

2020年11月3号,Lucene发布了最新的版本8.7.0,本篇文章将会对Change Log中几个变更展开介绍下。
LUCENE-9510
该issue的原文如下:
1 | Indexing with an index sort is now faster by not compressing temporary representations of the data. |
上文大意为:当设置了段内排序IndexSort后,索引(Indexing)的速度比以前更快了,因为不再压缩临时的数据。
这里的temporary representations of the data指的是存储域的域值,它最终存储到索引文件.fdt中。在文章索引文件的生成(二十四)之fdx&&fdt&&fdm中我们说到,在添加每篇文档的过程中,当生成一个chunk时,域值会被压缩处理并写入到chunk中。如下所示:
图1:
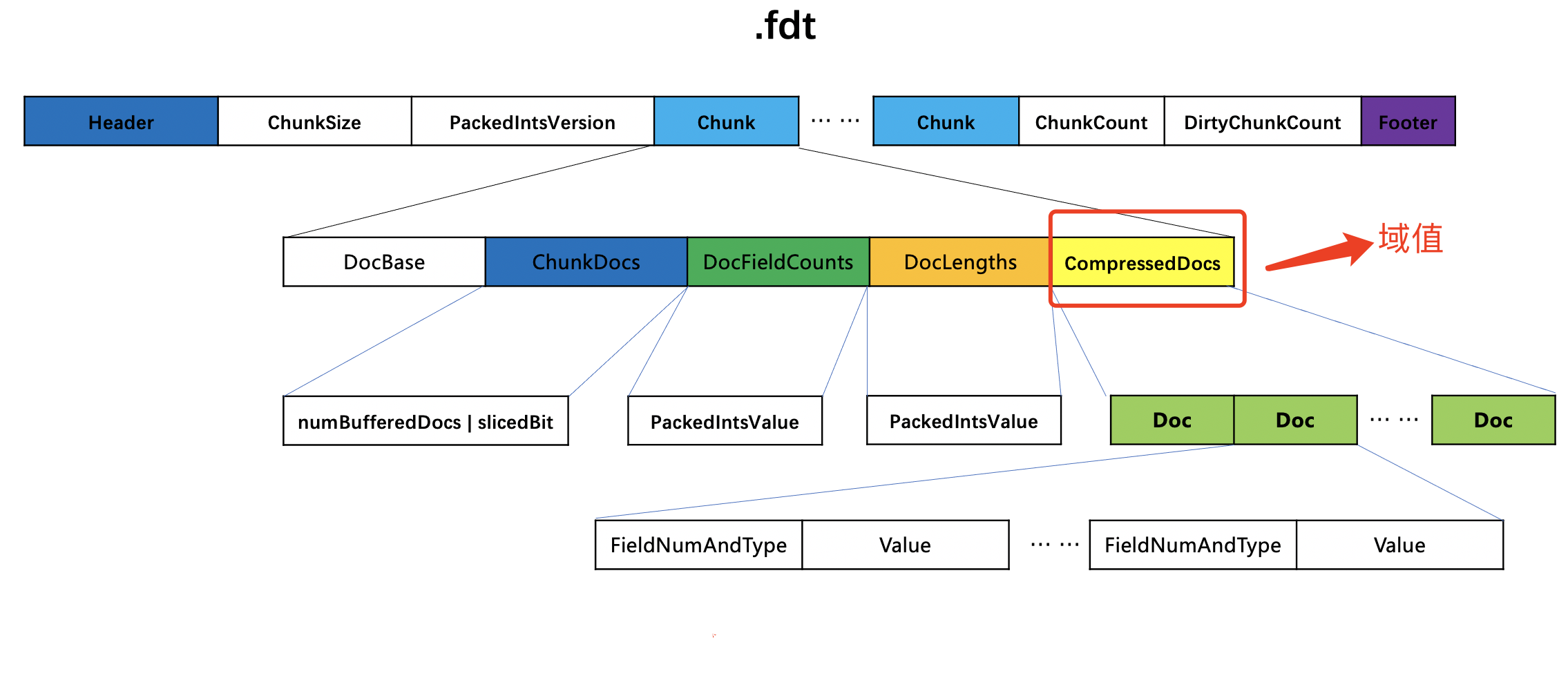
如果设置了段内排序,那么在flush阶段会读取chunk中的域值,然后写入到新的chunk中,并生成新的索引文件.fdt(因为持续添加/更新/删除文档的过程中,是无法排序的,所以只能在flush阶段,即生成一个段时才能排序)。这意味着排序后的文档对应的域值分布在不同的chunk中,就会导致随机访问,即会出现chunk的重复解压,这将导致索引(Indexing)速度的降低。那么在索引期间生成的用于描述存储域的索引文件就是下文中 temporary files:
1 | We noticed some indexing rate regressions in Elasticsearch after upgrading to a new Lucene snapshot. This is due to the fact that SortingStoredFieldsConsumer is using the default codec to write stored fields on flush. Compression doesn't matter much for this case since these are temporary files that get removed on flush after the segment is sorted anyway so we could switch to a format that has faster random access. |
在Lucene 8.7.0中,索引期间使用了一个TEMP_STORED_FIELDS_FORMAT的新的codec来处理存储域,使得不再对域值进行压缩处理:
图2:

