

本篇文章将介绍Lucene中向量搜索相关的索引文件。当前版本中由三个索引文件,即文件后缀名为.vec、.vex、.vem的文件,文件中包含的内容主要包括图的分层信息,每一层中节点的编号,向量值,相连的邻居节点等信息。
向量搜索的实现基于这篇论文:Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs,由于索引文件中有些信息的概念其实是先需要了解这篇论文或者HNSW算法才可以,并且写这篇文章的主要目的是为了在随后介绍NHSW在Lucene中的实现的文章做准备的,因此通过这篇文章只需要了解索引文件中存放了哪些信息,以及对应的数据结构就可以了。
先给出这三个索引文件的数据结构之间的关联图,然后我们一一介绍这些字段的含义:
图1:
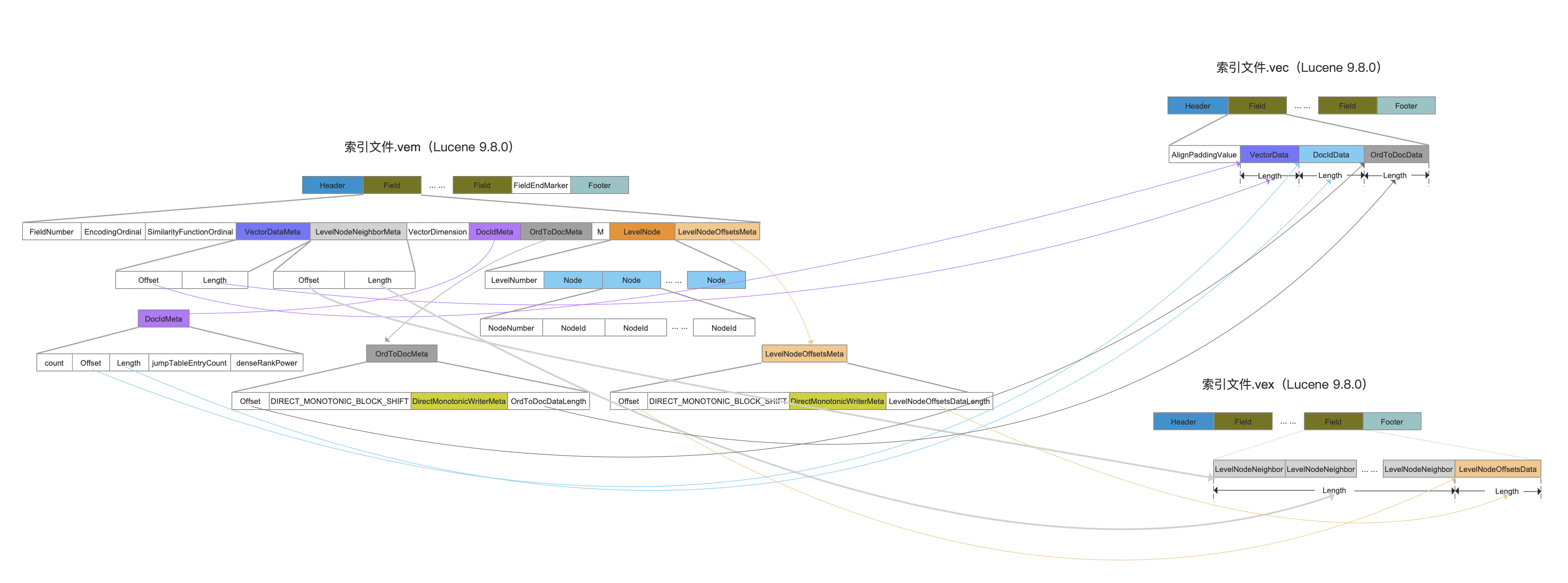
点击查看大图
数据结构
这三个索引文件总体上由Header、一个或者多个Field、以及Footer组成。
- Header:主要包含文件的唯一标示信息,版本号,索引名字等一些信息
