

从Lucene8.6.0开始,用于存储点数据(point value)的索引文件由原先的两个索引文件dim&&dii,改为三个索引文件kdd&kdi&kdm。由于生成kdd&kdi&kdm的过程基本上没有太大的变动,并且索引文件的数据结构中的字段也变化不大。故本文不会再详细介绍每一个字段的含义,即阅读本章前,最好先看下文章索引文件dim&&dii的数据结构,以及索引文件dim&&dii的生成过程以及索引文件dim&&dii的读取过程的系列文章,使得能理解优化的目的。当然在下文中,会结合一些issues来简单的叙述下优化的目的。
再次强调下,先阅读索引文件dim&&dii的生成过程以及索引文件dim&&dii的读取过程的系列文章,因为开始下笔写这篇文章的时候,我几乎忘光了之前写的这些东东,也就是相当于一片空白的重新复习了下这些系列文章, 发现看完后很容易的理解了(看来我的写作表达能力还阔以),哈哈😁。
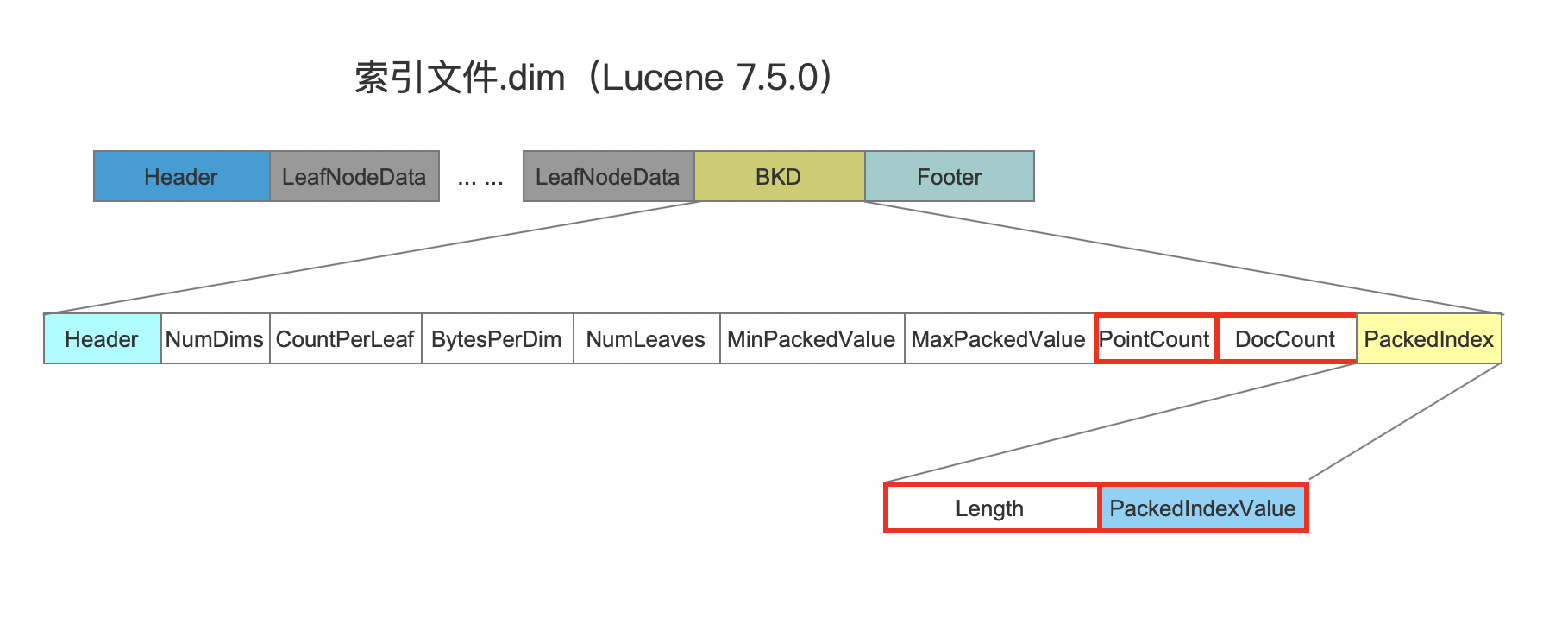
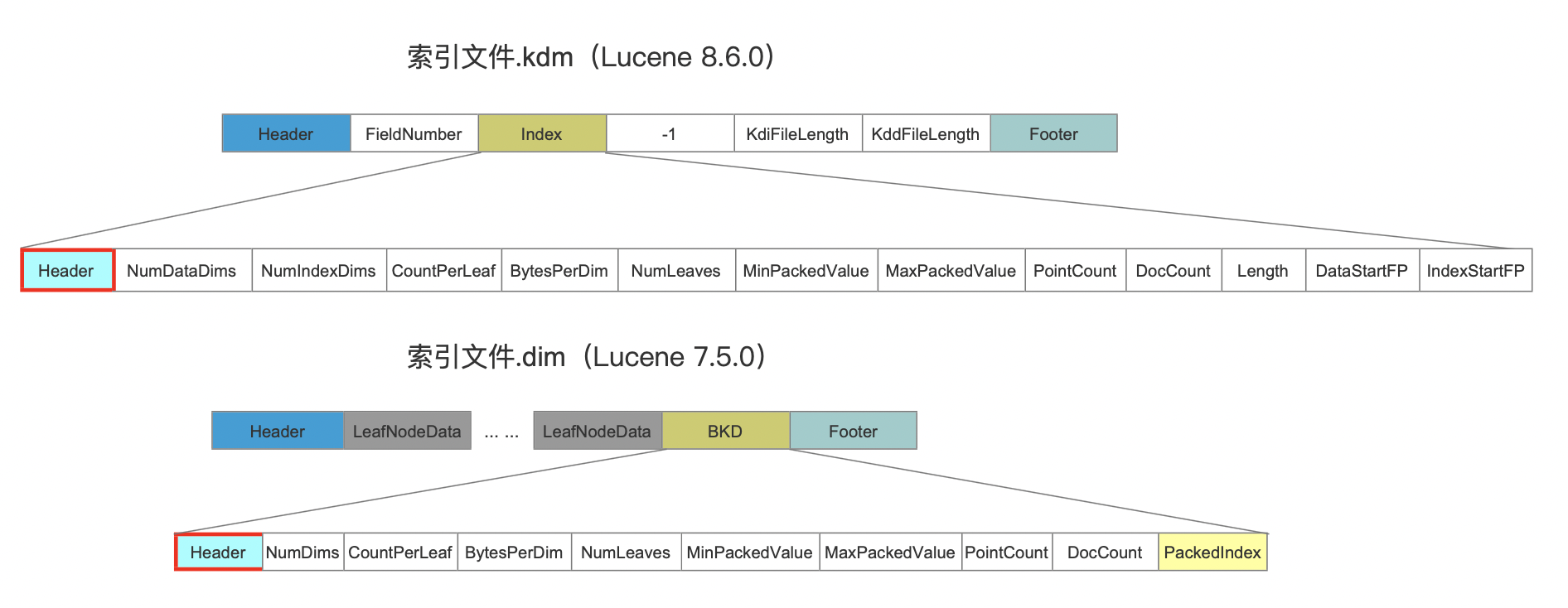
索引文件的数据结构