由图2可见,尽管调用了compress接口,实际上就是简单的按字节拷贝而已。
另外触发生成chunk的条件也被改为处理一篇文档就生成一个chunk,目的就是减少处理的时间,因为我们知道,如果chunk中包含多个文档号,这些文档号的信息(即图1中的chunk)都是经过编码处理的,读取一个文档的存储域信息就需要把其他文档的存储域信息都执行解码,关键是这些文档的信息很有可能并不是下一次处理需要的信息:
图3:

如果不知道maxDocsPerChunk的作用,请阅读文章索引文件的生成(二十四)之fdx&&fdt&&fdm。
最终在flush阶段,生成新的索引文件.fdt时,就使用默认的codec,生成过程就跟文章索引文件的生成(二十四)之fdx&&fdt&&fdm一致了。
LUCENE-9447, LUCENE-9486
从Lucene 8.7.0开始,对生成一个chunk的触发条件进行了修改,即图1中chunk中包含的文档数量上限值、域值的大小上限值得到了提高。这两个issue中解释了原因,并给出了测试数据,感兴趣的可以点进去看下。
LUCENE-9484
在文章构造IndexWriter对象(二)中我们知道,IndexWriter对象可以通过IndexSort实现段内的排序,使得随后生成的段都是段内有序的,并且具有相同的排序规则。另外IndexWriter在构造期间,如果索引目录中已经存在一些段,我们称之为旧段,如果这些段的排序规则跟IndexWriter中配置的不一致,那么会导致IndexWriter对象初始化失败。在Lucene 8.7.0之前, 我们需要根据IndexWriter中的IndexSort的排序规则对旧段重新排序才可以,降低了用户体验。当前issue中正是解决了这个问题。通过SortingCodecReader类封装旧段对应的reader,然后利用IndexWriter中的addIndex方法即可。使用SortingCodecReader类时,通过制定了旧段对应的reader跟IndexWriter中的IndexSort排序规则,Lucene会对reader进行重排。
LUCENE-8962
在多线程执行索引(Indexing)的过程中,当某个线程执行了flush( )、commit( )操作或者getReader( )实现NRT操作时,会使得所有的线程将对应的DWPT执行flush,可能导致生成许多的小段(small segments)。在文章查询原理(三)中我们说到,当存在多个段时,搜索的过程为依次(单线程执行搜索操作)遍历每一个段,最后对每个段的结果进行合并。大佬Michael McCandless提出了一个讨论,是否能在commit()、getReader( )的方法返回前就能将这些小段进行合并,使得减少搜索期间遍历的段的数量,降低查询时间。
故在从Lucene 8.6.0开始(Lucene 8.7.0中进行了优化),通过构造IndexWriter期间指定的配置项maxFullFlushMergeWaitMillis来实现在commit( )跟getReader( )调用期间实现对一些小段的合并。注意的是,这里的执行段的合并会阻塞commit( )跟getReader( )这两个方法,故通过maxFullFlushMergeWaitMillis来指定超时时间。如果在超时时间内没有完成小段的合并,则commit( )跟getReader( )继续执行,在这两个方法返回后,可能还存在多个小段。 maxFullFlushMergeWaitMillis的默认值为0,表示不会在commit( )跟getReader( )的调用期间执行小段的合并。