- Footer:记录校验和(checksum)算法ID和校验和,在读取索引文件时可以校验索引文件的合法性
- Field: 该字段中包含了某个域下的所有向量信息。注意到该字段可以是多个,取决于一个段中定义的向量域(KnnFloatVectorField)的数量,例如下图中定义了两个向量域,域名分别为别
vector1以及vector2,那么在索引文件中就会有两个Field。
图4:

.vec
索引文件.vec中主要存放的数据为所有的向量值vectorData、文档号信息DocIdData以及节点编号与文档号的映射关系OrdToDocData。
图5:
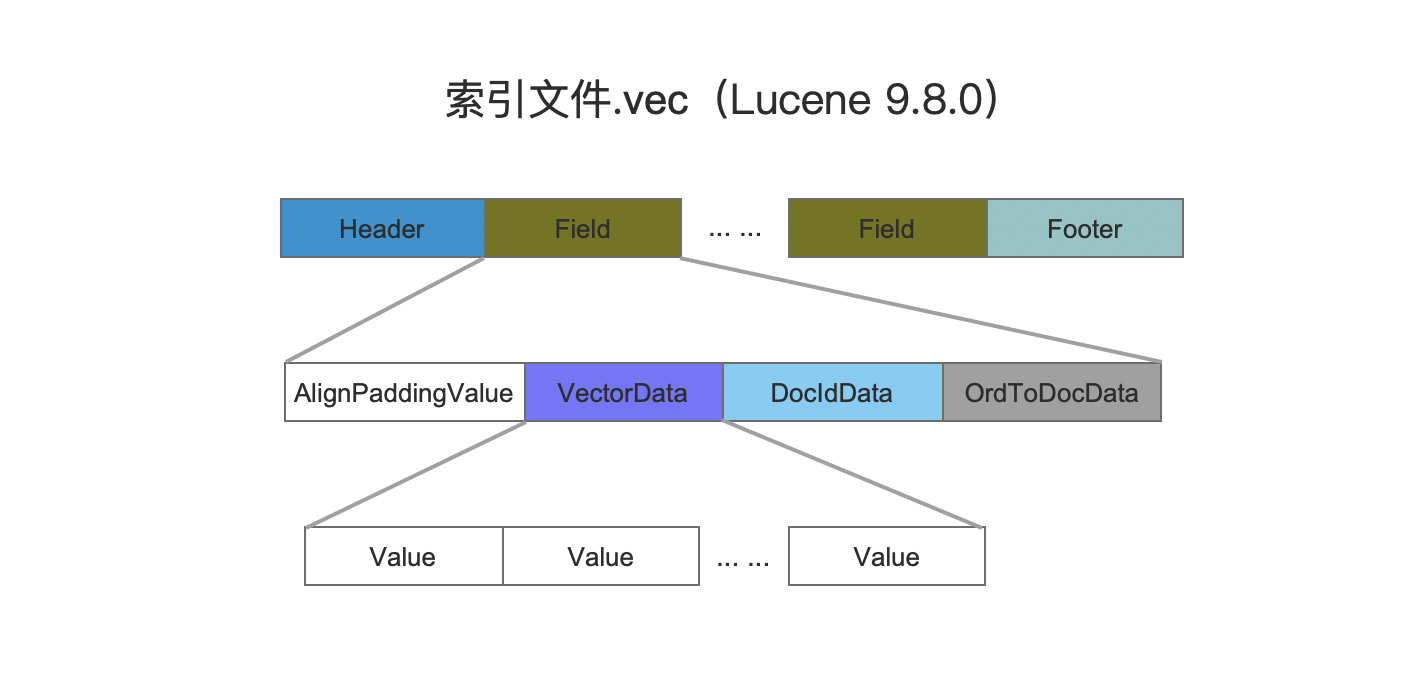
AlignPaddingValue
对齐字节数。
Lucene按照字节单位写入到文件中,在后续的数据写入之前会先将当前的文件指针对齐到指定的字节倍数(写入填充值0),来优化内存映射文件(mmap)的读取性。AlignPaddingValue的值必须是2的幂。
VectorData
