

从Lucene 8.4.0开始,在写入/读取倒排信息时,即写入/读取索引文件.doc、.pos、.pay时,通过巧妙的编码方式(下文中展开)使得C2编译器能生成SIMD(Single Instruction Multiple Data)指令,从而提高了写入/读取速度。
SIMD(Single Instruction Multiple Data)
下文中关于SIMD的介绍基于以下的一些资料,如果链接失效,可以阅读文章底部附件中的备份:
- 文章一:http://www1.cs.columbia.edu/~kar/pubsk/simd.pdf
- 文章二:http://daniel-strecker.com/blog/2020-01-14_auto_vectorization_in_java/#Output Interpretation
- 文章三:http://www.songho.ca/misc/sse/sse.html
- 文章四:https://stackoverflow.com/questions/59725341/java-auto-vectorization-example
- 文章五:https://en.wikipedia.org/wiki/SIMD
- 文章六:https://prestodb.rocks/code/simd
由于本人在指令集方面有限的知识储备,只能泛泛而谈,无法准确识别上文中可能出现的错误,欢迎该方面的大佬勘误。如果能将勘误内容写到https://github.com/LuXugang/Lucene-7.5.0的issue中就更好啦。
SIMD指令集使得CPU能同时对多个值执行相同的操作:
图1:
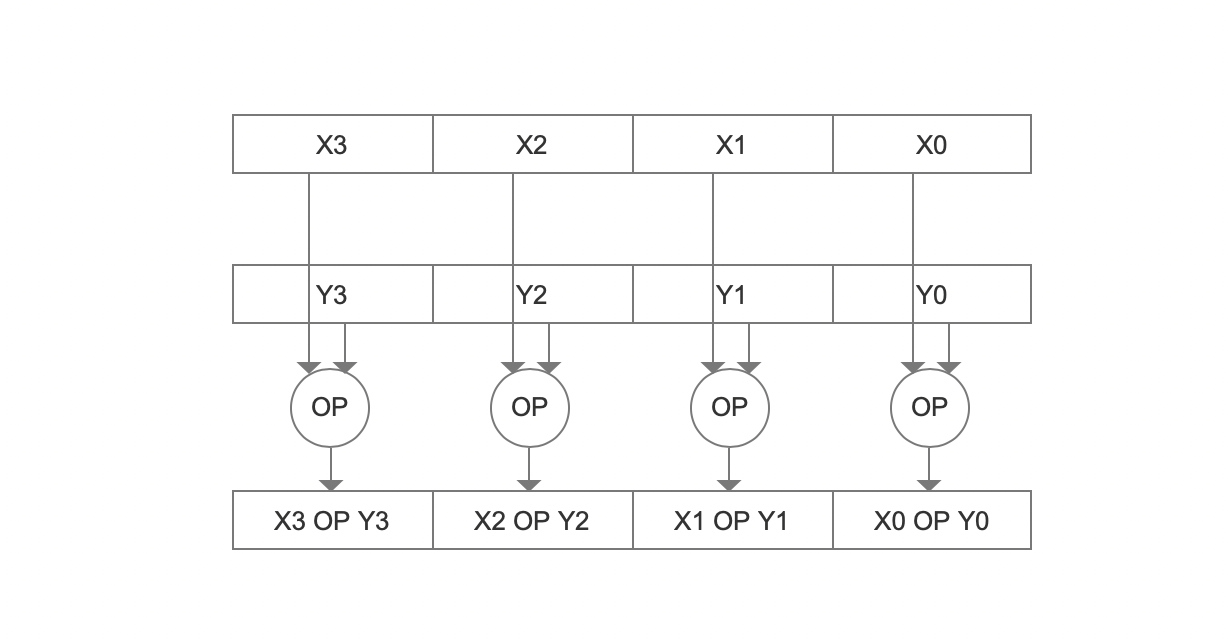
图1选自论文http://www1.cs.columbia.edu/~kar/pubsk/simd.pdf。 上图中,X、Y的值存放在128bit的寄存器中,其中X、Y的值占32bit。通过SIMD,使得可以同时计算四次运算(operand)。
自动向量化(Automatic Vectorization)
先贴出Wiki的原文:
1 | Automatic vectorization, in parallel computing, is a special case of automatic parallelization, where a computer program is converted from a scalar implementation, which processes a single pair of operands at a time, to a vector implementation, which processes one operation on multiple pairs of operands at once |
