

本篇文章介绍使用了词向量(TermVector)后的域生成的倒排表,在索引阶段,索引选项(indexOptions)不为NONE的域会生成一种倒排表(上),这种倒排表的特点是所有文档的所有域名的倒排表都会写在同一张中,后续会读取倒排表来生成.doc、.pos&&.pay、.tim&&.tip、.fdx&&.fdx、.nvd&&.nvm等索引文件。而本文章中设置了TermVector的域会生成另外一张倒排表,并且一篇文档中生成单独的倒排表,同文档中的所有域名的倒排表写在同一张中,并且后续生成.tvd、.tvx文件。
尽管有两类倒排表,但是实现逻辑是类似的,一些预备知识,下面例子中出现的各种数组、文档号&&词频组合存储、position&&payload 组合存储、倒排表存储空间分配跟扩容等概念在倒排表(上)中已经介绍了,这里不赘述。
两种倒排表的区别与联系
索引选项(indexOptions)不为NONE的域.YES生成的倒排表数据结构如下:
图1:
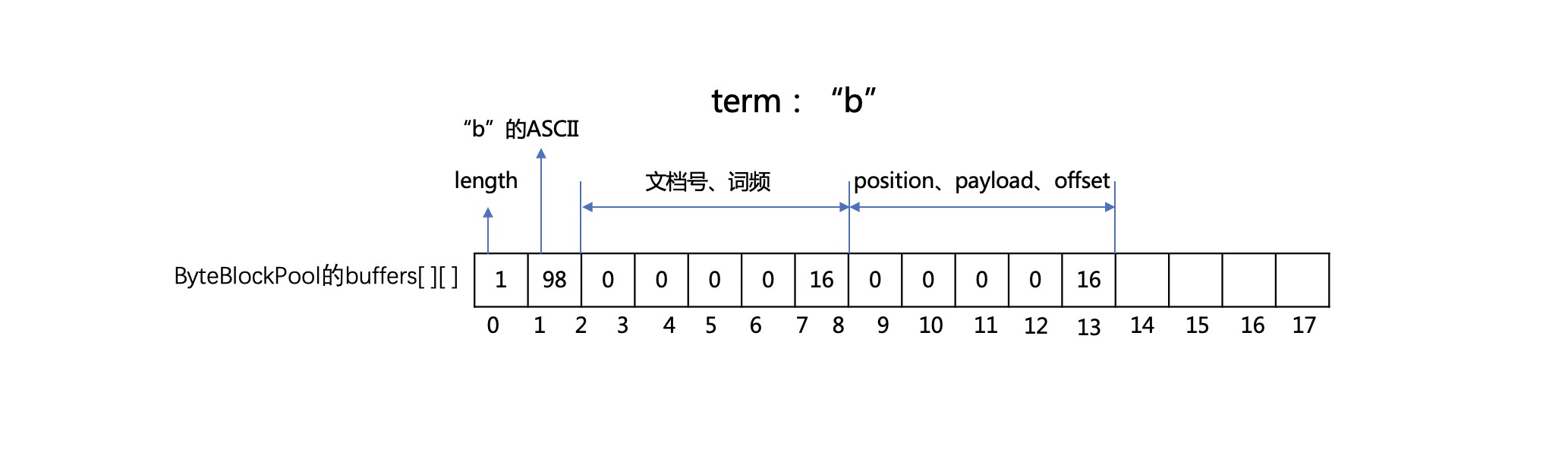
TermVector生成的倒排表数据结构如下:
图2:
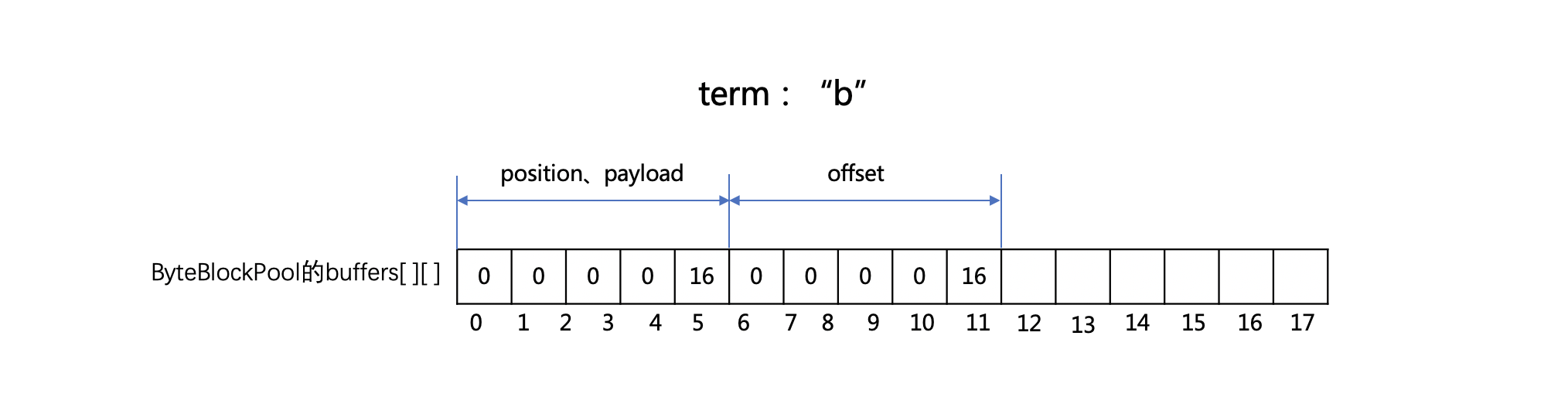
区别与联系
- 两种倒排表都记录了position、payload、offset信息
- 倒排表生成的逻辑中,先生成图1的倒排表再生成图2的倒排表,所以term的信息只需要存储一次来尽可能降低内存的使用,而TermVector生成的倒排表获得term信息的通过索引选项(indexOptions)不为NONE的域生成的倒排表信息获得。
例子
图3:
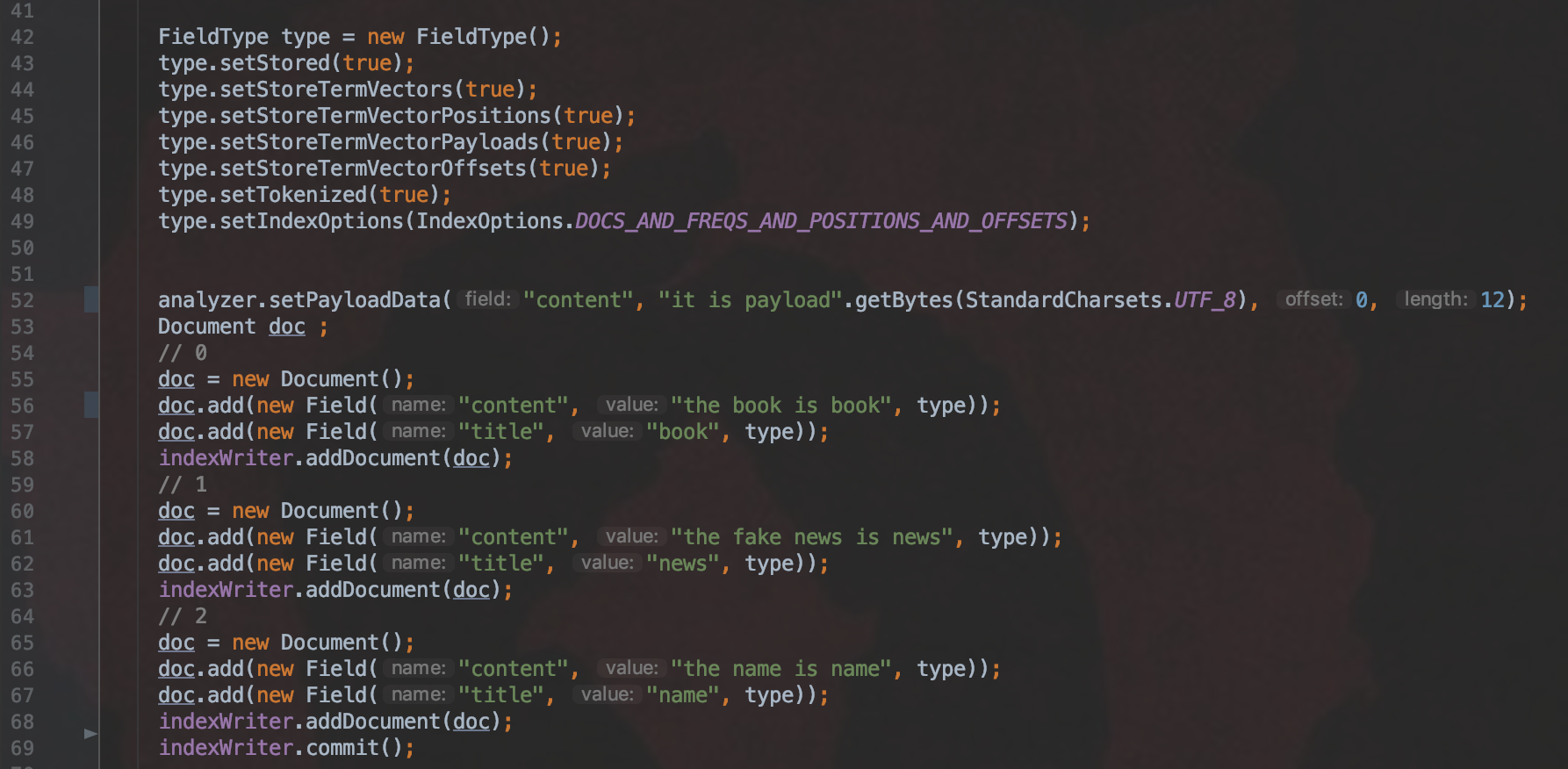