图6:
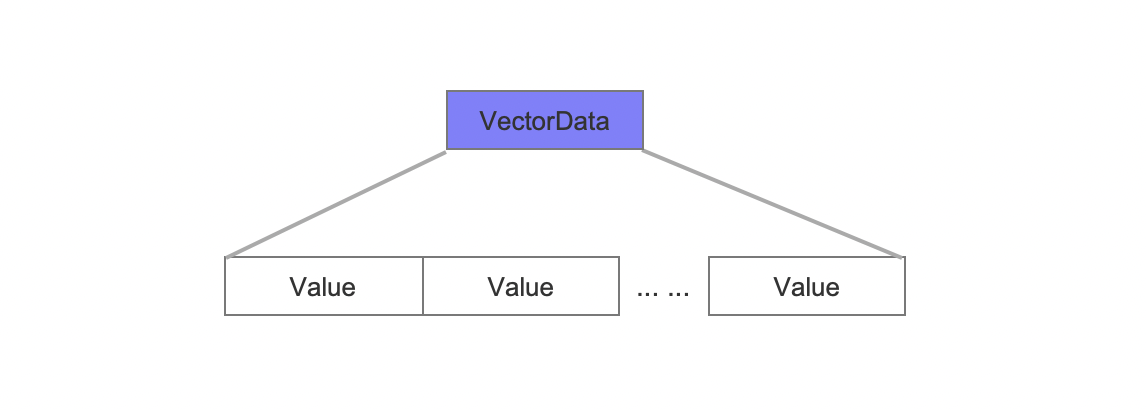
向量值。
图6中每一个Value对应一篇文档中某个向量域的向量值。每个向量值使用相同数量的字节存储。例如图4中第50行-0.18344f, 0.95567f, -0.46423f对应一个Value。
DocIdData
图7:
文档号集合。
该字段存放包含向量域的文档号。使用IndexedDISI存储文档号。
OrdToDocData
图8:

节点编号与文档号的映射关系。
每一个向量都有一个节点编号(node id),通过OrdToDocData,就可以根据节点编号找到对应的文档号,也就是包含这个向量的文档号。在添加文档过程中,每一个向量根据添加的先后顺序,都会被赋予一个从0开始递增的节点编号。例如图9中,添加了三篇文档,其中文档0中向量的节点编号为0,文档2中向量的节点编号为1。另外注意的是,同一篇文档中只允许定义一个相同域名的向量域。
图9:

在图6中我们说到,所有的向量值都存放在VectorData,在读取阶段就可以根据节点编号以及向量值对应的字节数,实现随机访问向量值。