上文的大意为在一次处理过程中,由只能执行一对运算(operand)变成执行多对运算成为自动向量化。
在写完一个Java程序后,Java代码会被编译为字节码并且存放到class文件中,随后在运行之前或运行期间,字节码将再次被编译。这次字节码将被编译为机器码(native machine code)这个过程即JIT编译。
不同于C/C++,在编写Java代码时,没有显示的接口或者方式来指定向量计算,在Java中,完全是通过C2编译器来判断某段代码是否需要向量化。
SIMD In Java
Java程序中,可以通过指定虚拟机参数查看运行期间生成的汇编指令。
虚拟机参数
添加两个虚拟机参数:-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly。
另外需要下载hsdis-amd64.dylib(见附件),在Mac系统中,并将其放到/Library/Java/JavaVirtualMachines/jdk-12.jdk/Contents/Home/lib目录中即可。
例子1
在http://daniel-strecker.com/blog/2020-01-14_auto_vectorization_in_java/ 中详细的介绍了如何判断Java程序运行时是否使用了SIMD,这里不赘述展开。
例子2
通过下面的例子做一个粗糙的性能比较(JDK8),demo地址见:https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo8.7.0/src/main/java/io/simd/SIMDTest.java 。
1 | public class SIMDTest { |
下图是重复执行二十次获得的duration的最小值:
图2:
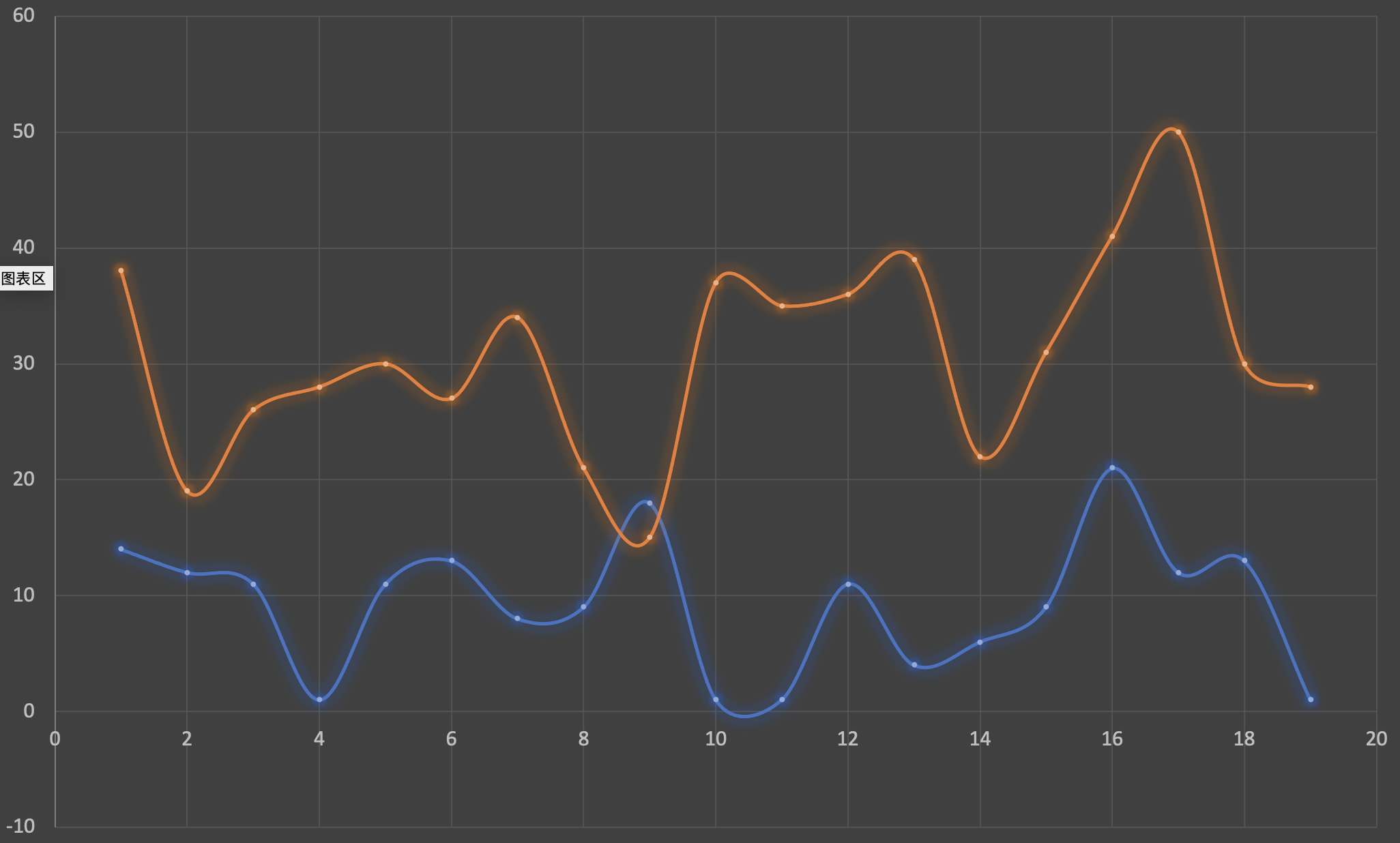
图2中Y轴的单位为ns,通过虚拟机参数-XX:UseSSE=0 -XX:UseAVX=0 -XX:-UseSuperWord来关闭C2编译器的自动向量化。
SIMD In Lucene
在这个issue中,详细的介绍了基于SIMD写入/读取倒排表信息的所有相关信息。其核心为在写入/读取阶段,通过巧妙的编码方式,使得能让编译器识别这段代码应该使用SIMD指令。