上图说明:
- 代码第49行表示倒排表中会存放 文档号、词频、位置、偏移信息
- 代码第52行表示我们为域名为"content"的域值分词后"book"添加一个值为"it is payload"的 payload值,而域名为"title"的中的"book"以及其他term都没有payload信息
- 通过自定义分词器来实现payload,当前例子中的分词器代码可以看PayloadAnalyzer
上文中提到每篇文档都会生成一个独立的倒排表,所以我们只介绍文档0中的域生成倒排表的过程。
图4:

写入过程
处理文档0
处理域名“content”
例子中使用的是自定义分词器PayloadAnalyzer,所以对于域名“content”来说,我们需要处理 “the”、“book”、“is”、"book"共四个term。
处理 “the”
图5:
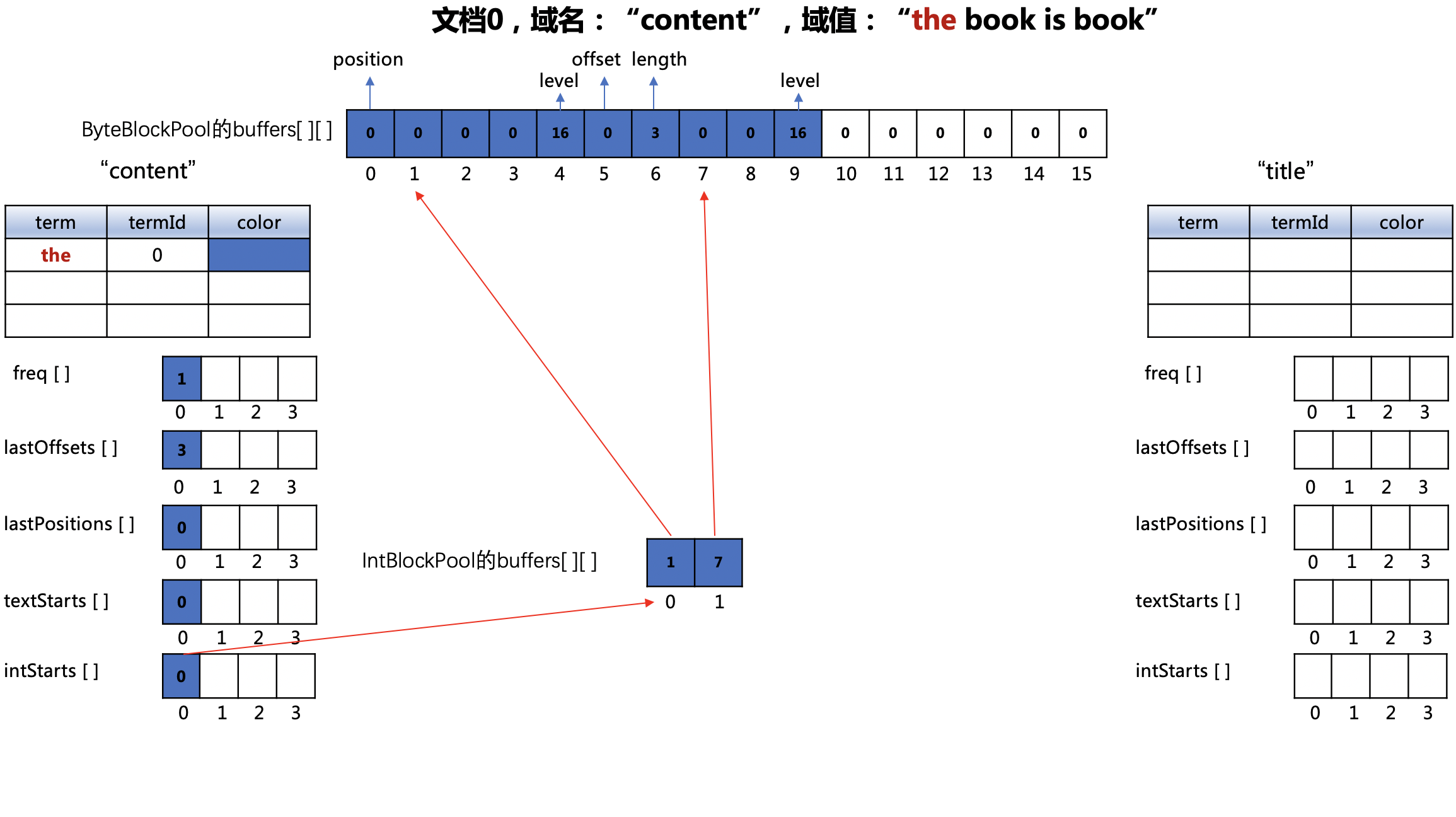
ByteBlockPool对象的buffers数组
- 下标值0:"the"在文档0中的位置,即0,由于没有payload信息,组合存储后,位置值为(0 << 1 | 0),即0
- 下标值5~6:"the"在文档0中的偏移位置以及term的长度
IntBlockPool对象的buffers数组
- 下标值0:包含"the"的位置position信息、payload在ByteBlockPool对象的buffers数组写入的起始位置**(下文不赘述这个数组的更新)**
- 下标值1:下一次遇到"the"时,它的offset信息在ByteBlockPool对象的buffers数组写入的起始位置**(下文不赘述这个数组的更新)**