最终OrdToDocData经过DirectMonotonicWriter编码压缩后写入到索引文件中。
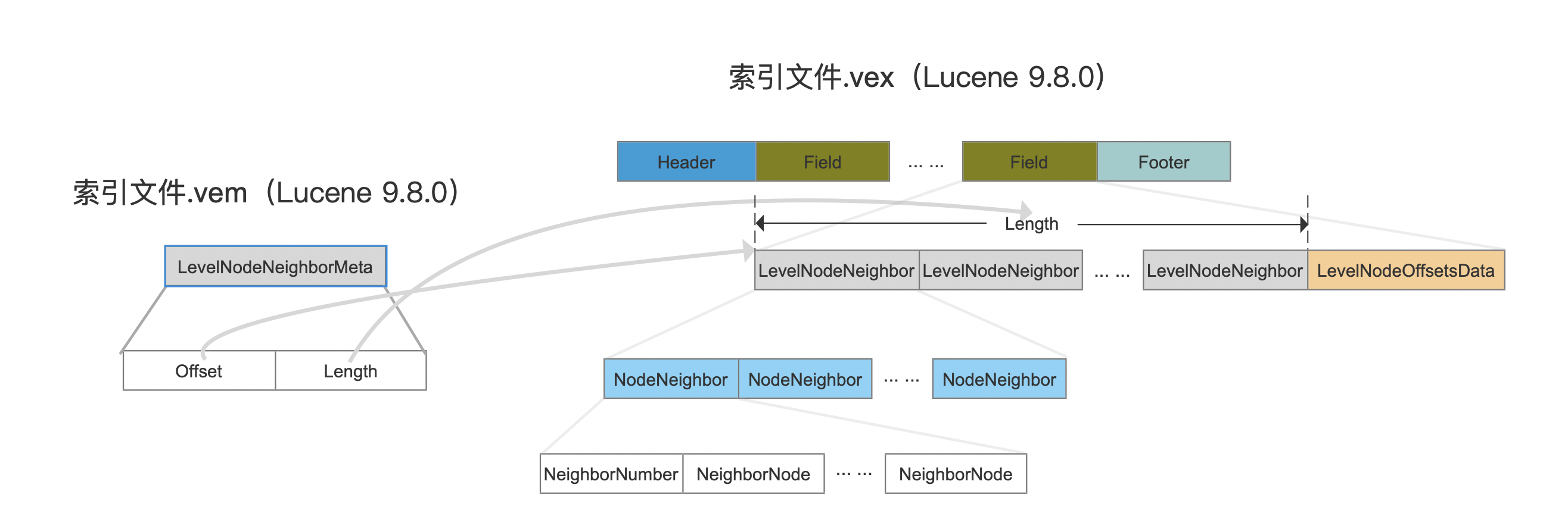
.vex
图10:
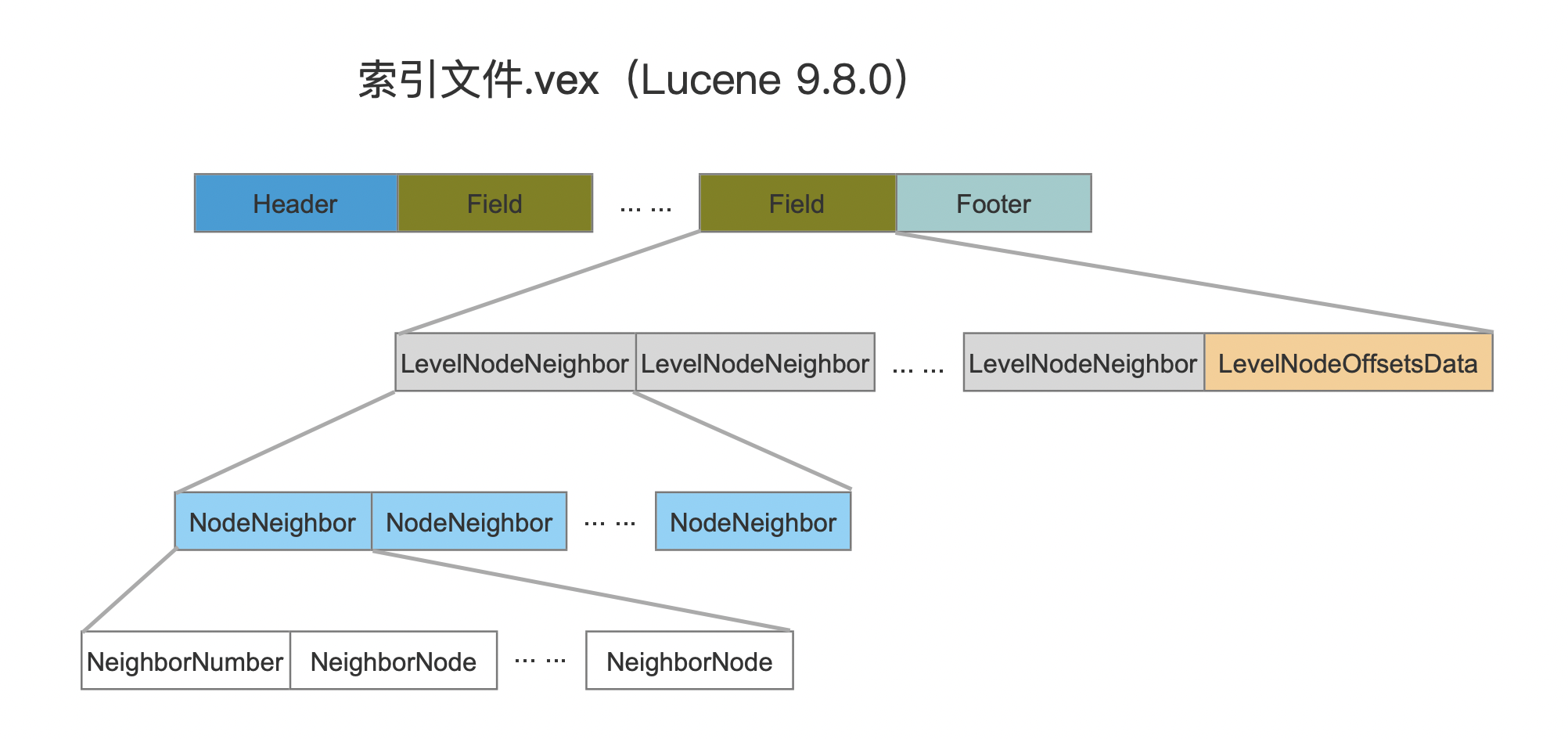
LevelNodeNeighbor
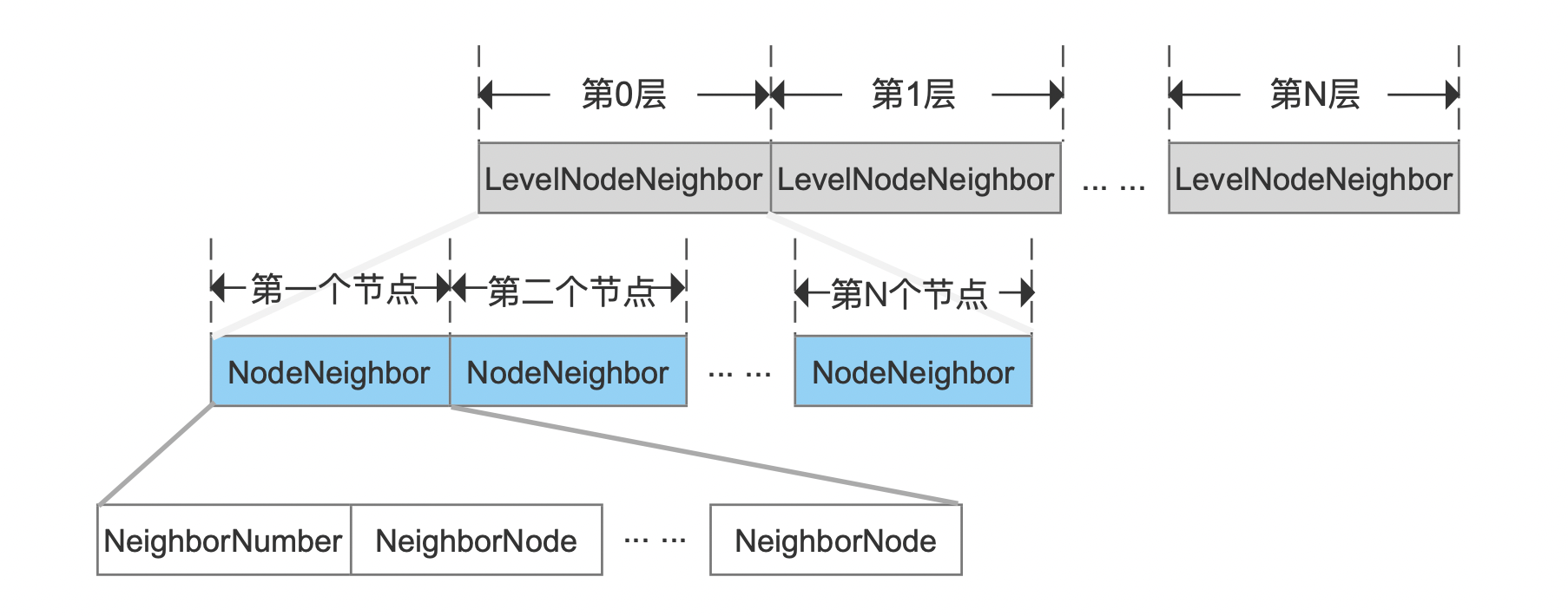
图11:
邻居节点集合。
图11中,先按照层级划分邻居节点集合,从左到右LevelNodeNeighbor分别代表第0层、1层。。。N层。随后在某一层中,按照该层中节点编号顺序,从左到右NodeNeighbor分别代表该层中第一个、二个、N个节点的邻居节点集合。
- NeighborNumber:邻居节点的数量
- NeighborNode:邻居节点的编号
另外由于节点的邻居节点集合已经按照节点编号排序,因此会先计算相邻之间的差值(差值存储),使得尽量使用少的bit来存储。例如有以下的邻居节点集合:
1 | [1, 12, 18, 27, 92, 94, 139, 167, 250] |
差值计算后的集合如下:
1 | [1, 11, 6, 9, 65, 2, 45, 28, 83] |
由于在存储这个集合时,会选择固定bit位数,即按照集合中最大值所需要的bit进行存储,优化前后所有的值分别使用250跟83对应的bit位数存储。
LevelNodeOffsetsData
图12:

邻居节点在索引文件.vex的位置信息。
在图11中,记录了所有层中所有节点的邻居节点的信息,LevelNodeOffsetsData则是用于记录每一层的每一个节点的所有邻居节点在索引文件.vex中长度。在源码中使用一个二维数组来描述,下图是示例中的实际数据:
图13:
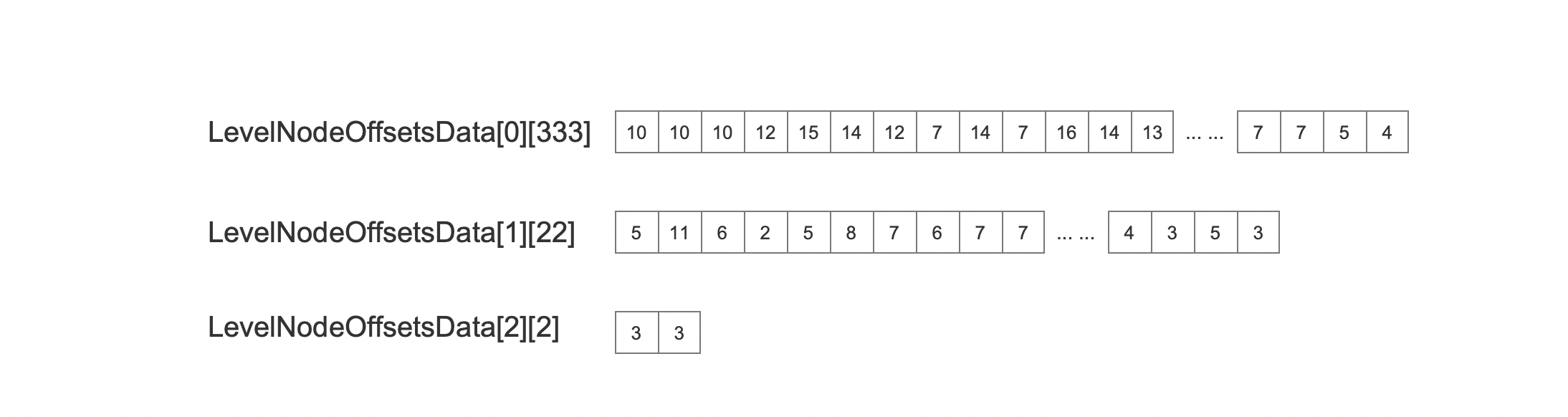
图13中,示例构建出的图结构有三层,并且第0层中有333个节点,第一层中有22个节点,第二层中有2个节点。比如下图中,在索引文件的读取阶段,第1层的第二个节点的所有邻居节点在索引文件vec中的区间如下所示:
图14:
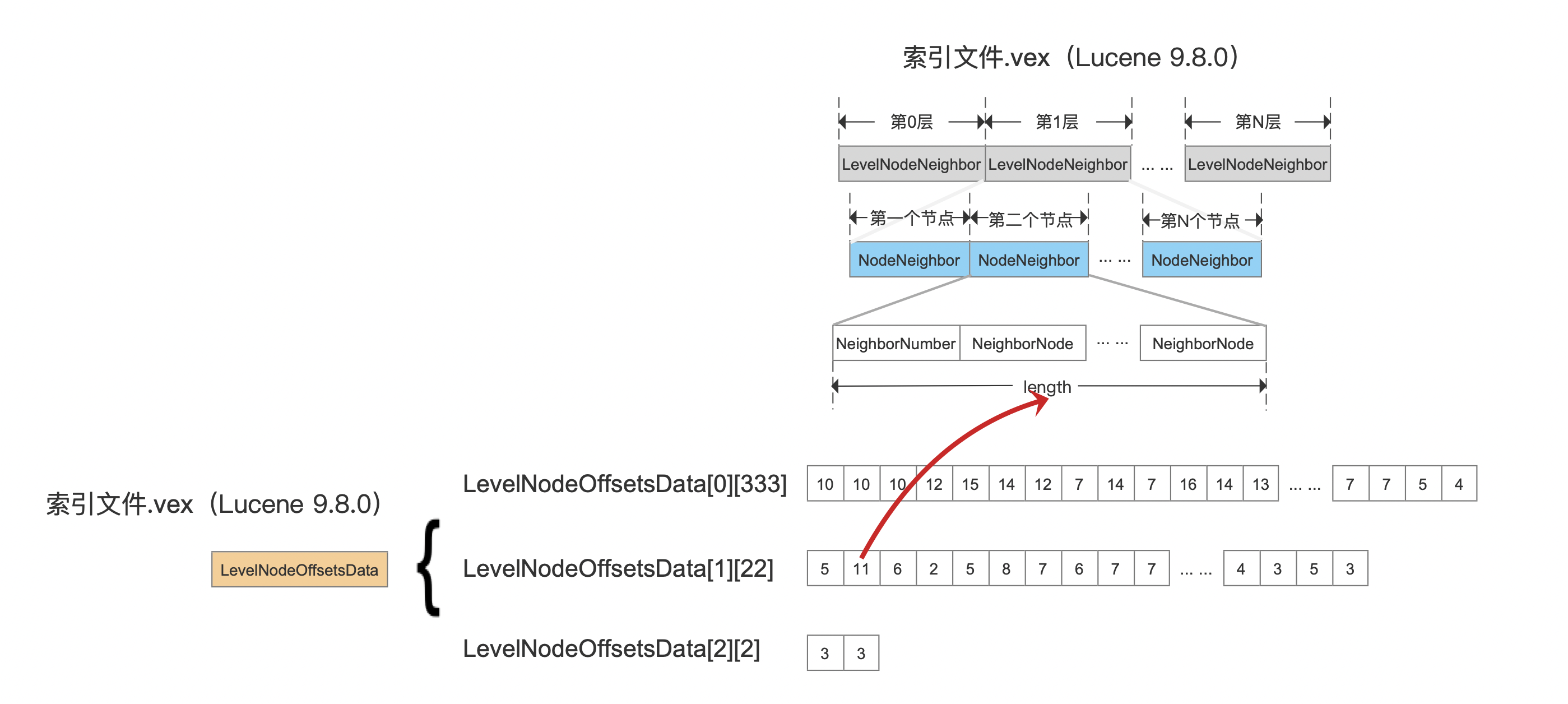
最终LevelNodeOffsetsData经过DirectMonotonicWriter编码压缩后写入到索引文件中。
.vem
图15:
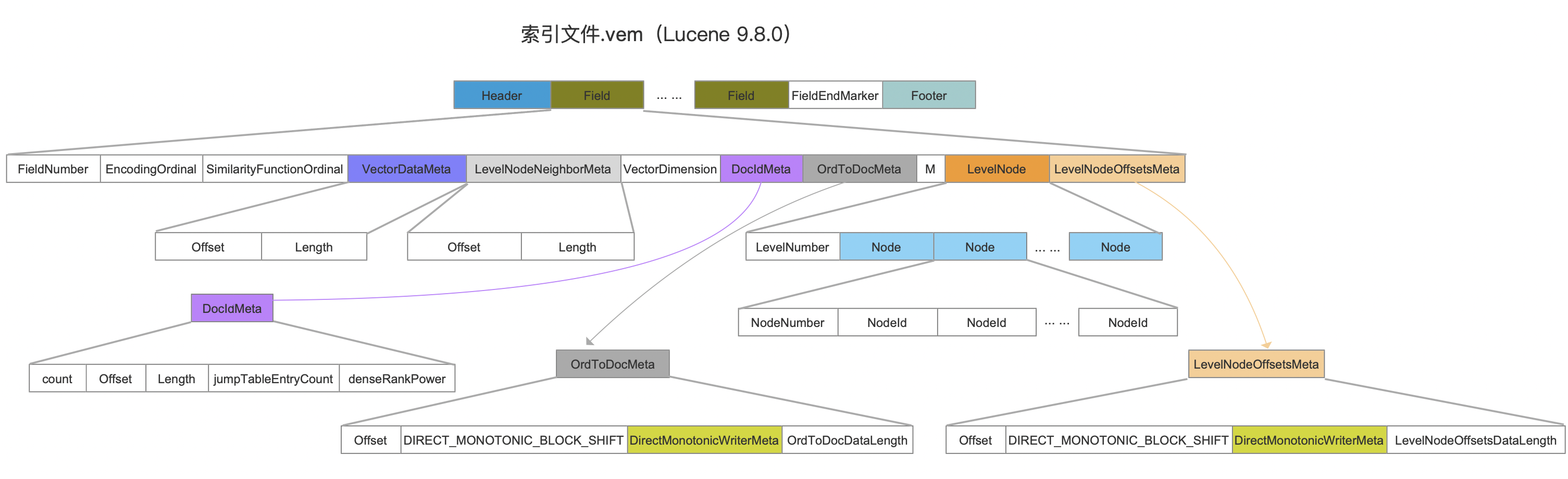
点击查看大图
简易字段
图16:
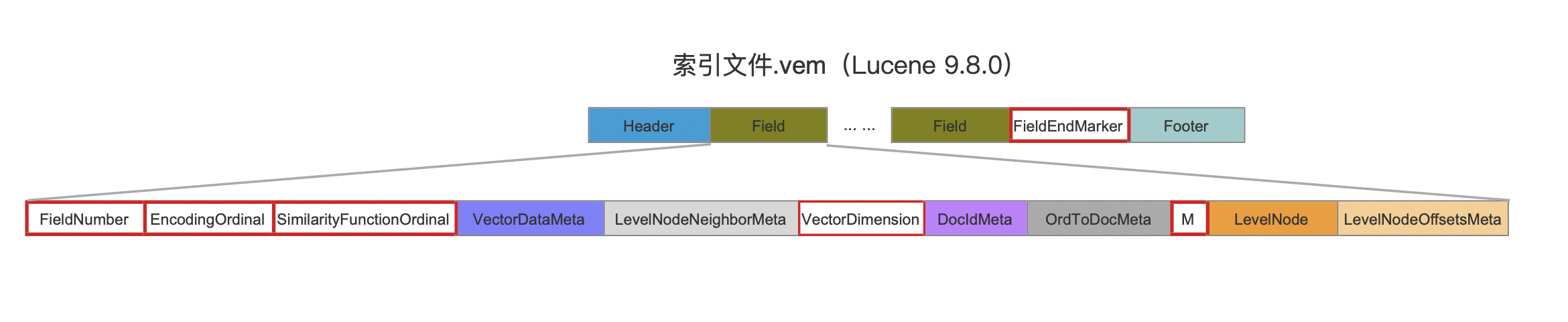
图16中红框标注的字段都属于简易字段:
- FieldNumber:域的编号
- EncodingOrdinal:向量值的数据类型,可以用8bit或者32bit表示一个数值
- SimilarityFunctionOrdinal:向量相似度函数。用来计算两个节点之间的距离。目前支持EUCLIDEAN(欧几里得/L2距离)、DOT_PRODUCT(点积或数量积)、COSINE(余弦相似度)、MAXIMUM_INNER_PRODUCT(最大内积)