我们先直接分别给出单个点数据域、多个点数据域的数据结构:
单个点数据域的数据结构
图1:

多个点数据域的数据结构
图2:
源码中对于这三个索引文件的简单描述:
图3:

图3中红框标注.kdm应该是.kdd文件,可惜的是直到目前最新版本的Lucene 8.6.3,这里的书写错误依旧未被修正。
- 索引文件.kdm(meta)中存储的是元数据,即描述点数据域的数据的信息,例如点数据的维度、每个维度占用的字节数等等,这些元数据存储在图1的Index字段中,下文中会进一步介绍该字段。
- 索引文件.kdi(index)中存储的是内部节点的数据
- 索引文件.kdd(data)描述的是叶子节点的数据
点数据的信息使用了Bkd-tree的树形结构存储,可以阅读文章Bkd-Tree简单了解下bkd的概念。
为了便于介绍,我们以单个点数据域的数据结构来展开介绍。
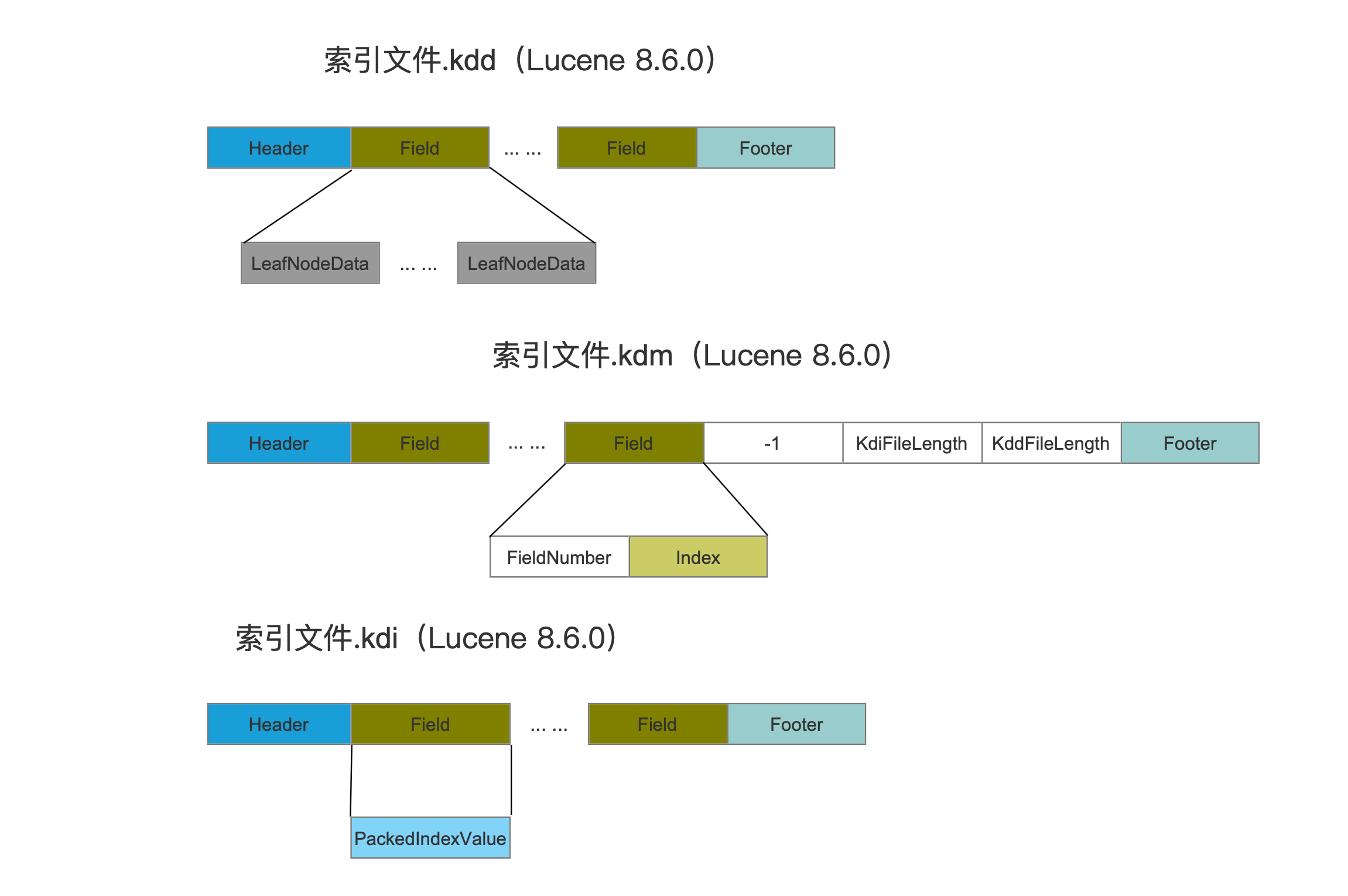
索引文件.kdd
图4:

索引文件.kdd中存储了叶子节点的数据,其中字段LeafNodeData中包含的内容跟索引文件.dim中的LeafNodeData是相同的,如下图所示,详细的字段介绍见文章索引文件dim&&dii,这里不赘述。