我们通过介绍倒排表信息的压缩/解压来介绍这个巧妙的编码方式。
倒排表信息的压缩
倒排表信息即索引文件索引文件.doc、.pos、.pay中的内容,其中索引文件.doc中的文档号、词频信息,索引文件.pos中位置信息,索引文件.pay中的payload、偏移信息都会在压缩后再写入到索引文件中。
其压缩的核心思想就是bitPacking,也就是在文章PackedInts(一)中提到的固定位数按位存储的方式,通过bitPacking对128个long类型的整数进行压缩处理。
固定位数按位存储描述的是对于一组待处理的数据集合,每一个数据都用固定数量的bit存储,我们称之为bitsPerValue,并且bitsPerValue的大小取决于数据集合中的最大值所需要的bit数量,如果有以下的数据集合:
1 | {3, 2, 9, 5} |
上述集合中的最大值为9,它对应的二进制为0b00001001,可见有效的bit数量为4,即bitsPerValue的值为4,那么只需要存储1001就可以来描述数值9。根据上述固定位数按位存储的概念,以数值2为例,故需要存储0010来描述它。
我们以一个例子继续介绍倒排表信息的压缩。
如果有一个待压缩的词频信息集合,并且bitsPerValue的值为4,我们用long类型的数组来描述这个集合,并且该集合中有128个词频信息,如下所示:
图3:

压缩的过程为两次收缩(collapse)操作:
第一次收缩操作
根据bitsPerValue的值使用对应三种收缩方式中的一种:
表一
| bitsPerValue | 收缩方式 |
|---|---|
| bitsPerValue <= 8 | collapse8 |
| 8 < bitsPerValue <= 16 | collapse16 |
| bitsPerValue > 16 | collapse32 |
表一中的三种收缩方式大同小异,故这里我们只以collapse8为例展开介绍。
收缩方式collapse8描述的是对于bitsPerValue <= 8的待压缩的数据,对每个数据按照固定的8个bit进行压缩,这个过程为第一次收缩操作。
我们先对照collapse8的代码做一个简单的介绍:
图4:

图4中,第84行的参数arr即包含128个long类型数值的数组,并且数组中的最大值不超过256,即bitsPerValue <= 8。
另外第85行的循环次数为16,因为第86行中,每一次循环的会同时处理8个数值,由于一共有128个数值,故需要循环16次。
图4中的第86行代码,我们会提出两个疑问,如下所示:
疑问一:为什么一次循环处理8个数值?