lastPositions[]数组
- lastPositions[]数组下标值为"the"的termId(0)的数组元素更新为0
freq[]数组
- freq[]数组下标值为"the"的termId(0)的数组元素更新为1
lastOffsets[]数组
- lastOffsets[]数组下标值为"the"的termId(0)的数组元素更新为3,目的是为了差值存储
处理 “book”
图6:
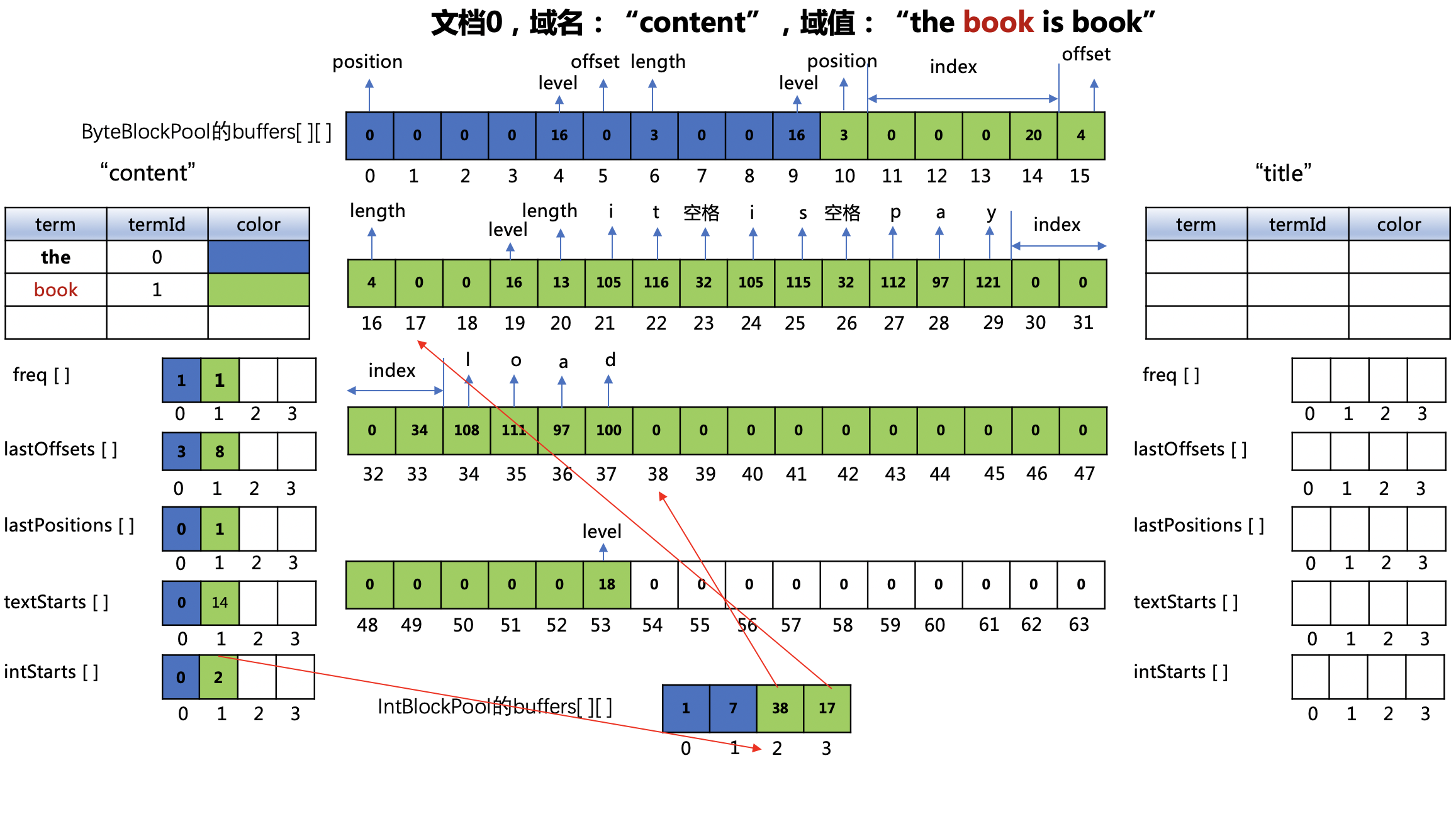
ByteBlockPool对象的buffers数组
- 下标值10:第一个"book"在文档0中的位置,即1,由于带有payload信息,组合存储后,位置值为(1 << 1 | 1),即3