图5:

索引文件.kdi
图6:

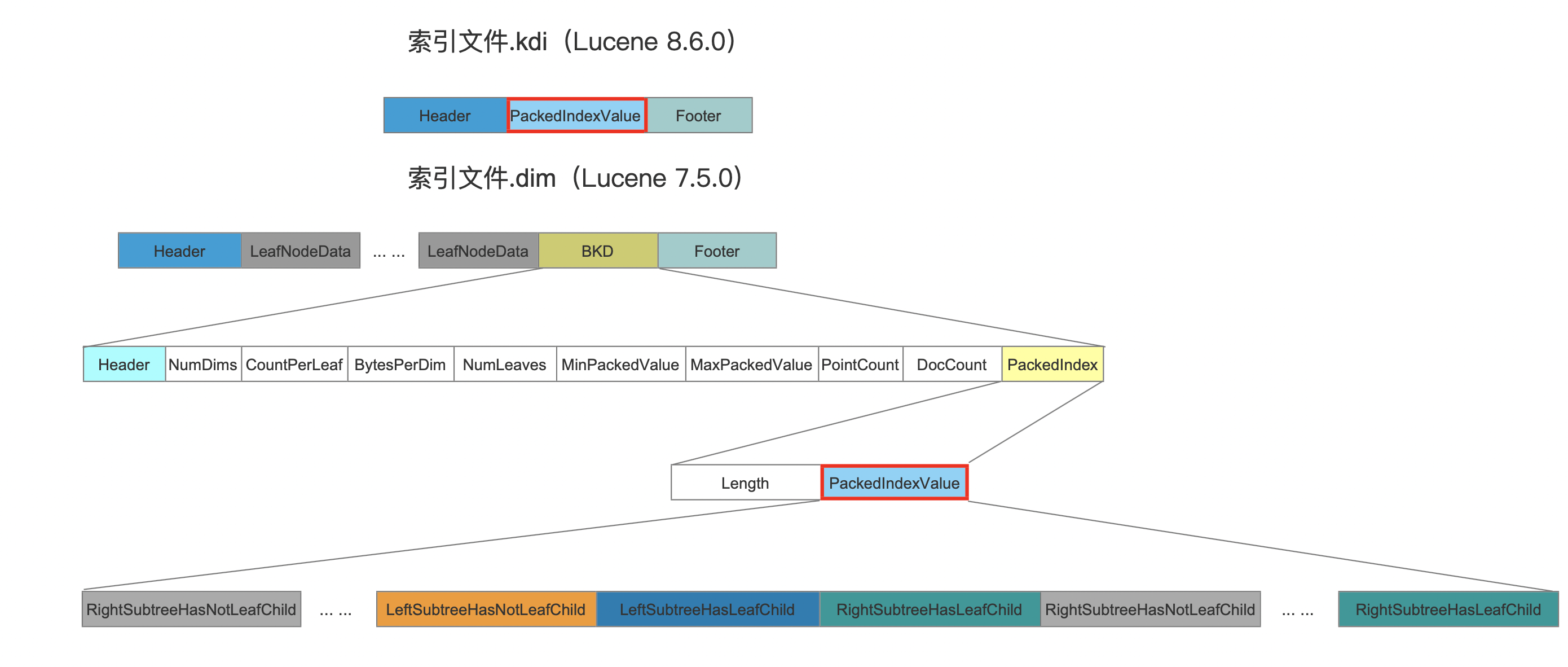
索引文件.kdi中存储了内部节点的数据,其中字段PackedIndexValue中包含的内容跟索引文件.dim中的PackedIndexValue是相同的,如下图所示,详细的字段介绍见文章索引文件dim&&dii,这里不赘述。
图7:
索引文件.kdm
图8:

索引文件.kdm中存储的是元数据,即描述点数据域的数据的信息,图8中,除了红框标注的几个字段,其他字段跟索引文件.dim中的BKD中的字段是相同的,如下图所示,详细的字段介绍见文章索引文件dim&&dii,这里不赘述。
图9:
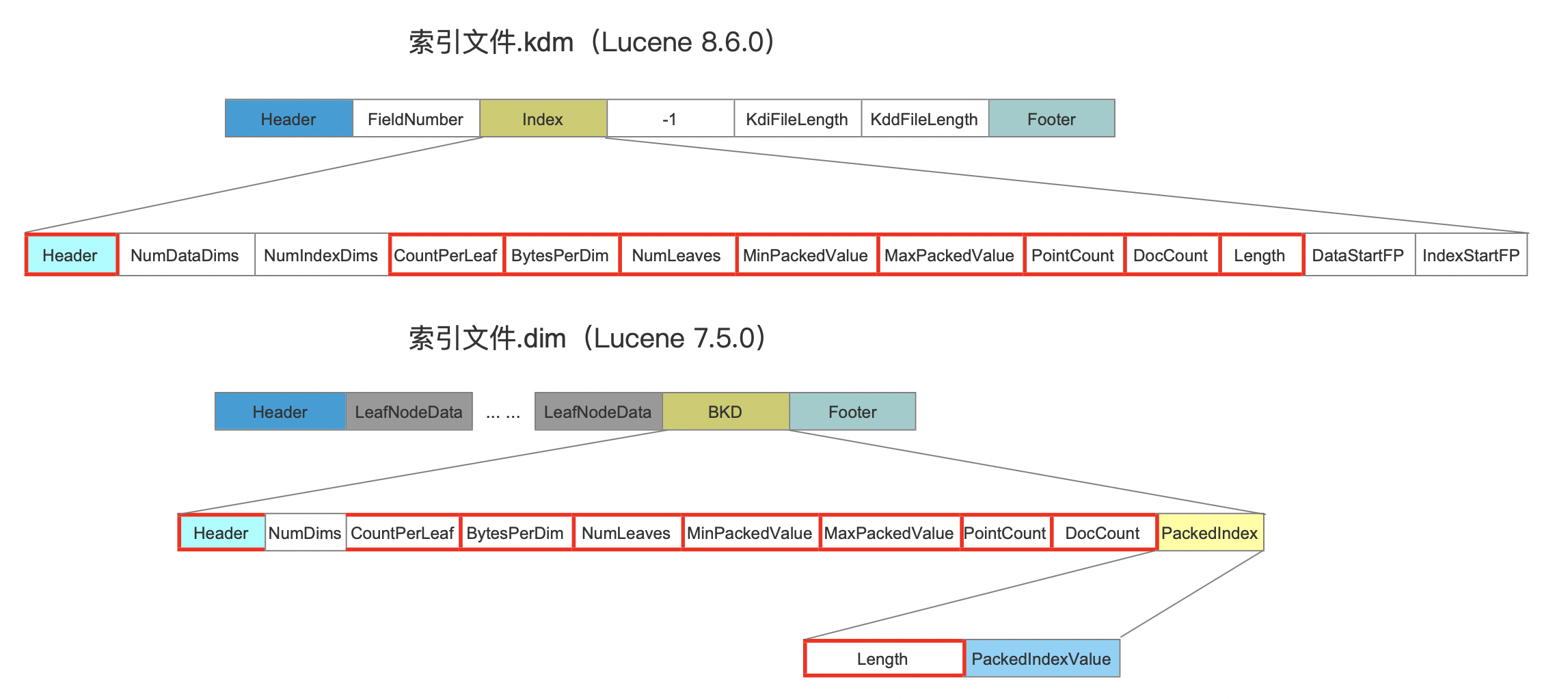
我们接着介绍图9中未被标注红框的字段。
numDataDims、numIndexDims
这两个字段分别描述了叶子节点、内部节点的点数据维度数。
FieldNumber
该字段描述的是域的编号,在Lucene 8.6.0之前,该字段存储在索引文件.dii中,如下所示:
图10:
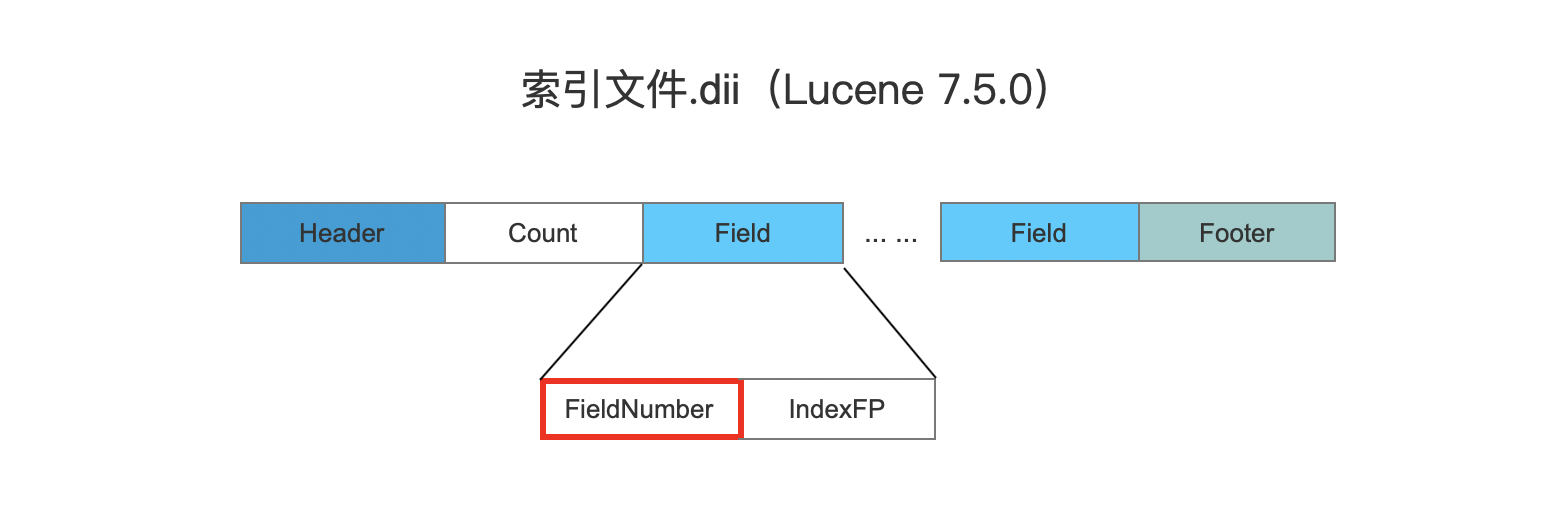
图10中,IndexFP字段用来指向图9中BKD的起始读取位置,该字段的作用相当于在Lucene8.6.0中的DataStartFP、IndexStartFP,见下文介绍。
-1
该字段会写入一个数值类型的固定值-1,在读取索引文件.kdm期间,它作为一个结束标志位用来描述所有域的FieldNumber跟Index字段信息已经被读取结束。
结合图2中多个点数据域的索引文件.kdm,由于每个域的FieldNumber、Index字段占用的字节数量是相同的,所以在读取阶段,只要按照固定的长度读取字节流即可,当读取到值为-1时,说明读取结束。这块内容在类Lucene86PointsReader初始化Reader时读取,由于代码比较简单,故直接给出:
图11:
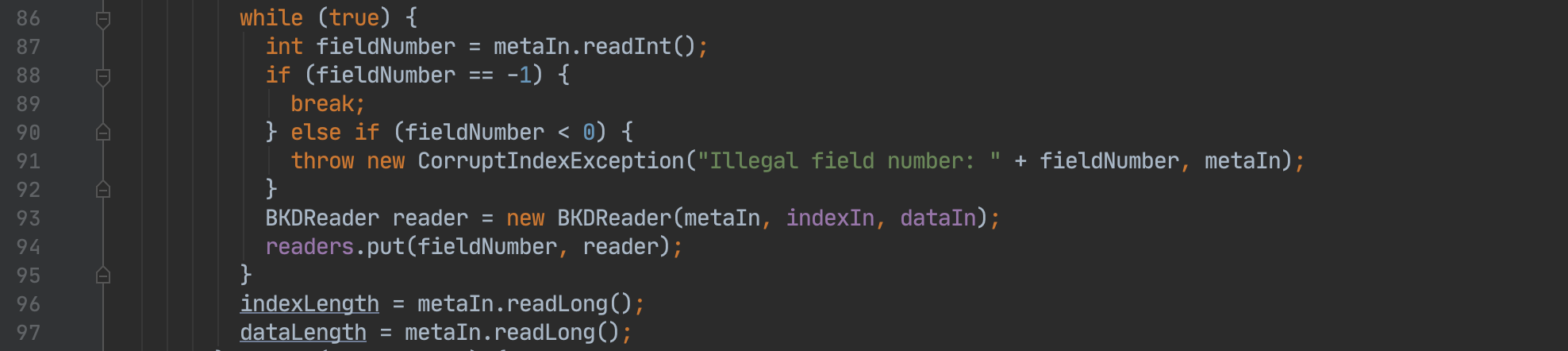