正如上文介绍的,第一次收缩操作的目的是将每个数据按照固定的8个bit进行压缩,由于数组arr[ ]是long类型,那么一个占64个bit的long类型的数组元素就可以存储8个占用8个bit的数据,即将8个数组元素塞到一个数组元素中,如下所示:
图5:
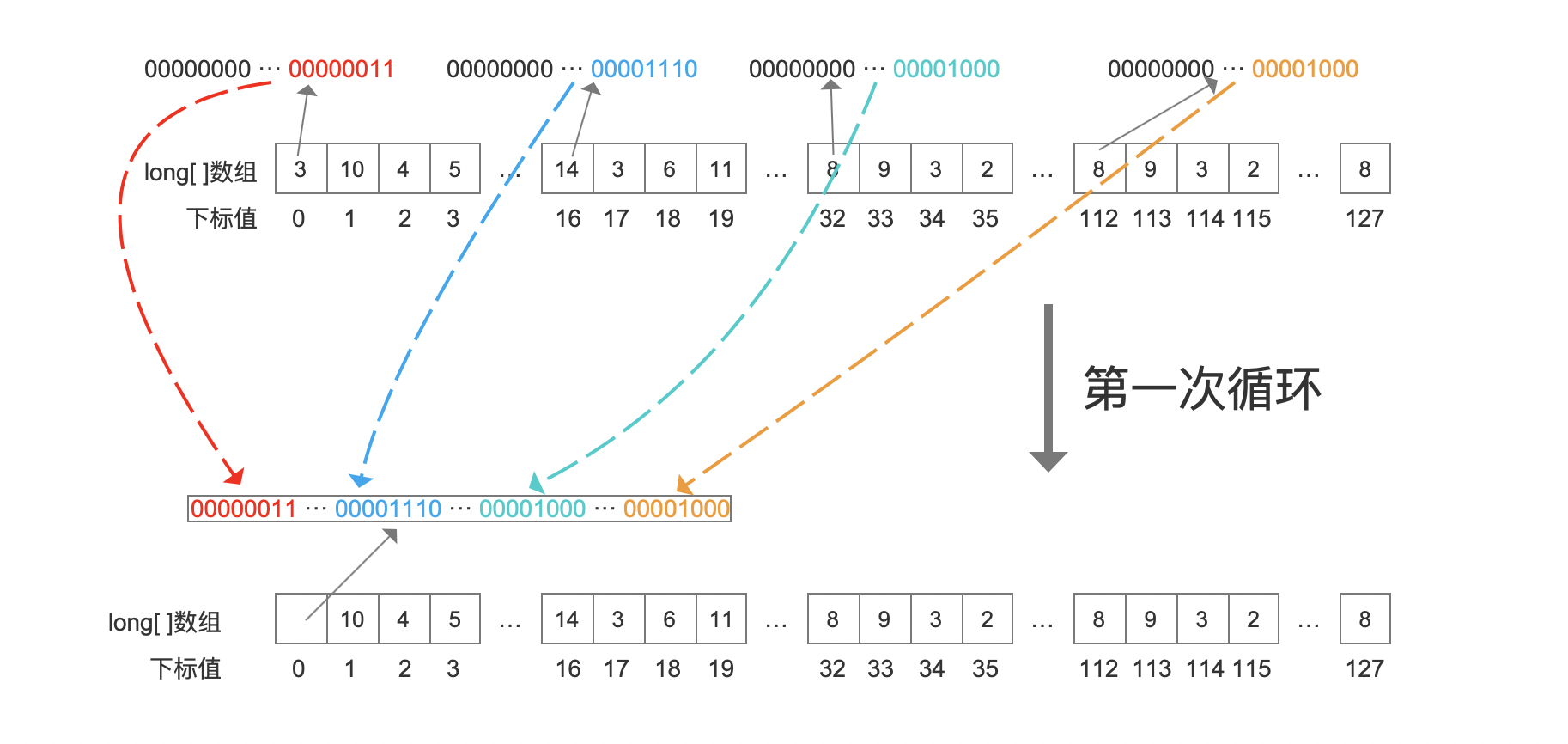
由于画图界面有限,图5中仅给出8个数值中的4个进行收缩操作。可见在第一次循环中,对8个数据各自取低位的8个bit,组合到了一个占64个bit的long类型的数组元素中。
图5中第一个数组元素的值未显示是因为数值对应的十进制位数较多,会影响图的美感。
疑问二:每次循环如何选择8个数值?
从图4跟图5可以看出,第一次循环选择的8个数值为数组下标为0、8、16、32 … 112的数组元素。