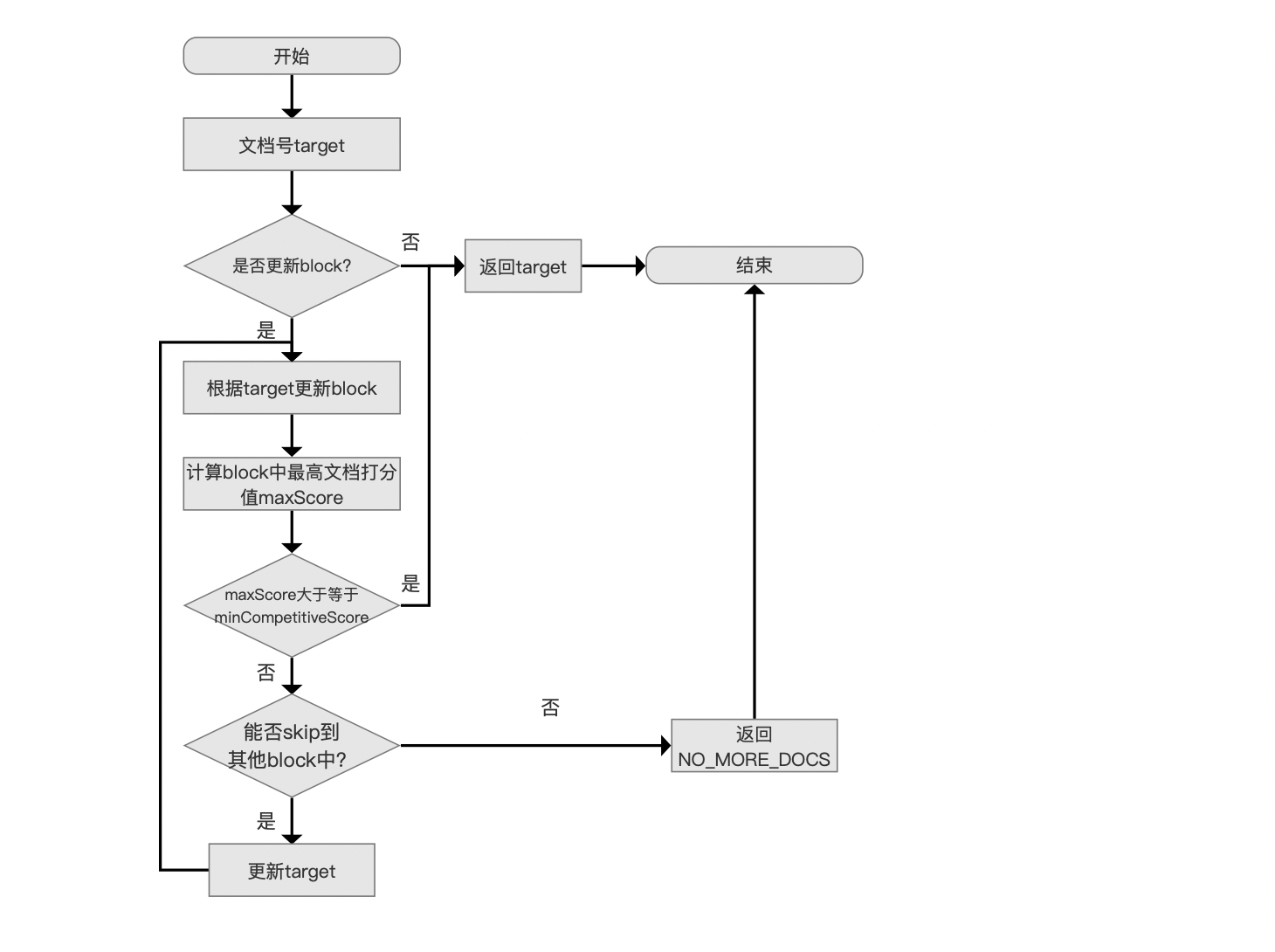
该方法在ImpactsDISI中的实现流程图如下:
图8:
名词解释
先介绍下流程图中的一些名词:
- block:在图6的level=0层,每处理128个文档号就构建一个block。在level=0层对应SkipDatum
- maxScore:某个block的所有文档打分的最大值
- minCompetitiveScorer:在执行TopN的查询时,当已经收集了N篇文档,通过规则为文档打分值的优先级队列进行排序后,堆中最小的文档打分值即minCompetitiveScorer。如果是升序,意味着后续收集到的文档的打分值必须大于该值才被认为是具有竞争力的
- NO_MORE_DOCS:Lucene中定义的边界值,常在遍历文档时使用,表示遍历结束
不需要进行skip
图9:
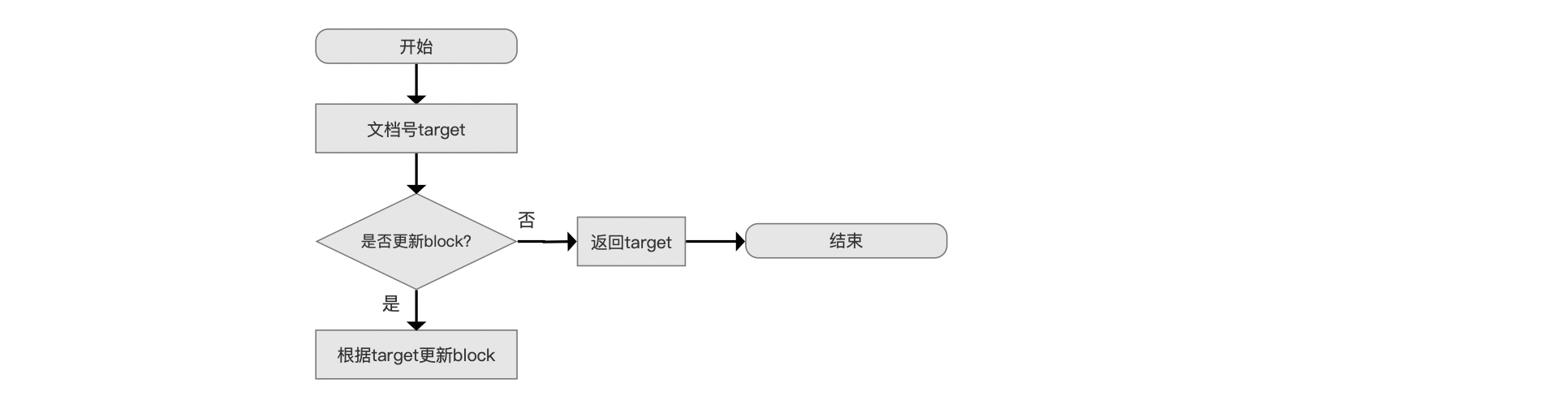
我们先介绍下根据target更新block。它描述的是下一个进行遍历的block。在文章索引文件的生成(四)中介绍的哨兵数组skipDoc记录了每一层当前遍历的block,使得可以快速定位target属于某个block。
在level=0层,每128篇文档号就生成一个block,即图6中的SkipDatum。注意的是每个SkipDatum中impacts的Impact数量是小于等于128个,意味着如果这个block的maxScore大于minCompetitiveScorer,说明至少包含一篇文档是具有竞争力的,那么这个block中的所有文档我们都需要处理才能明确知道哪些文档是具有竞争力的,所以这种情况下就不能进行skip。
为什么每个SkipDatum的impacts的Impact数量是小于等于128个?