图11中,第87行代码会读取索引文件.kdm的FieldNumber字段;第93行代码将会读取Index字段,字段中的数据将用于生成BKDReader,下文中还会进一步展开;第88行代码会判断是否读取了-1字段,如果满足那么就跳出while循环,然后继续执行第96、97行的代码,即分别读取索引文件.kdm中的KdiFileLength、KddFileLength字段。
KdiFileLength、KddFileLength
这两个字段分别描述了索引文件.kdi、索引文件.kdd的文件长度,在读取阶段通过长度来检查这两个文件是否为合法的。同样的,检查的代码也相对简单,故直接给出:
图12:

KdiFileLength、KddFileLength的值将作为参数expectedLength传入到图12的方法中,其中in.length()方法描述了某个索引文件的长度,通过in.length()跟expectedLength的长度比较,判断索引文件是否合法的。
DataStartFP、IndexStartFP
这两个字段分别描述了某个点数据域的叶子节点、内部节点数据在索引文件.kdd、kdi中起始读取位置:
图13:

优化目的
通过上文介绍大家可能会发现,用于存储点数据的索引文件在Lucene8.6.0中的主要变动就是将内部节点跟叶子节点的信息从索引文件.dim中进行了分离,这里做的目的是出于什么考虑呢?作者的详细解释见原文地址:https://issues.apache.org/jira/browse/LUCENE-9148 。
其优化的目的主要有以下两点:
- 可以让用户充分利用MmapDirectory的preload功能,使得可以将叶子节点、内部节点的数据提前载入到内存,提高读取性能,在 Lucene8.4.0~Lucene 8.6.0这个版本区间,使用了off-heap机制载入图7中的PackedIndexValue字段的值,使得在搜索阶段才根据某个点数据域载入所属PackedIndexValue字段,并且内部节点跟叶子节点的数据都在同一个索引文件.dim中。
- 更好的检查索引文件的合法性,在优化之前只能通过检查Footer来判断,关于索引文件的合法性的检查在后面的文章会展开。
off-heap
对于off-heap在点数据域中的使用,可以分为三个阶段,另外下文中代码读取的索引文件为.dim或者.kdm:
不使用off-heap