- VectorDimension:向量的维度。例如图9中的向量维度位3。
- M:节点可以连接的邻居数量上限。第0层的节点可以连接的邻居数量上限为2M。
- FieldEndMarker:固定值-1。在索引读取阶段,会所有域的信息逐个字节读入到内存中,该字段作为一个标记,当读取到该值时,说明已经读取完所有的域的信息。
VectorDataMeta
图17:

向量值在索引文件.vec中的起始读取位置以及读取的长度。
LevelNodeNeighborMeta
图18:
邻居节点在索引文件.vex中的起始读取位置以及读取的长度。
DocIdMeta
图19:
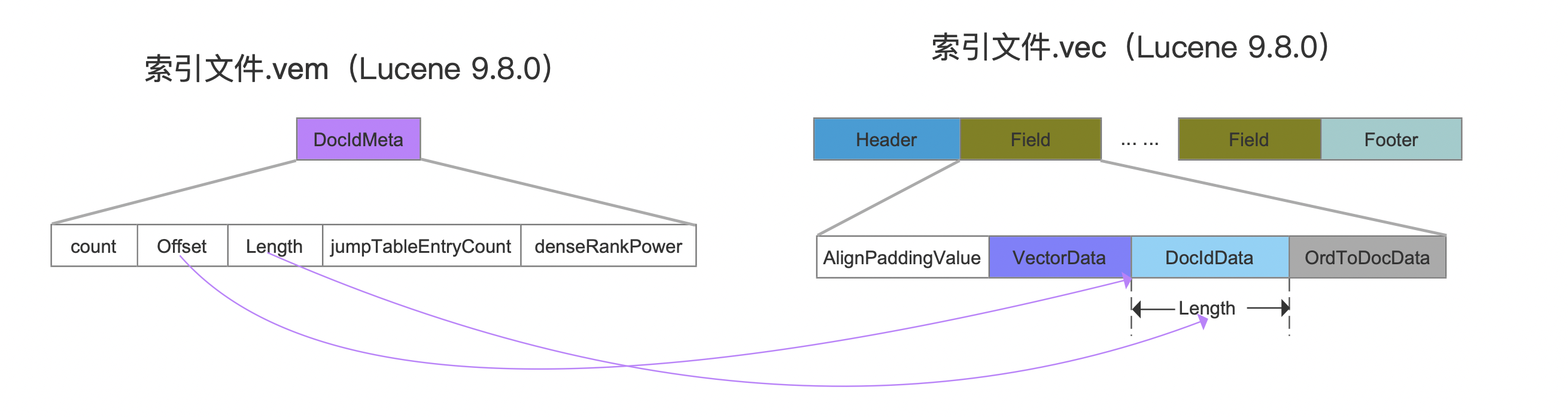
文档号信息在索引文件.vec中的起始读取位置以及读取长度,至于其他字段的描述见IndexedDISI。
OrdToDocMeta
图20:
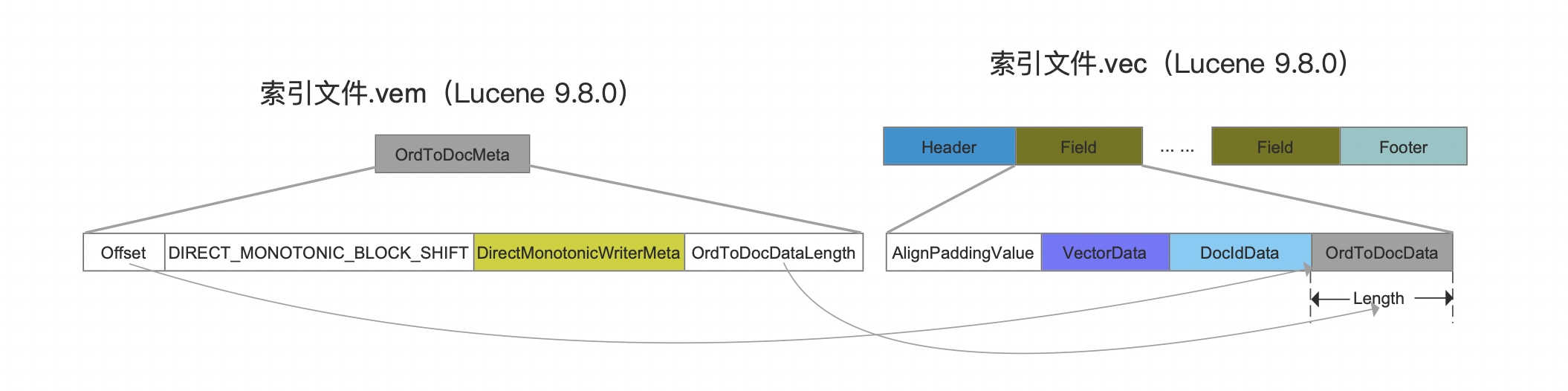
节点编号与文档号的映射关系在索引文件.vec中的起始读取位置(Offset)以及读取的长度(OrdToDocDataLength)。其他字段见DirectMonotonicWriter。