为什么要按照这种方式选择,或者说为什么不选择下标值0~8的前8个数组元素呢以及其他方式?对于该疑问我请教了实现该方法的PMC(Project Management Committee),如下所示:
图6:
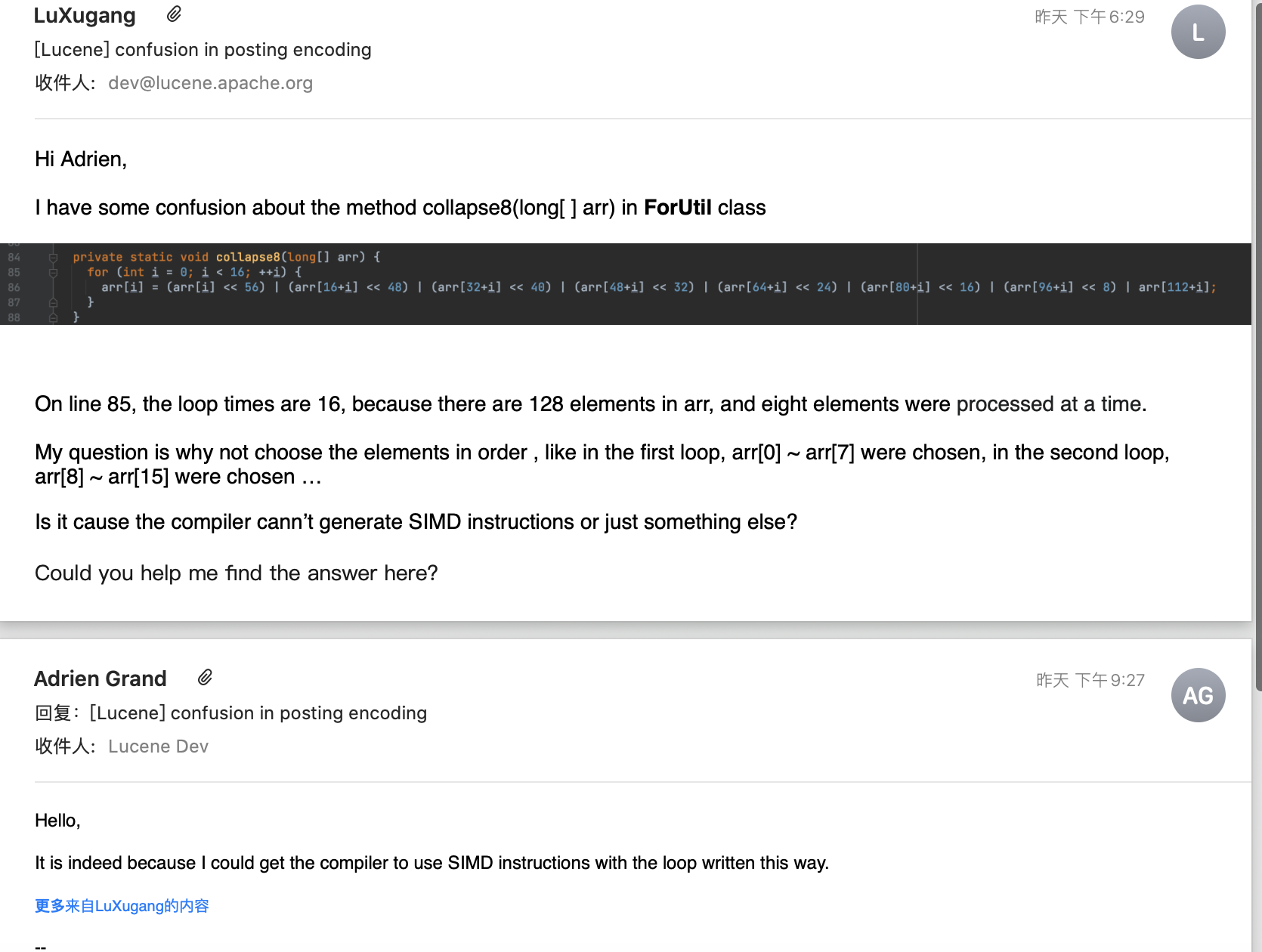
正如Adrien Grand回复的那样,按照图4中的选择方式可以让C2编译器生成SIMD指令。至于为什么采用这种方式就能生成SIMD指令,在issue中说到,作者是受到这篇文章的启发:https://fulmicoton.com/posts/bitpacking/ (如果链接失效,可以看附件中的文章Of bitpacking with or without SSE3)。感兴趣的朋友可以阅读下,本文不展开介绍。在Java中,可以通过运行期间生成的汇编代码判断是否生成了SIMD指令。