- 下标值1114:下标值值1113 无法完全存储"book"在当前文档0中的payload的信息,故需要扩容,获得的新的分片的范围为下标值2033的区间,故下标值1114的4个字节成为一个索引(index),并且索引值为20。
- 下标值3031:下标值3032 无法完全存储"book"在当前文档0中的payload的信息,故需要扩容,获得的新的分片的范围为下标值3453的区间,故下标值3033的4个字节成为一个索引(index),并且索引值为34。
- 所以处理第一个"book"扩容了两次
- 下标值15~16:第一个"book"在文档0中的偏移位置以及term的长度
- 下标值2029、3437:payload的长度以及对应的ASCII
textStarts[] 数组
数组元素值14作为 索引选项(indexOptions)不为NONE的域生成的倒排表中的ByteBlockPool对象的buffers数组的下标,就可以获得"book"的term信息
处理 “is”
图7:
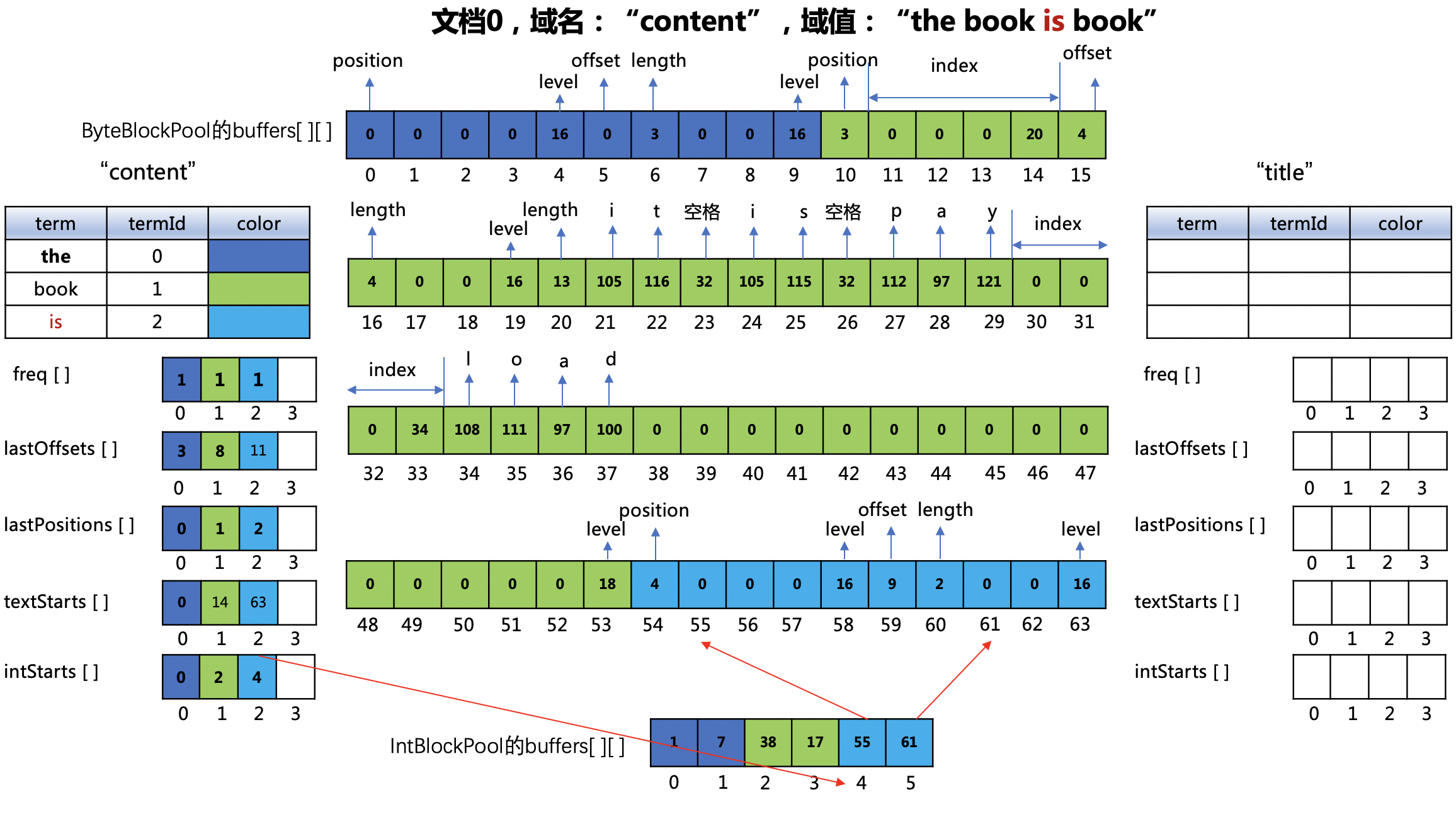
ByteBlockPool对象的buffers数组
- 下标值54:"is"在文档0中的位置,即2,由于没有payload信息,组合存储后,位置值为(2 << 1 | 0),即4
- 下标值59~60:"is"在文档0中的偏移位置以及term的长度
处理 “book”
图8:
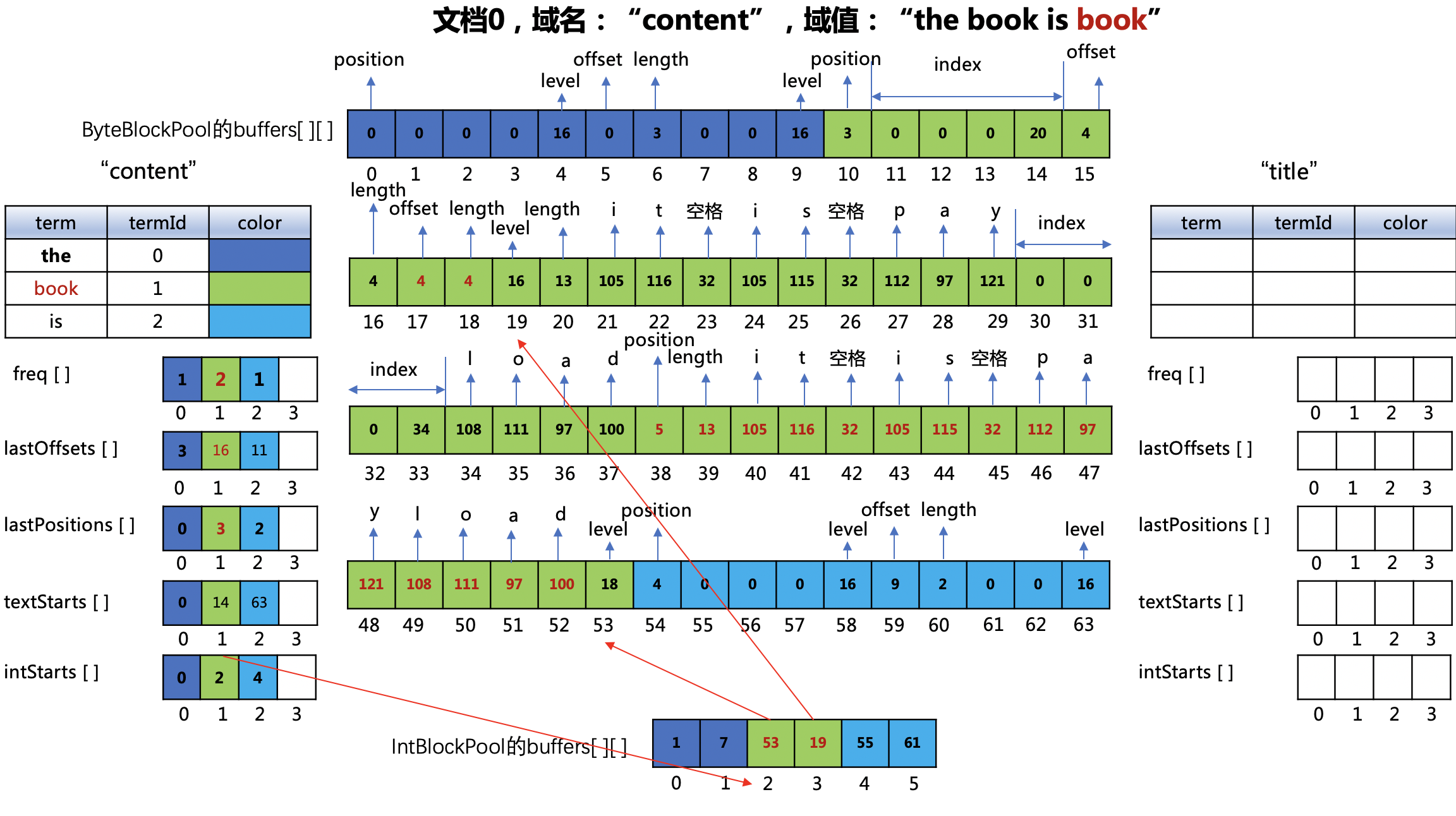
ByteBlockPool对象的buffers数组
- 下标值17~18:第二个"book"在文档0中的偏移位置以及term的长度