首先一个block中的文档数量为128个,另外在索引阶段我们不需要记录某个term在这128篇文档中的Impact信息,即freq和norm。因为我们记录Impact的目的是为了在查询阶段能计算出block的maxScore值,根据上文中介绍的打分公式,如果某个term在两篇文档中的norm相同,那么只需要记录freq较大的Impact(详细的例子见索引文件的读取(十二))。
如果当前target跟上一个target不在同一个block中,那么就需要更新block。否则就直接返回当前target,因为它对应的文档打分值有可能是具有竞争力的。
进行skip
图10:
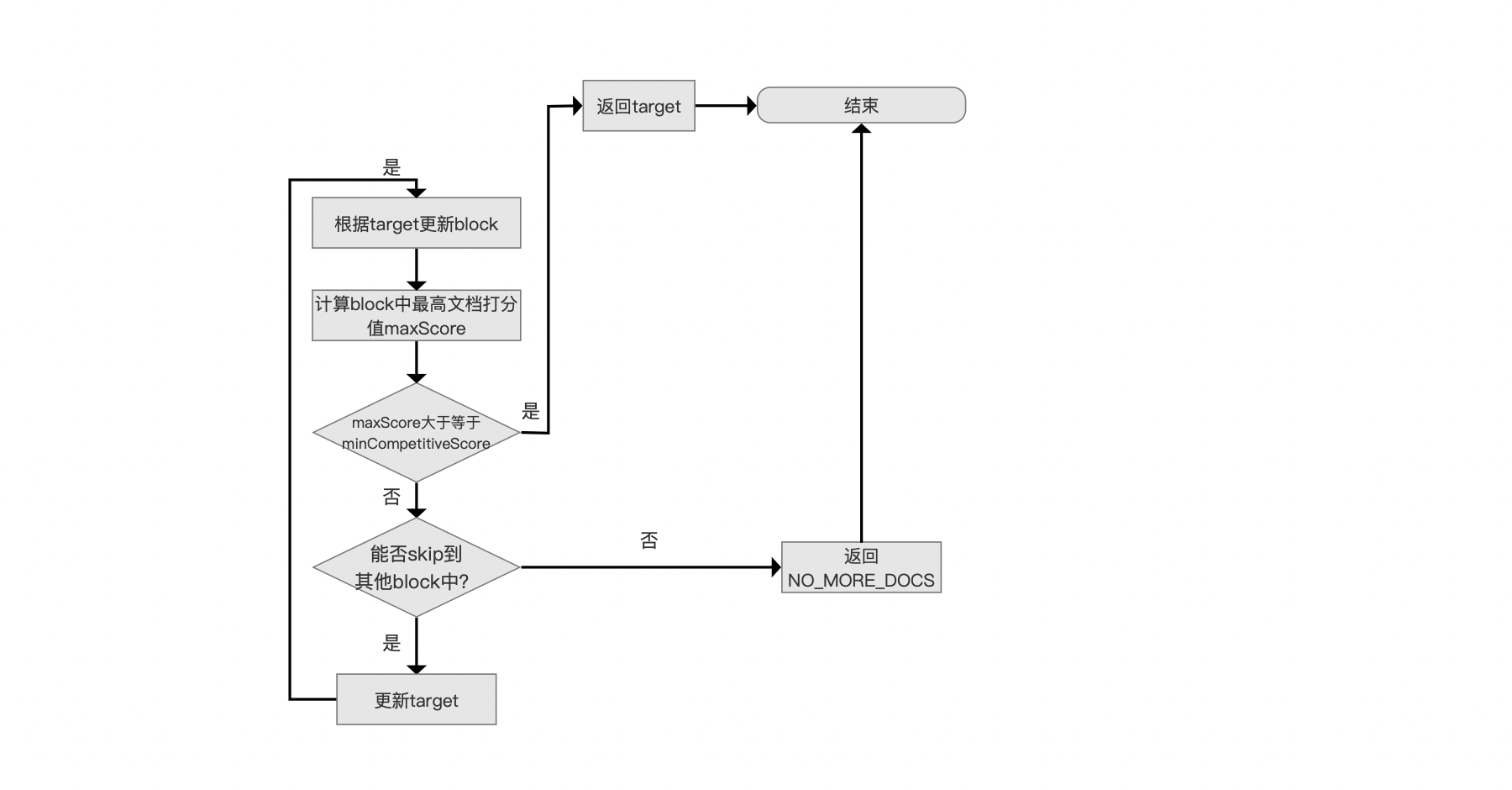
当前target跟上一个target不在同一个block,那么在执行根据target更新block后,先要计算这个block中的macScore,如果maxScore大于等于minCompetitiveScore,那么返回当前target,因为它对应的文档打分值有可能是具有竞争力的。