LevelNode
图21:
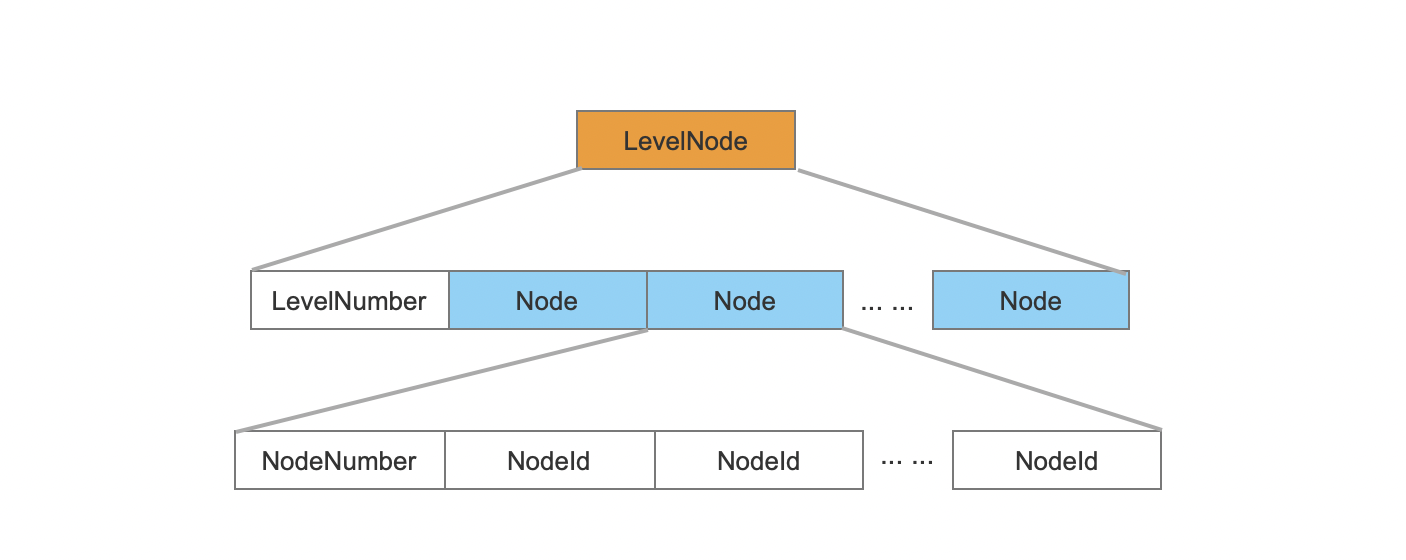
除了第0层外,其他层的的节点信息。
由于第0层中的节点数量是全量的节点,所以只需要根据从DocIdMeta读取出count字段,即文档的数量,那么第0层的节点编号区间为[0, count - 1]。而其他层的节点编号不是连续的,所以需要一个一个记录。
- LevelNumber:图中层的数量。
- Node:每一层(除了第0层)的节点编号信息
- NodeNumer:当前层中节点的数量
- NodeId:节点的编号
LevelNodeOffsetsMeta
图22:
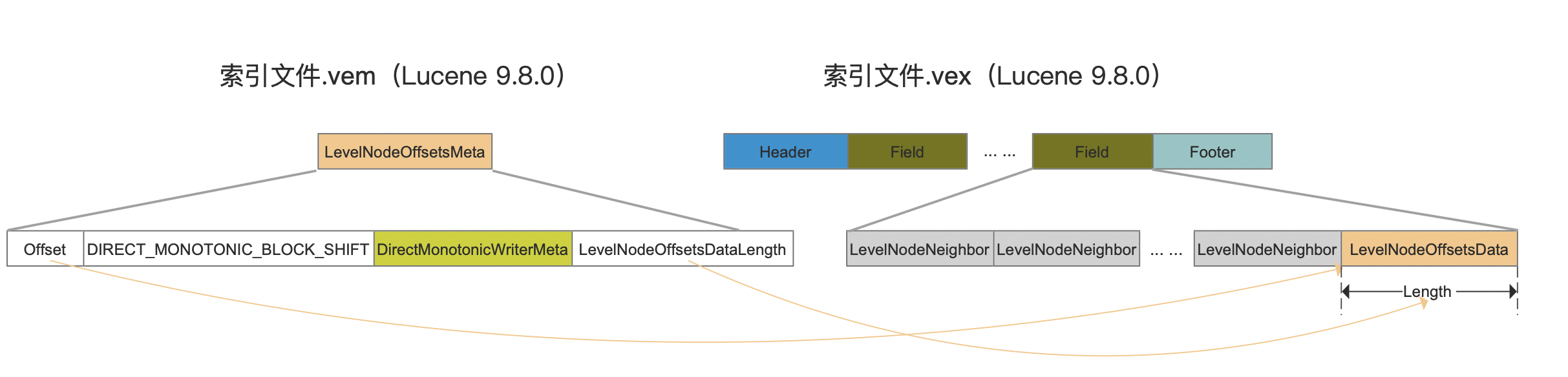
邻居节点位置信息在索引文件.vex中的起始读取位置(Offset)以及读取的长度(LevelNodeOffsetsDataLength)。其他字段见·DirectMonotonicWriter。