在Lucene 8.4.0之前,不使用off-heap机制,即在生成DirectoryReader阶段,会把所有段中的所有点数据域的PackedIndexValue(图7中索引文件.dim的PackedIndexValue)读取到内存中。
图14:
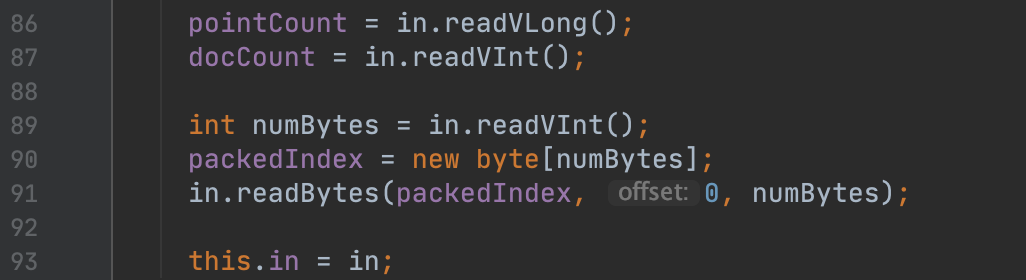
图15:
在图14中,第86、87、89行代码分别读取了索引文件.dim中的pointCount、DocCount、Length字段,随后根据Length字段的值,往后读取Length个字节的数据,即PackedIndexValue字段的全量数据,并且最后写入到字节数组packedIndex。
off-heap参数化
在Lucene 8.4.0~Lucene 8.6.0的版本期间,参数化选择是否使用off-heap:
图16:
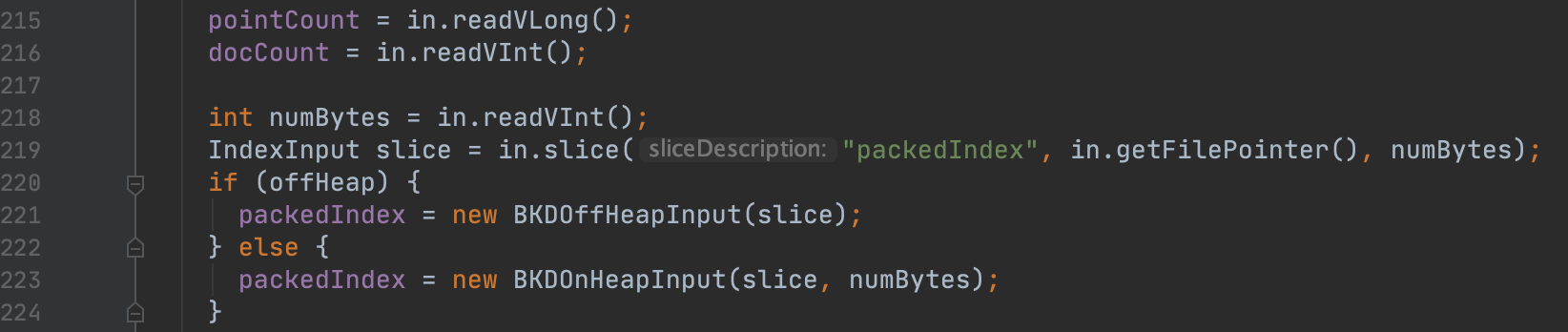
图16中,如果使用off-heap,那么会把文件指针指向图14的PackedIndexValue字段的起始读取位置,随后在搜索阶段,根据搜索条件中的点数据域,再读取出该域对应的PackedIndexValue的数据,否则在生成DirectoryReader阶段就将所有段中的所有点数据域的PackedIndexValue读取到内存中。
图16中第220行,使用offHeap取决于使用哪种Directory,例如使用MMapDirectory则会使用off-heap。
只使用off-heap
在Lucene 8.6.0的版本之后,直到目前最新版本的Lucene 8.6.3,总是使用off-heap:
图17:

图17中,代码第93行的if语句判断的是当前读取的点数据的索引文件的版本号,如果是Lucene 8.6.0以以上,那么按照图8的索引文件.kdm读取,否则按照图14的索引文件.dim读取,这里说明Lucene 8.6.0兼容低版本的点数据域对应的索引文件。
图17中,代码第97、99行读取的是Lucene8.6.0之前的索引文件,可以看出把文件指针指向了PackedIndexValue字段,但并没有读取。
由于PackedIndexValue的数据不在索引文件.kdm中,所以只能使用off-heap。
另外版本号通过Header字段获取,其包含的其他内容不是很重要,故省略,如下图红框标注:
图18:
结语
无
点击下载附件