第二次收缩操作
图5中,以数组的第一个数组元素为例,在进行了第一次收缩操作后,该数组元素中存储了8个数据,每个数据占用8个bit,又因为该数组的bitsPerValue的值为4,所以每个数据还有4个bit(高4位)是无效的,无效指的是这些bit不参与描述一个数据。那么随后会通过第二次收缩操作消除这些bit。
图3的数组在经过第一次收缩操作后,128个数据分布在了前16个数组元素中,即下标值0~15的数组元素存放了原始的128个数据。还是以第一个数组元素为例,该数组元素64个bit中有32个bit是无效的,那么我们通过下面的方式将这些无效的bit变成有效的,如下所示:
图7:
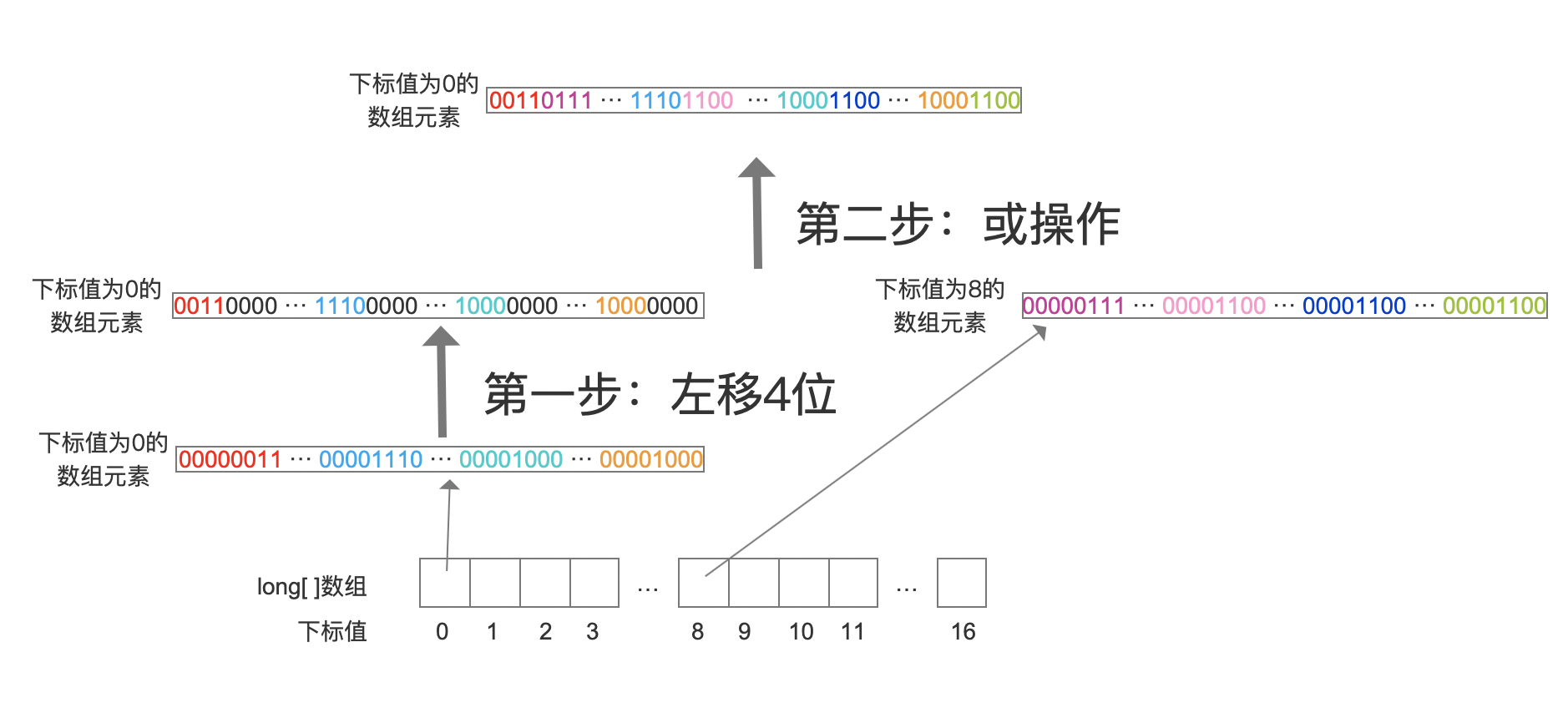
图7中,第一个数组元素,即下标值为0的数组元素,先执行第一步的左移4个bit,然后跟下标值8的数组元素进行第二步的或操作。注意的是下标值为8的数组元素不需要位移操作。第二步的或操作结束后,下标值为8的数组元素中的有效bit就覆盖了第一个数组元素中的无效的bit了,意味着存储了16个数据。
两次收缩操作使得用来描述数据的long类型的值中所有的bit都是有效的,即都会参与用于描述数据。最终128个long类型的数据被压缩成8个long类型的数值。
为什么选择下标值8的数组元素跟第一个数组元素进行或操作?
或者说可以选择其他数组元素进行或操作吗,答案是可以的,但是源码中的选择方式可以使得C2编译器在运行期间生成SIMD指令。同样的,想深入理解这种选择方式的话可以阅读https://fulmicoton.com/posts/bitpacking/ 这篇文章。
结语
无。
点击下载附件