在执行能否skip到其他block中?时,就可以通过跳表中其他层的SkipDatum的Impact信息来进行skip,例如下图中level=1的红框标注的SkipDatum中它包含了下一层,即level=0中三个(源码中默认是8)SkipDatum中的所有Impact。如果根据这些Impact计算出的分数还是小于minCompetitiveScore,那么就可以跳过level=0这三个block。
图11:
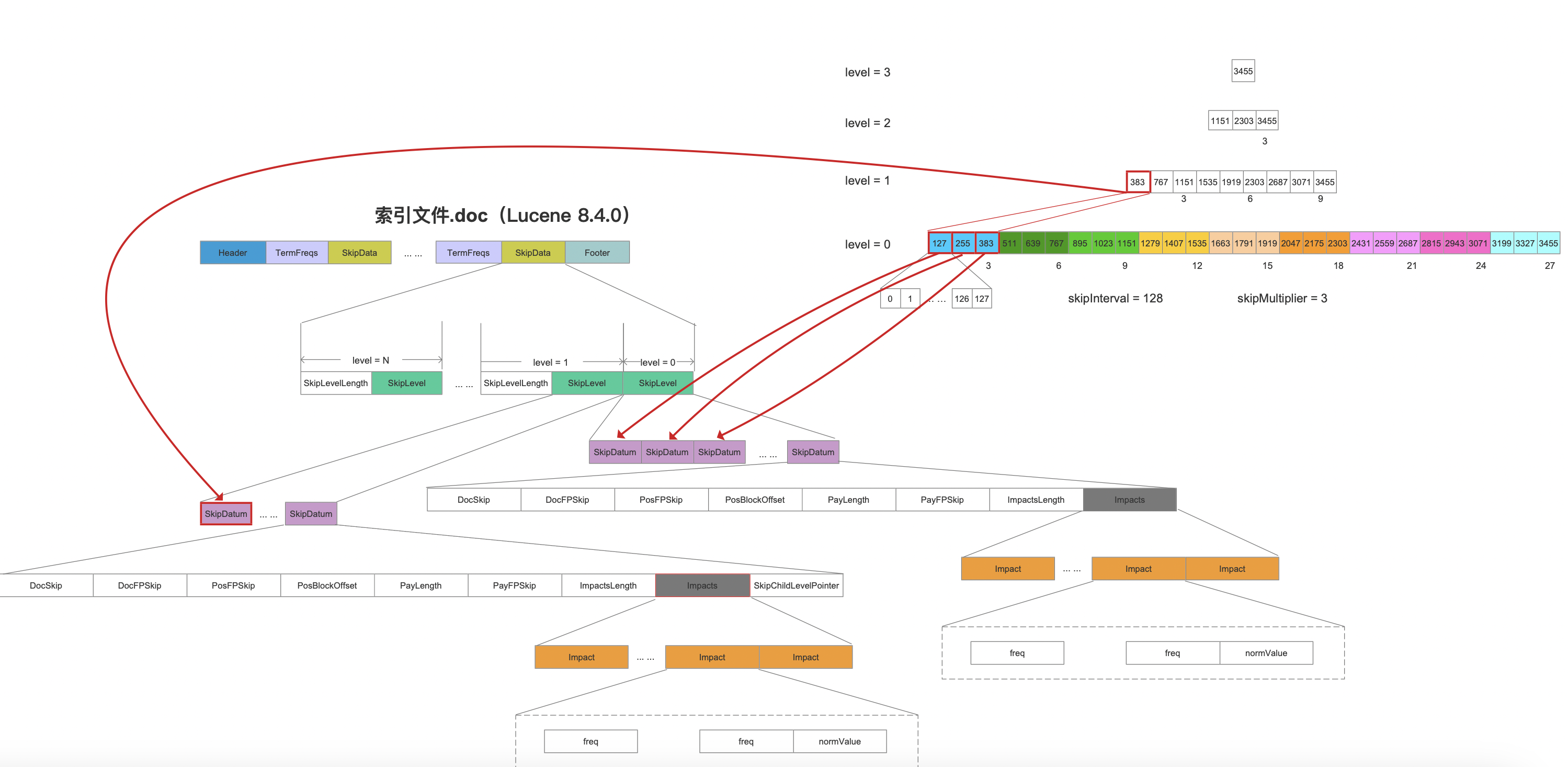
上文中如果能实现skip,那么在流程点更新target中会将target的值更新为384。
结语
Lucene中,设计跳表的目的是为了能在遍历文档号时实现skip。而ImpactDISI利用之前已有的机制,通过额外新增的Impact索引信息实现排序规则为文档打分值的TopN查询的skip。
点击下载附件