- 下标值38:第二个"book"在文档0中的位置,即3,根据图2获得上一个"book"在文档0中的位置是1,所以差值就是 (3 - 1)= 2,由于带有payload信息,组合存储后,位置值为(2 << 1 | 1),即5
- 下标值39~52:payload的长度以及对应的ASCII
处理域名“content”
处理 “book”
图9:
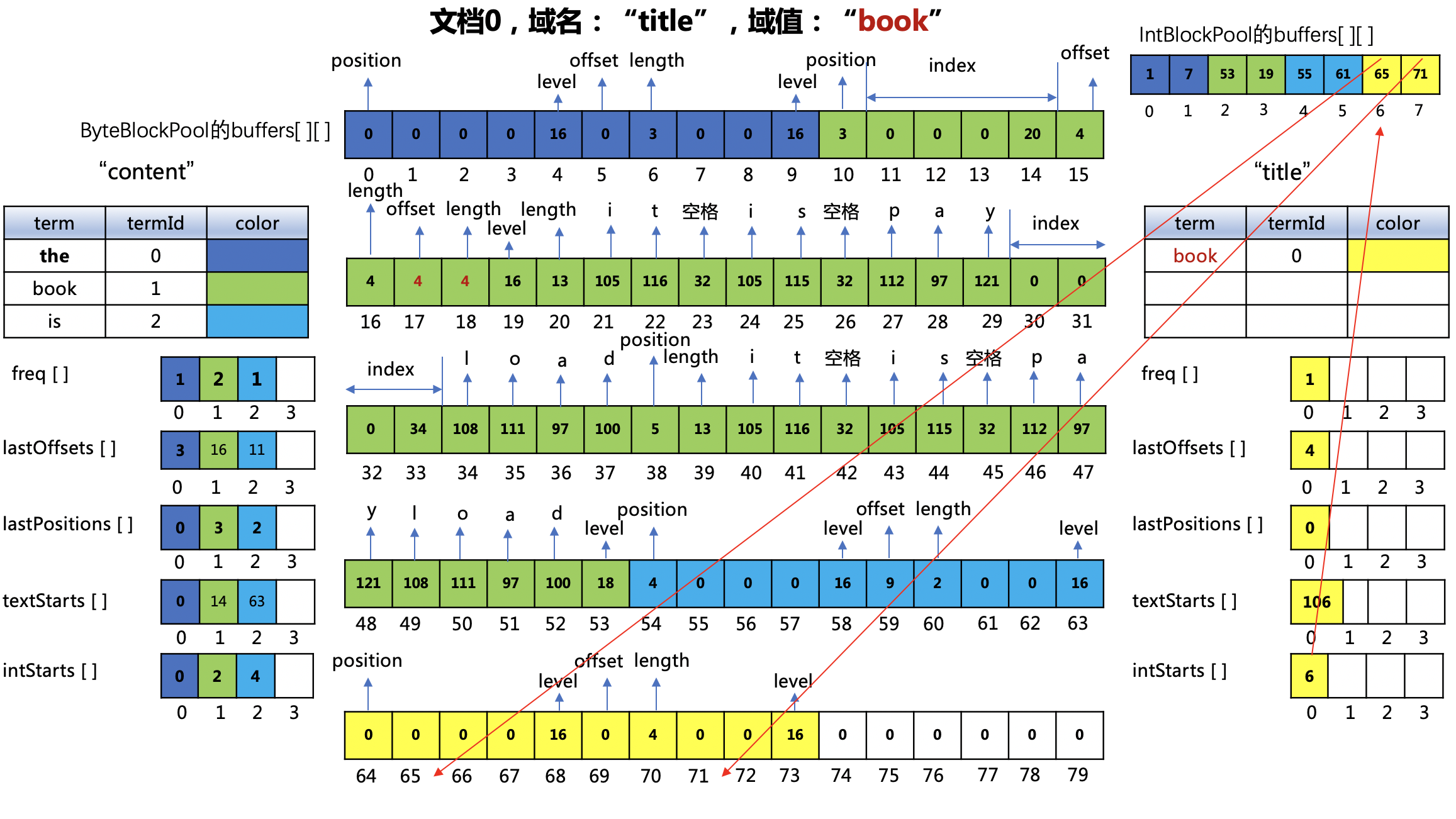
- 下标值64:"title"域的"book"在文档0中的位置,即0,由于没有payload信息,位置值为(0 << 1 | 0),即0
- 下标值69~70:"title"域的"book"在文档0中的偏移位置以及term的长度
结语
本篇文章介绍了如何构建TermVector生成的倒排表,在后面的文章中还会再介绍一个倒排表,即MemoryIndex中的倒排表
点击下载Markdown文件